调参专题

【机器学习 模型调参】GridSearchCV模型调参利器
导入模块sklearn.model_selection from sklearn.model_selection import GridSearchCV GridSearchCV 称为网格搜索交叉验证调参,它通过遍历传入的参数的所有排列组合,通过交叉验证的方式,返回所有参数组合下的评价指标得分,GridSearchCV 函数的参数详细解释如下: class sklearn.model_se

【干货】神经网络调参技巧大揭秘
神经网络调参技巧大揭秘 ——从过拟合到优化器选择的全面解析 参考文献: 深度学习调参有哪些技巧? - 爱睡觉的KKY的回答 - 知乎 https://www.zhihu.com/question/25097993/answer/2717281021 核心结论: 神经网络调参是一个既需要理论指导又需要实践经验的复杂过程。通过先过拟合再trade off、精细调整学习率(Learning

AI学习指南深度学习篇-门控循环单元的调参和优化
AI学习指南深度学习篇:门控循环单元的调参和优化 引言 神经网络在处理序列数据(如文本、时间序列等)方面展现出了强大的能力。门控循环单元(GRU)是循环神经网络(RNN)的一种变体,具有较为简单的结构和强大的性能。为了充分发挥GRU的潜力,调参和优化过程至关重要。本文将深入探讨GRU中的调参技巧、训练过程优化及避免过拟合的方法。 一、门控循环单元(GRU)简介 1.1 GRU的结构 GR
模型调参大法,让你的模型更进一步!
大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪 模型调参 首先需要牢记一个点:模型选型和数据质量决定了任务的底线,而调参只是锦上添花(也可能雪上加霜)的工作 所以优先考虑模型与数据,再考虑微调,能不调就不调。 模型与数据 任务 首先要明确任务是分类、回归、生成、排
streamlit之下使用optuna做多进程调参
☆ 问题描述 streamlit之下使用optuna做多进程调参 ★ 解决方案 import streamlit as stimport optunaimport multiprocessingimport time# 模拟一个简单的目标函数def objective(trial):x = trial.suggest_float('x', -10, 10)return (x - 2)
svm的核函数选择经验 调参经验
参考知乎:https://www.zhihu.com/question/21883548 以及CSDN帖子:https://blog.csdn.net/u014484783/article/details/78220646 具体的待研究。
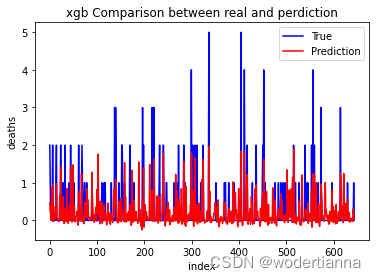
XGBoost预测及调参过程(+变量重要性)--血友病计数数据
所使用的数据是血友病数据,如有需要,可在主页资源处获取,数据信息如下: 读取数据及数据集区分 数据预处理及区分数据集代码如下(详细预处理说明见上篇文章--随机森林): import pandas as pdimport numpy as nphemophilia = pd.read_csv('D:/my_files/data.csv') #读取数据

DeepSORT(目标跟踪算法)中的数值表格与调参的关系
DeepSORT(目标跟踪算法)中的数值表格与调参的关系 flyfish DeepSORT(目标跟踪算法)中的马氏距离详解(很详细) DeepSORT(目标跟踪算法)中 可以设置阈值进行异常检测或目标跟踪的原因(写了重要步骤) 代码地址 https://github.com/shaoshengsong/DeepSORT 文字要是懒得看,直接拖到后面看图。 原始代码 Python版

keras池化层调参笔记
今天在调参的过程中,在调maxpooling时,发现了一个小技巧,假如对于一个维度为(None,20,500)的query_conv进行池化操作。 如果代码为 pool_query = MaxPooling1D(pool_size=20)(query_conv) 那么最终pool_query的最终维度为(None,1,500) 但是如果代码为 pool_query=MaxPooling
【python005】python批量、动态调参请求接口(已更新)
1.熟悉、梳理、总结项目研发实战中的Python开发日常使用中的问题。随着版本更新,做了一些变动,如商业化限制,取消一些语法等。 2.欢迎点赞、关注、批评、指正,互三走起来,小手动起来! 文章目录 1.背景介绍2.单次接口请求总结代码片3.批量循环接口请求总结代码片4.持久化`csv`文件合并4.参考链接 1.背景介绍 API接口批量请求限制API接口总量请求限制,一不

