本文主要是介绍RLHF学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
整体流程
三个步骤分解:
- 预训练一个语言模型 (LM) ;
- 聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;
- 用强化学习 (RL) 方式微调 LM。


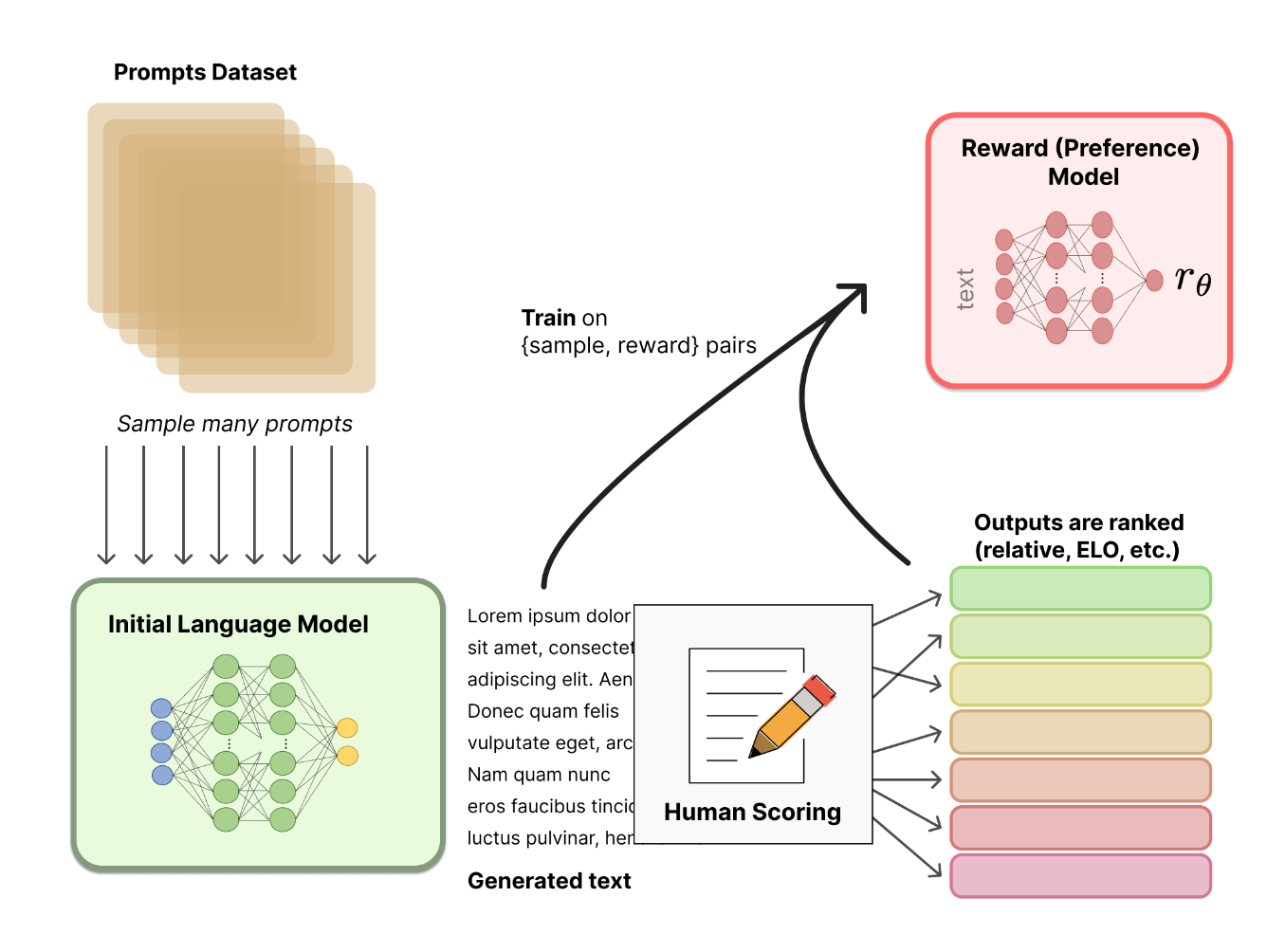
RW
RM 的训练是 RLHF 区别于旧范式的开端。这一模型接收一系列文本并返回一个标量奖励,数值上对应人的偏好。我们可以用端到端的方式用 LM 建模,或者用模块化的系统建模 (比如对输出进行排名,再将排名转换为奖励) 。这一奖励数值将对后续无缝接入现有的 RL 算法至关重要。
-
关于模型选择方面:
RM 可以是另一个经过微调的 LM,也可以是根据偏好数据从头开始训练的 LM。例如 Anthropic 提出了一种特殊的预训练方式,即用偏好模型预训练 (Preference Model Pretraining,PMP) 来替换一般预训练后的微调过程。因为前者被认为对样本数据的利用率更高。但对于哪种 RM 更好尚无定论。 -
过程:

-
Bradley-Terry(BT)模型是一个常见选择(在可以获得多个排序答案的情况下,Plackett-Luce 是更一般的排序模型)
-
**排序损失:**在最后一层 transformer 层后添加一个线性层以获得奖励值的标量预测。为了确保奖励函数具有较低的方差,之前的工作会对奖励进行归一化
RW代码
from dataclasses import dataclass, field
from typing import Optionalimport tyro
from accelerate import Accelerator
from datasets import load_dataset
from peft import LoraConfig
from tqdm import tqdm
from transformers import AutoModelForSequenceClassification, AutoTokenizer, BitsAndBytesConfigfrom trl import RewardConfig, RewardTrainer, is_xpu_availabletqdm.pandas()@dataclass
class ScriptArguments:model_name: str = "facebook/opt-350m""""the model name"""dataset_name: str = "Anthropic/hh-rlhf""""the dataset name"""dataset_text_field: str = "text""""the text field of the dataset"""eval_split: str = "none""""the dataset split to evaluate on; default to 'none' (no evaluation)"""load_in_8bit: bool = False"""load the model in 8 bits precision"""load_in_4bit: bool = False"""load the model in 4 bits precision"""trust_remote_code: bool = True"""Enable `trust_remote_code`"""reward_config: RewardConfig = field(default_factory=lambda: RewardConfig(output_dir="output",per_device_train_batch_size=64,num_train_epochs=1,gradient_accumulation_steps=16,gradient_checkpointing=True,gradient_checkpointing_kwargs={"use_reentrant": False},learning_rate=1.41e-5,report_to="tensorboard",remove_unused_columns=False,optim="adamw_torch",logging_steps=500,evaluation_strategy="no",max_length=512,))use_peft: bool = False"""whether to use peft"""peft_config: Optional[LoraConfig] = field(default_factory=lambda: LoraConfig(r=16,lora_alpha=16,bias="none",task_type="SEQ_CLS",modules_to_save=["scores"],),)args = tyro.cli(ScriptArguments)
args.reward_config.evaluation_strategy = "steps" if args.eval_split != "none" else "no"# Step 1: Load the model
if args.load_in_8bit and args.load_in_4bit:raise ValueError("You can't load the model in 8 bits and 4 bits at the same time")
elif args.load_in_8bit or args.load_in_4bit:quantization_config = BitsAndBytesConfig(load_in_8bit=args.load_in_8bit, load_in_4bit=args.load_in_4bit)# Copy the model to each devicedevice_map = ({"": f"xpu:{Accelerator().local_process_index}"}if is_xpu_available()else {"": Accelerator().local_process_index})
