本文主要是介绍机器学习 算法总结(二) 调参技巧,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
偏差和方差
- 在统计学习框架下,Error = Bias + Variance。Error指的模型的预测错误率,由两部分组成,一部分是由于模型太简单而带来的估计不准确的部分(Bias),另一部分是由于模型太复杂而带来的更大的变化空间和不确定性(Variance)。
- 如果要降低模型的Bias,就一定程度上会提高模型的Variance,反之亦然。根本原因是如果我们更相信训练数据的真实性,忽视对模型的先验知识,就会保证模型在训练样本上的准确度,这样可以减少模型的Bias,但这样会使模型的泛化能力不够,导致过拟合,降低模型在真实数据上的表现,增加模型的不确定性。反之,如果我们更注重模型的先验知识,在学习模型的过程中对模型增加更多的限制,就可以降低模型的variance,提高模型的稳定性,但也会使模型的Bias增大。
- 模型太简单:欠拟合;模型太复杂:过拟合。
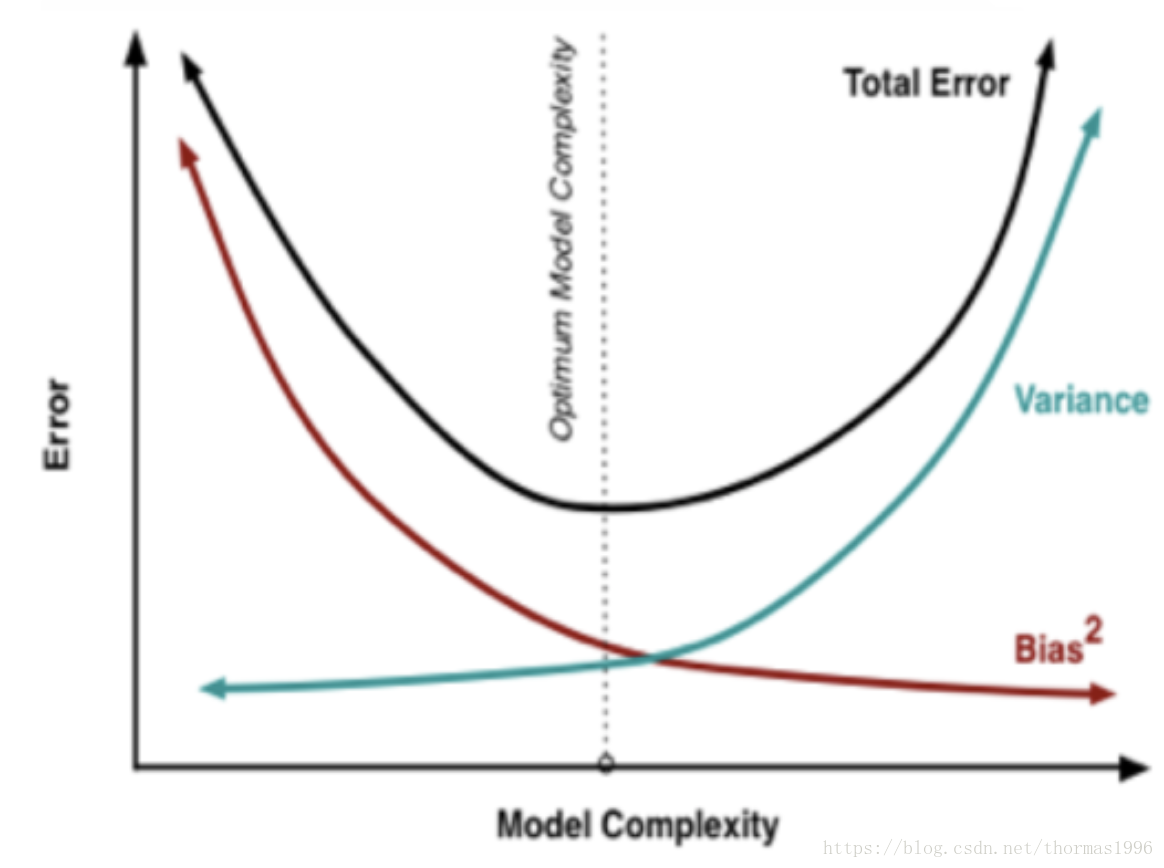
抑制欠拟合与过拟合方法
欠拟合主要是因为模型太简单,不能很好地捕捉模型特征。
- 添加其他特征项让模型学习
- 使模型更复杂,比如说对一个线性模型添加多项式特征等
- 减少正则化参数
过拟合主要是因为模型太复杂,过度拟合训练数据,或是训练数据太少,导致模型不能很好地学习到全局特征。
- 清洗数据,去掉outliner
- 扩大数据集,包括从数据源头采集更多数据,复制原有数据并加上随机噪声,重采样,根据当前数据集估计数据分布参数,使用该分布产生更多数据等方法
- Early stopping,当valid准确率不提高时适时停止
- 正则化,包括L0正则、L1正则和L2正则
- dropout
L1与L2正则化说明和区别
L0范数:向量中非0元素的个数。
L1范数(Lasso Regularization):
这篇关于机器学习 算法总结(二) 调参技巧的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







