本文主要是介绍使用DPO微调大模型Qwen2详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 事实上已成为 GPT-4 或 Claude 等 LLM 训练的最后一步,它可以确保语言模型的输出符合人类在闲聊或安全性等方面的期望。但传统的RLHF比较复杂,且还需要奖励模型,故DPO方法被提出,其将现有方法使用的基于强化学习的目标转换为可以通过简单的二元交叉熵损失直接优化的目标,这一做法大大简化了 LLM 的提纯过程。
且huggingface的trl库已经集成了dpo,使用起来非常方便。
本次以QWEN2(蹭热点),为例进行训练,分别介绍单轮对话的DPO和多轮对话的DPO,对应的数据集分别如下(均在huggingface):
- 单轮:lvwerra/stack-exchange-paired
- 多轮:trl-internal-testing/hh-rlhf-helpful-base-trl-style
通过DPO微调模型大概可以简单的分为两个步骤:
1、将数据处理成所需格式。
2、使用DPOTrainer进行训练
两种形式的dpo代码已集成至github上的大模型训练框架,并做了详细的使用解释及代码位置说明,可见:https://github.com/mst272/LLM-Dojo/tree/main/train_args/dpo
项目包括一个每个人都可以以此为基础构建自己的开源大模型训练框架流程、支持主流模型使用deepspeed进行Lora、Qlora、DPO等训练、主流模型的chat template模版、以及一些tricks的从零实现模块。欢迎大家star 共同学习!:
单轮对话构建DpoDataset
标准的DpoDataset数据集,最终的数据集对象应包含这3个条目。条目应命名为:
- prompt
- chosen
- rejected
官方示例
单轮官方示例如下:
dpo_dataset_dict = {"prompt": ["hello","how are you","What is your name?","What is your name?","Which is the best programming language?","Which is the best programming language?","Which is the best programming language?",],"chosen": ["hi nice to meet you","I am fine","My name is Mary","My name is Mary","Python","Python","Java",],"rejected": ["leave me alone","I am not fine","Whats it to you?","I dont have a name","Javascript","C++","C++",],
}
多轮示例为上述提到的数据集,大家可以大概看一下是长这个样子:
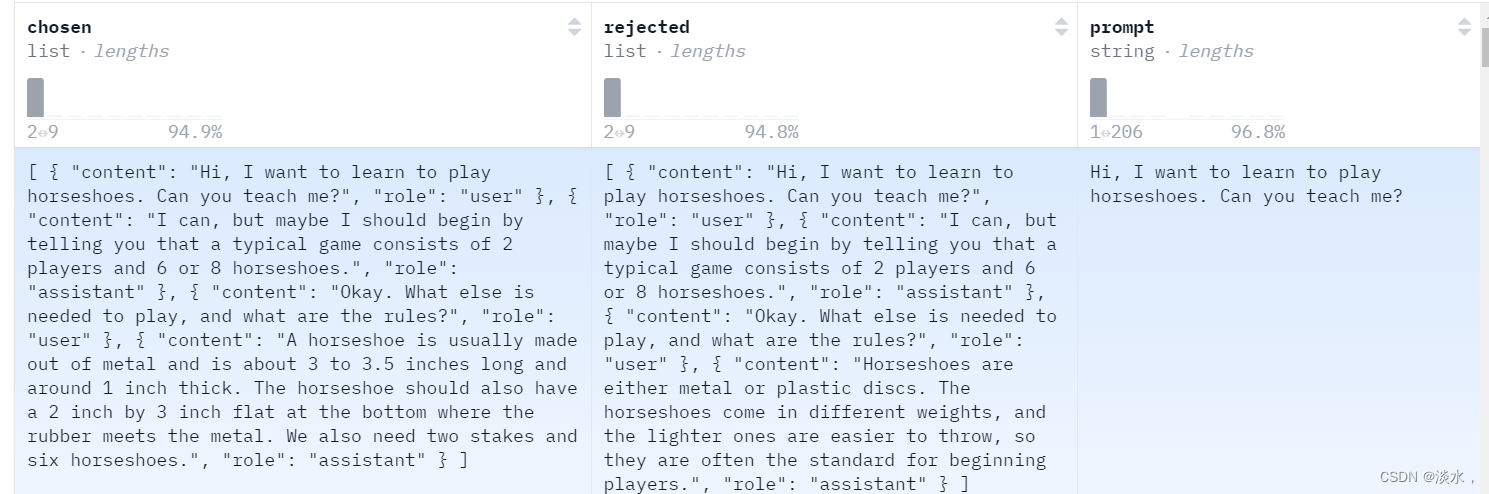
从头开始构建
比较简单的方式是套用官方给的示例,如下所示,只需要将数据集映射为上述我们提到的prompt、chosen、rejected格式,此时传递给DPOTrainer的数据是未编码之前的,DPOTrainer中会自动的给我们进行编码。注意下面并没有添加对应模型的chat template,根据不同模型的template可以在return_prompt_and_responses中自行添加即可。