else:device_map = Nonequantization_config = Nonemodel = AutoModelForSequenceClassification.from_pretrained(args.model_name,quantization_config=quantization_config,device_map=device_map,trust_remote_code=args.trust_remote_code,num_labels=1,
)# Step 2: Load the dataset and pre-process it
tokenizer = AutoTokenizer.from_pretrained(args.model_name)
train_dataset = load_dataset(args.dataset_name, split="train")# Tokenize chosen/rejected pairs of inputs
# Adapt this section to your needs for custom datasets
def preprocess_function(examples):new_examples = {"input_ids_chosen": [],"attention_mask_chosen": [],"input_ids_rejected": [],"attention_mask_rejected": [],}for chosen, rejected in zip(examples["chosen"], examples["rejected"]):tokenized_chosen = tokenizer(chosen)tokenized_rejected = tokenizer(rejected)new_examples["input_ids_chosen"].append(tokenized_chosen["input_ids"])new_examples["attention_mask_chosen"].append(tokenized_chosen["attention_mask"])new_examples["input_ids_rejected"].append(tokenized_rejected["input_ids"])new_examples["attention_mask_rejected"].append(tokenized_rejected["attention_mask"])return new_examples# Preprocess the dataset and filter out examples that are longer than args.max_length
train_dataset = train_dataset.map(preprocess_function,batched=True,num_proc=4,
)
train_dataset = train_dataset.filter(lambda x: len(x["input_ids_chosen"]) <= args.reward_config.max_lengthand len(x["input_ids_rejected"]) <= args.reward_config.max_length