GBDT调参--贝叶斯调参
随机抽特征和随机抽样本 n_estimators 是控制森林中树木的数量,即基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越 大,模型的效果往往越好。但是相应的,任何模型都有决策边 n_estimators达到一定的程度之后,随机森林的 精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越
大模型LoRA微调调参的实战技巧
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍了大模型LoRA微调调参的实战技巧,希望对学习大语言模型的同学们有所帮

深度学习代码编写及调参经验
数据预处理好之后可以保存成pkl文件,这样后面多次运行程序的时候,可以直接加载。省的每次都要处理浪费时间tag2id 列完之后可以用一行代码转换成 id2tag: id2tag = {num: label for label, num in tag2id.items()}

深入理解神经网络学习率(定义、影响因素、常见调参方法、关键代码实现)
目录 什么是学习率? 有哪些影响因素? 常用调整方法? 博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦! 🍅文末三连哦🍅 👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟 一、什么
Rpackage【caret】自动参数调参的R包无法正常安装使用解决方法
1、下载最新的R版本 https://cran.r-project.org/mirrors.html 2、通过在Rstudio上调用不同的R换到最新版本的R 3、安装【lattice、ggplot2、plyr、cluster、foreach、reshape2】包再安装caret包即可
move_base 调参记录(局部使用teb算法)
个人做实验时move_base的调参记录 文章目录 local_costmap_params.yaml1、width: height: base_global_planner_params.yaml1、use_grid_path:2、use_quadratic: teb_local_planner_params.yaml1、max_vel_x: 3.02、xy_goal_tolera