def return_prompt_and_responses(samples) -> Dict[str, str, str]:return {"prompt": ["Question: " + question + "\n\nAnswer: "for question in samples["question"]],"chosen": samples["response_j"], # rated better than k"rejected": samples["response_k"], # rated worse than j}dataset = load_dataset("lvwerra/stack-exchange-paired",split="train",data_dir="data/rl"
)
original_columns = dataset.column_namesdataset.map(return_prompt_and_responses,batched=True,remove_columns=original_columns
)dpo_trainer = DPOTrainer(model, # 经 SFT 的基础模型model_ref, # 一般为经 SFT 的基础模型的一个拷贝beta=0.1, # DPO 的温度超参train_dataset=dataset, # 上文准备好的数据集tokenizer=tokenizer, # 分词器args=training_args, # 训练参数,如: batch size, 学习率等
)
为了便于我们理解数据处理细节及进行一些魔改操作,我们可以从头自己构建一个DpoDataset。
首先,深入DPOTrainer源码可以看到其数据处理操作主要是在tokenize_row函数,如下所示,
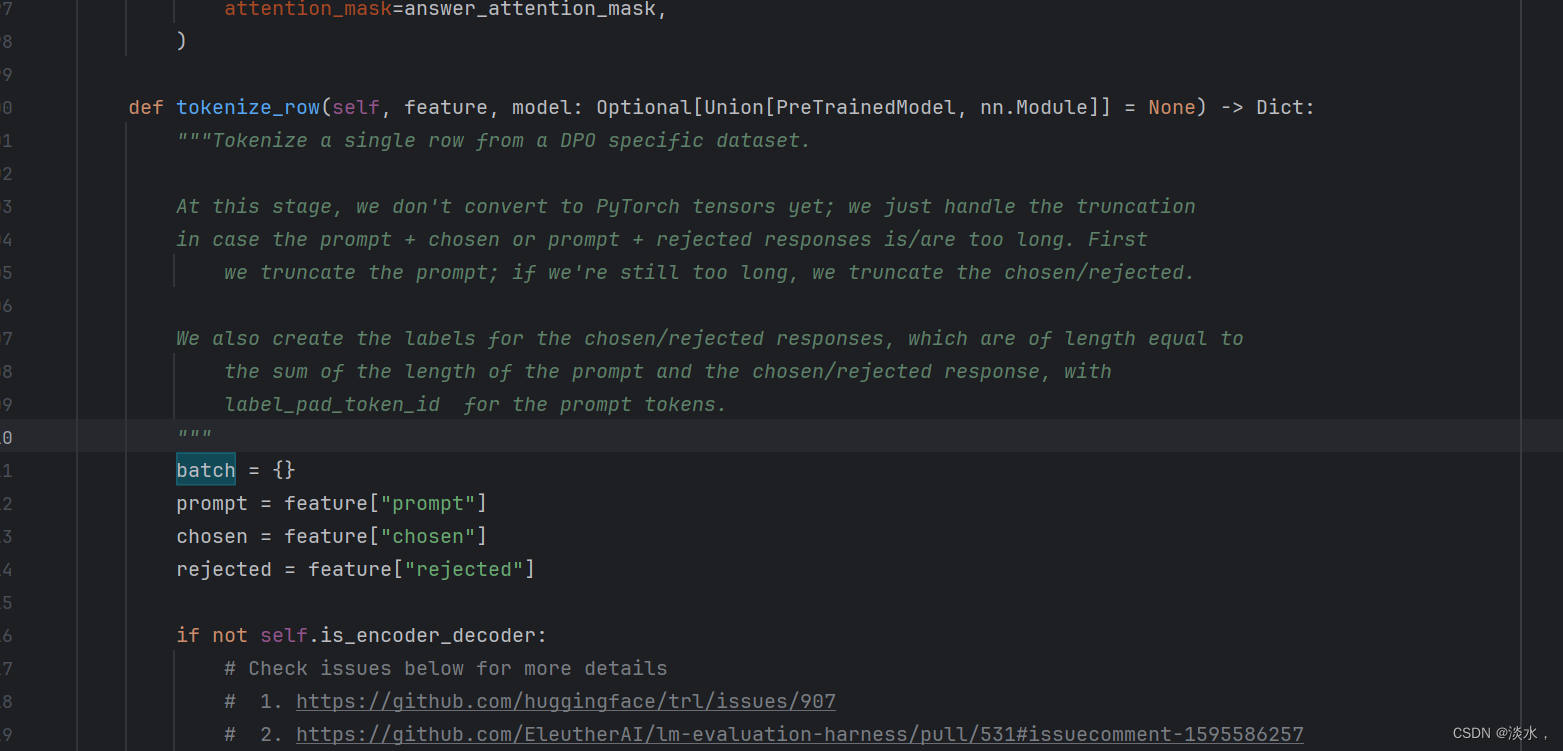
最终返回的是一个batch字典字段,代码部分如下所示:
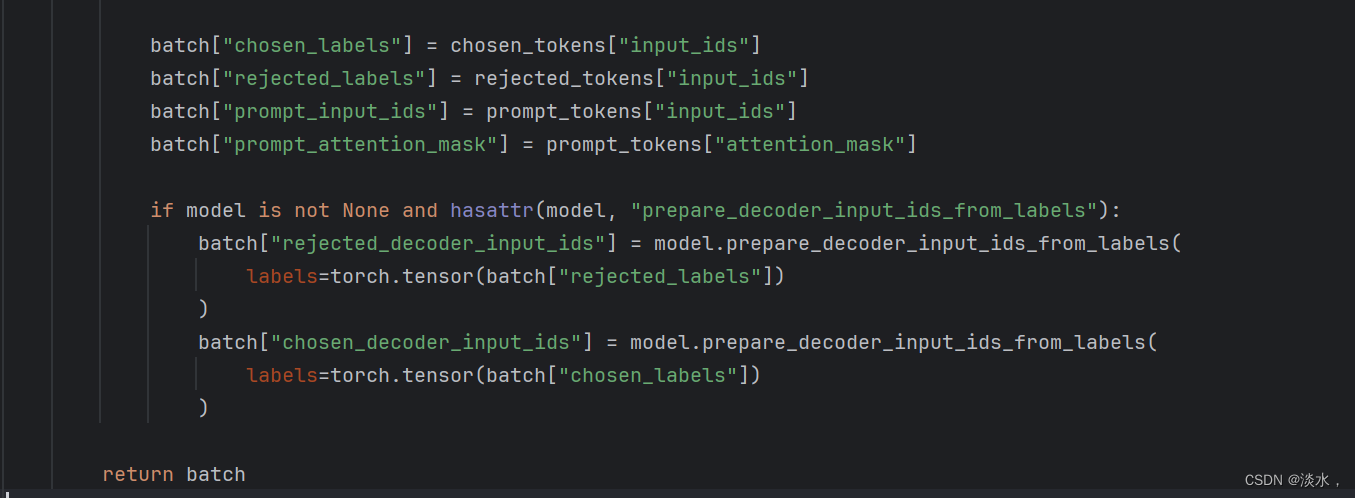

最终返回的字段为:
dict(prompt_input_ids,prompt_attention_mask,chosen_input_ids,chosen_attention_mask,chosen_labels,rejected_input_ids,rejected_attention_mask,rejected_labels,)
主要的__getitem__代码如下所示:
def __getitem__(self, item):data = self.data_list[item]data = json.loads(data) # 将json格式转换为python字典prompt = data['prompt']chosen = data['chosen']rejected = data['rejected']# 对prompt进行编码prompt = self.user_format.format(content=prompt, stop_token=self.tokenizer.eos_token)if self.system_format is not None:system = self.systemif system is not None:system_text = self.system_format.format(content=system)input_ids = self.tokenizer.encode(system_text, add_special_tokens=False)prompt_input_ids = input_ids + self.tokenizer.encode(prompt, add_special_tokens=False)else:prompt_input_ids = self.tokenizer.encode(prompt, add_special_tokens=False)# 进行回答的input id编码chosen = self.assistant_format.format(content=chosen, stop_token=self.tokenizer.eos_token)rejected = self.assistant_format.format(content=rejected, stop_token=self.tokenizer.eos_token)chosen_input_ids = self.tokenizer.encode(chosen, add_special_tokens=False)rejected_input_ids = self.tokenizer.encode(rejected, add_special_tokens=False)# 对最大长度进行截断longer_response_length = max(len(chosen_input_ids), len(rejected_input_ids))# keep end 对prompt截断if len(prompt_input_ids) + longer_response_length > self.max_seq_length:max_prompt_length = max(self.max_prompt_length, self.max_seq_length - longer_response_length)prompt_input_ids = prompt_input_ids[-max_prompt_length:]# 如果还不符合则回答截断if len(prompt_input_ids) + longer_response_length > self.max_seq_length:chosen_input_ids = chosen_input_ids[: self.max_seq_length - len(prompt_input_ids)]rejected_input_ids = rejected_input_ids[: self.max_seq_length - len(prompt_input_ids)]chosen_labels = [-100] * len(prompt_input_ids) + chosen_input_idschosen_input_ids = prompt_input_ids + chosen_input_idsrejected_labels = [-100] * len(prompt_input_ids) + rejected_input_idsrejected_input_ids = prompt_input_ids + rejected_input_idsassert len(chosen_labels) == len(chosen_input_ids)assert len(rejected_labels) == len(rejected_input_ids)inputs = dict(prompt_input_ids=prompt_input_ids,prompt_attention_mask=[1] * len(prompt_input_ids),chosen_input_ids=chosen_input_ids,chosen_attention_mask=[1] * len(chosen_input_ids),chosen_labels=chosen_labels,rejected_input_ids=rejected_input_ids,rejected_attention_mask=[1] * len(rejected_input_ids),rejected_labels=rejected_labels,)return inputs
适配DPOTrainer
构建完dataset后要适配DPOTrainer,可以看到其需要使用dataset进行一个map操作,这也就是DPOTrainer自动给我们处理数据的入口。
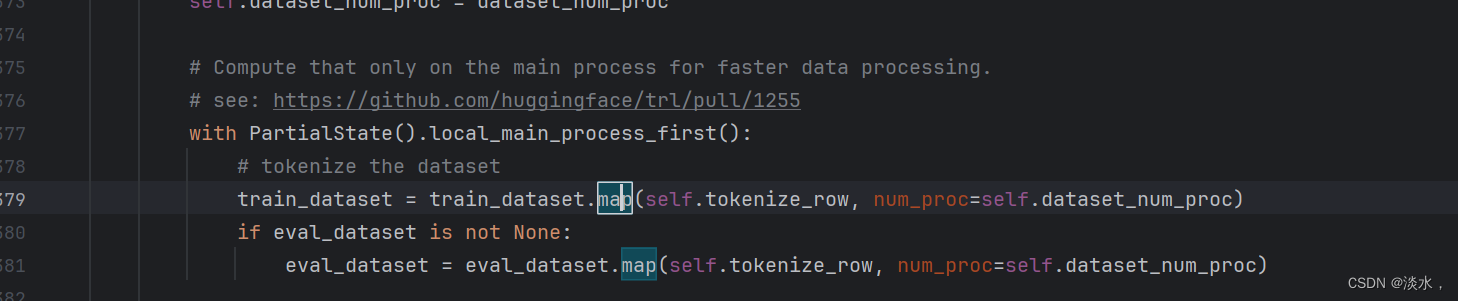
在我们自建的Dataset类中添加一个map函数映射会self即可:
def map(self, func, **kwargs):return self
多轮对话构建DpoDataset
多轮对话构建我们这里就不自己去写了,直接采用DPOTrainer中自带的数据处理即可。
部分代码如下所示:
if tokenizer.chat_template is None:tokenizer.chat_template = "{% for message in messages %}{{message['role'] + ': ' + message['content'] + '\n\n'}}{% endfor %}{{ eos_token }}"train_dataset = load_dataset(data_files=args.train_data_path, path='json')def process(row):row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)return rowtrain_dataset = train_dataset.map(process)train_dataset = train_dataset['train']return train_dataset
完整代码集成至github项目中,具体可参见:
开始Qwen2-8B 多轮和单轮DPO训练
使用DPOTrainer即可开始训练
trainer = DPOTrainer(model,ref_model=None,args=train_args,train_dataset=train_dataset,tokenizer=tokenizer,peft_config=peft_config)
dpo_trainer.train()
dpo_trainer.save_model()
总结
两种形式的dpo代码已集成至github上的大模型训练框架,并做了详细的使用解释及代码位置说明,可见:https://github.com/mst272/LLM-Dojo/tree/main/train_args/dpo
这篇关于使用DPO微调大模型Qwen2详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