)if args.eval_split == "none":eval_dataset = None
else:eval_dataset = load_dataset(args.dataset_name, split=args.eval_split)eval_dataset = eval_dataset.map(preprocess_function,batched=True,num_proc=4,)eval_dataset = eval_dataset.filter(lambda x: len(x["input_ids_chosen"]) <= args.reward_config.max_lengthand len(x["input_ids_rejected"]) <= args.reward_config.max_length)# Step 4: Define the LoraConfig
if args.use_peft:peft_config = args.peft_config
else:peft_config = None# Step 5: Define the Trainer
trainer = RewardTrainer(model=model,tokenizer=tokenizer,args=args.reward_config,train_dataset=train_dataset,eval_dataset=eval_dataset,peft_config=peft_config,
)trainer.train()
RLHF
- 动手学强化学习: https://hrl.boyuai.com/chapter/2/actor-critic%E7%AE%97%E6%B3%95
让我们首先将微调任务表述为 RL 问题。
- 首先,该 策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。
- 这个策略的 行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级)
- 观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。
- 奖励函数 是偏好模型和策略转变约束 (Policy shift constraint) 的结合。

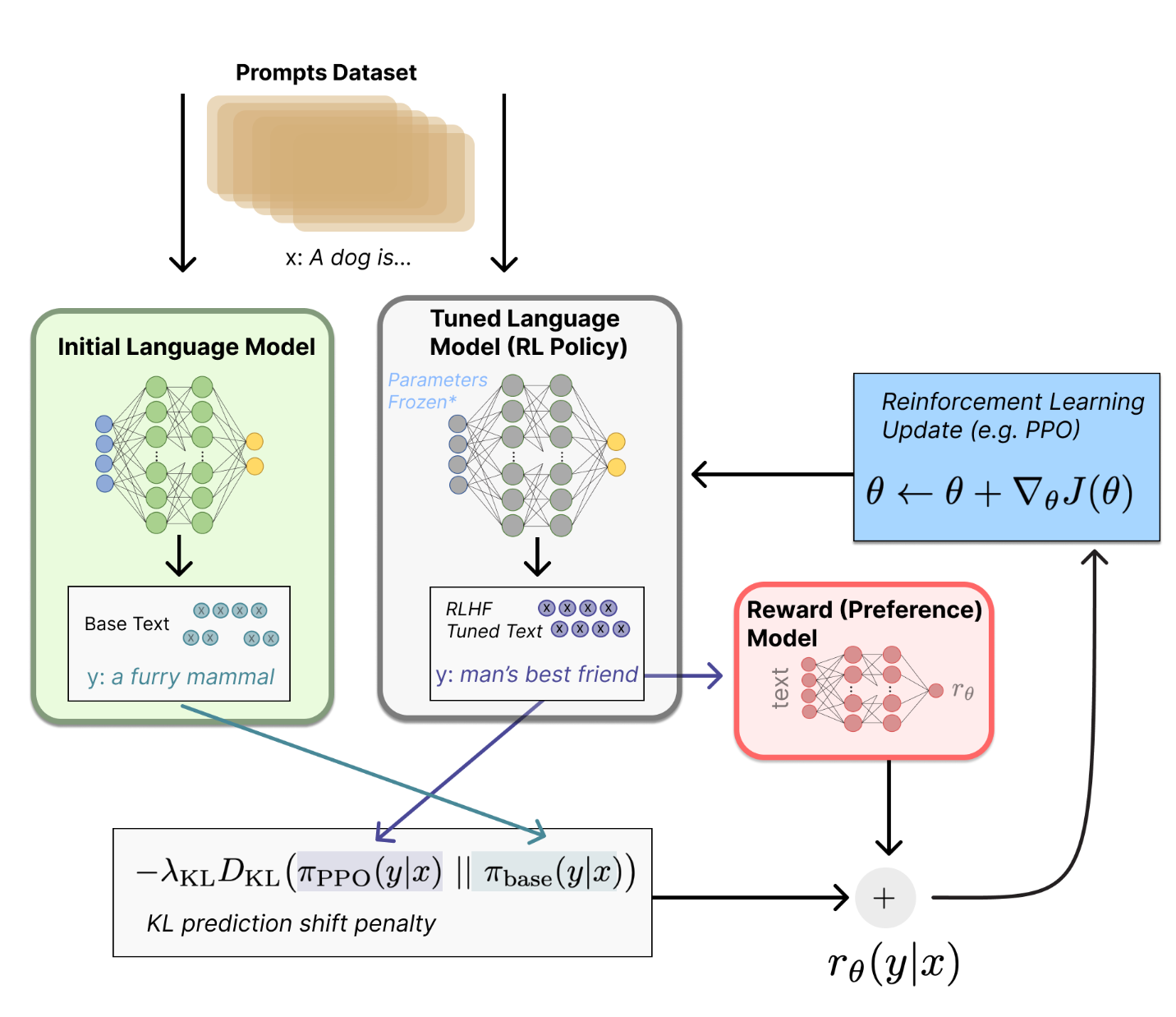
- KL散度这一项被用于惩罚 RL 策略在每个训练批次中生成大幅偏离初始模型,以确保模型输出合理连贯的文本。如果去掉这一惩罚项可能导致模型在优化中生成乱码文本来愚弄奖励模型提供高奖励值。
可视化进度条的一种方法:
with tqdm(total=int(num_episodes / 10), desc='Iteration %d' % i) as pbar:for i_episode in range(episode):if (i_episode + 1) % 10 == 0:pbar.set_postfix({'episode':'%d' % (num_episodes / 10 * i + i_episode + 1),'return':'%.3f' % np.mean(return_list[-10:])})pbar.update(1)