数据挖掘入门项目二手交易车价格预测之建模调参
文章目录 目标步骤1. 调整数据类型,减少数据在内存中占用的空间2. 使用线性回归来简单建模3. 五折交叉验证4. 模拟真实业务情况5. 绘制学习率曲线与验证曲线6. 嵌入式特征选择6. 非线性模型7. 模型调参(1) 贪心调参(2)Grid Search 调参(3)贝叶斯调参 总结 本文数据集来自阿里天池:https://tianchi.aliyun.com/competit
深度强化学习调参技巧
在深度强化学习中,调参是一个非常重要的任务,它直接影响到模型的性能和收敛速度。下面是一些常用的深度强化学习调参技巧: 选择合适的环境和任务: 首先要确保选择的环境和任务适合深度强化学习。不同的环境和任务对算法的表现有着不同的要求,因此需要根据具体情况选择合适的环境和任务。 选择合适的算法: 根据任务的性质和特点选择合适的深度强化学习算法。例如,对于离散动作空间和状态空间的任务,可以选择DQN
PID算法调参经验分享
本篇文章旨在分享我对PID算法调节参数的经验,觉得掌握PID调参是一种十分重要的技能,在此记录一下。希望我的分享对你有所帮助。有关PID的一些文章,可以参考以下文章。 PID算法参数调节经验分享-CSDN博客 PID算法详解(代码详解篇),位置式PID、增量式PID(通用)_pid代码-CSDN博客 PID算法详解(精华知识汇总)-CSDN博客 目录 一、PID调试一般原则 二、P
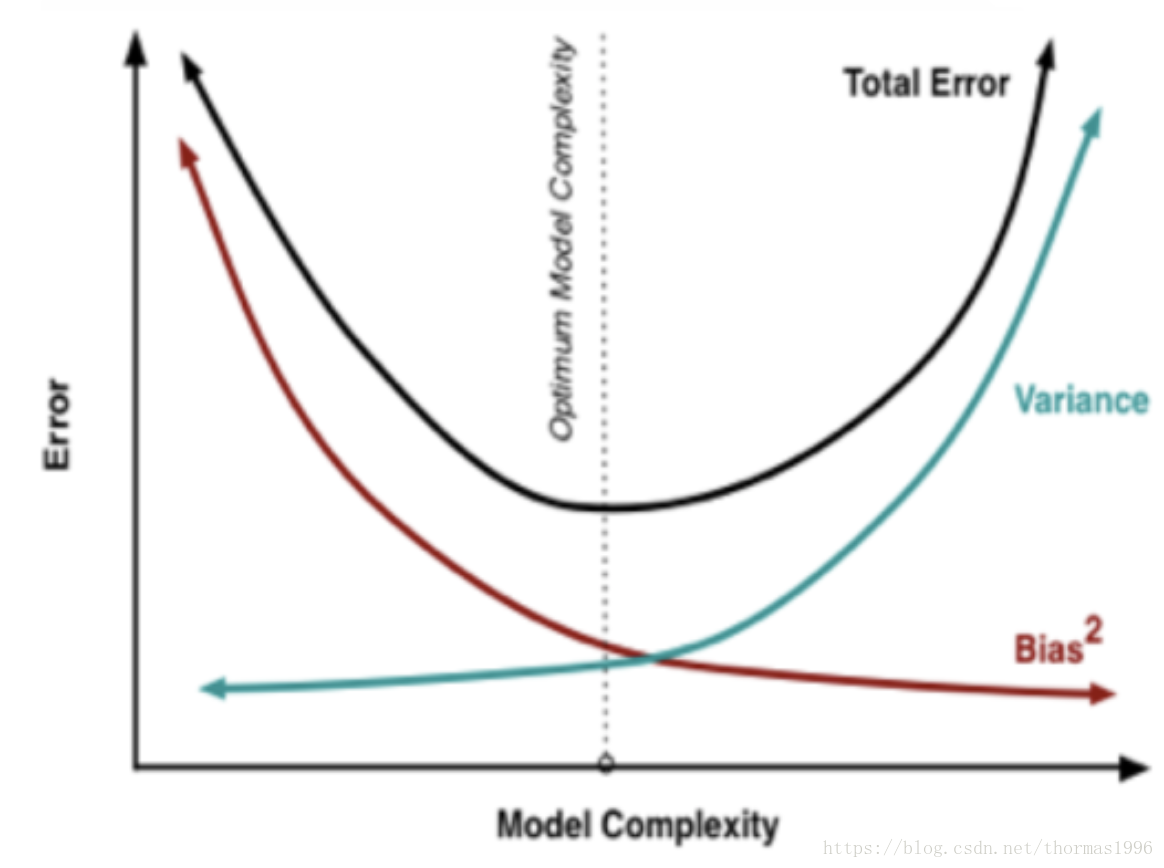
机器学习 算法总结(二) 调参技巧
偏差和方差 在统计学习框架下,Error = Bias + Variance。Error指的模型的预测错误率,由两部分组成,一部分是由于模型太简单而带来的估计不准确的部分(Bias),另一部分是由于模型太复杂而带来的更大的变化空间和不确定性(Variance)。如果要降低模型的Bias,就一定程度上会提高模型的Variance,反之亦然。根本原因是如果我们更相信训练数据的真实性,忽视对模型的先验
调参笔记:神经网络收敛问题
最近网络一直有收敛的问题,怀疑是梯度在训练的时候爆炸或归零导致分类器对evaluate集全0或全1预测。 第一个问题是出现accuracy固定在baseline上,无法提高 原因: tf的share embedding column函数learning rate不合适 将learning rate反复尝试并去掉share embedding column层改用加一层dense layer作为
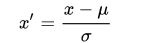
![[调参]CV炼丹技巧/经验](https://img-blog.csdnimg.cn/20181221165743991)
[调参]CV炼丹技巧/经验
转自:https://www.zhihu.com/question/25097993 我和@杨军类似, 也是半路出家. 现在的工作内容主要就是使用CNN做CV任务. 干调参这种活也有两年时间了. 我的回答可能更多的还是侧重工业应用, 技术上只限制在CNN这块. 先说下我的观点, 调参就是trial-and-error. 没有其他捷径可以走. 唯一的区别是有些人盲目的尝试, 有些人思考后再尝试.