策略梯度
- 基于值函数的方法主要是学习值函数,然后根据值函数导出一个策略,学习过程中并不存在一个显式的策略;而基于策略的方法则是直接显式地学习一个目标策略。
AC算法
-
基于值函数的方法只学习一个价值函数,而基于策略的方法只学习一个策略函数
-
Actor-Critic 算法本质上是基于策略的算法,因为这一系列算法的目标都是优化一个带参数的策略,只是会额外学习价值函数,从而帮助策略函数更好地学习。
-
Actor-Critic 算法估计一个动作价值函数 Q Q Q,代替蒙特卡洛采样得到的回报,这便是 Q ( s , a ) Q(s,a) Q(s,a)。这个时候,我们可以把状态价值函数 V V V作为基线,从 Q Q Q函数减去这个 V V V函数则得到了函数 A A A,我们称之为优势函数(advantage function)
Actor-Critic 分为两个部分:Actor(策略网络)和 Critic(价值网络)
- Actor 要做的是与环境交互,并在 Critic 价值函数的指导下用策略梯度学习一个更好的策略。
- Critic 要做的是通过 Actor 与环境交互收集的数据学习一个价值函数,这个价值函数会用于判断在当前状态什么动作是好的,什么动作不是好的,进而帮助 Actor 进行策略更新。


PPO
PPO惩罚
PPO-惩罚(PPO-Penalty)用拉格朗日乘数法直接将 KL 散度的限制放进了目标函数中,这就变成了一个无约束的优化问题,在迭代的过程中不断更新 KL 散度前的系数。

PPO截断
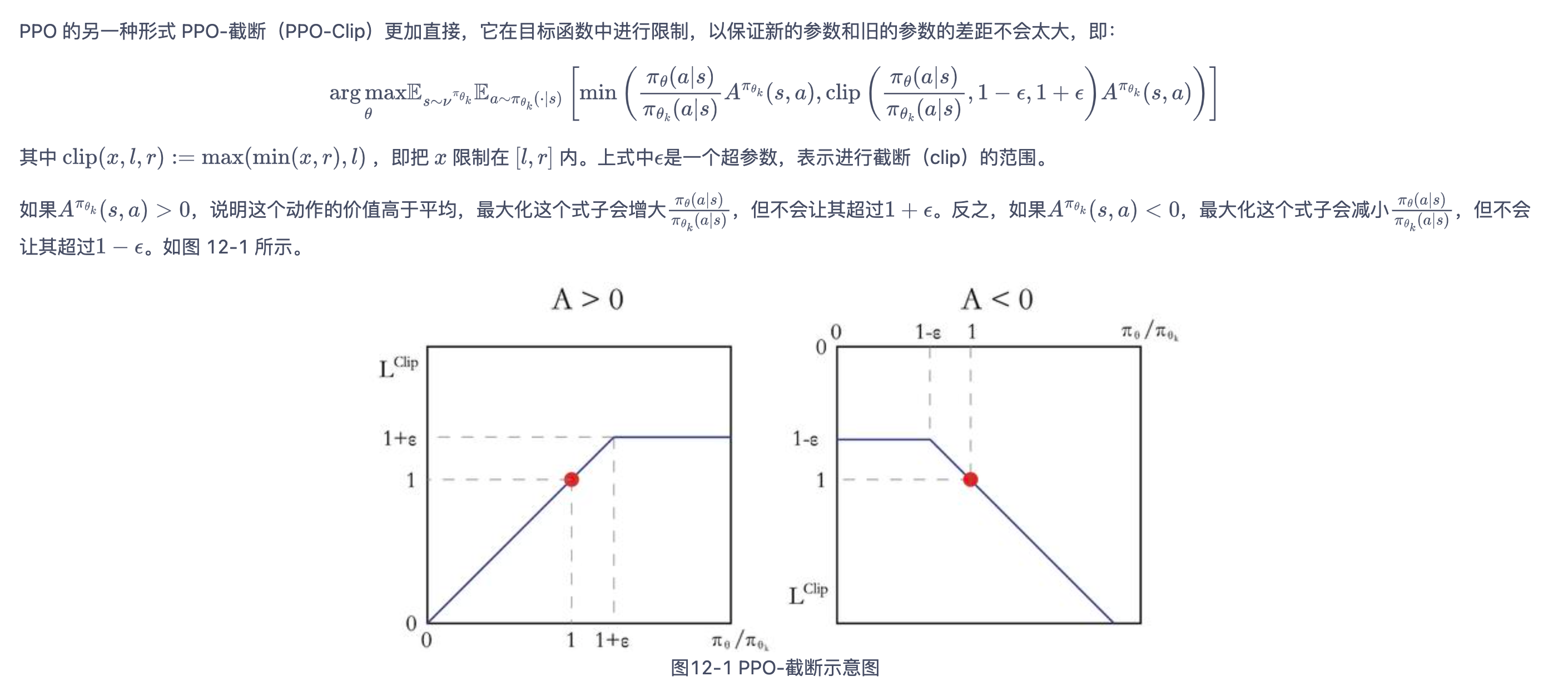
- 对于连续动作,让策略网络输出连续动作高斯分布(Gaussian distribution)的均值和标准差。后续的连续动作则在该高斯分布中采样得到。
PPO的训练中存在的问题
PPO会找捷径,只要有机会,PPO 算法就会利用这些缺陷。
-
显然,当从概率低于 SFT 模型的策略中采样令牌时,这将导致负 KL 惩罚。但平均而言,它将是正的,否则您将无法从策略中正确采样。使用 KL 惩罚项是为了推动模型的输出保持接近基本策略的输出。一般来说,KL 散度衡量两个分布之间的距离,并且始终为正值。
-
某些生成策略可以强制生成某些token或抑制某些token。例如,当批量生成完成的序列时,会进行填充;当设置最小长度时,EOS 令牌会被抑制。该模型可以为那些导致负 KL 的标记分配非常高或非常低的概率。当 PPO 算法针对奖励进行优化时,它会追逐这些负面惩罚,从而导致不稳定。
- 生成响应时需要小心,我们建议在采用更复杂的生成方法之前始终先使用简单的采样策略。
-
损失偶尔会出现峰值,这可能会导致进一步的不稳定。
-
字符串的重复会导致奖励的突然增加。
DPO
与以往的 RLHF 方法(先学习一个奖励函数,然后通过强化学习优化)不同,我们的方法跳过了奖励建模步骤,直接使用偏好数据优化语言模型。
- 我们的核心观点是利用从奖励函数到最优策略的解析映射,将对奖励函数的损失转化为对策略的损失。这种变量转换的方法使我们能够跳过显式的奖励建模步骤,同时仍然在现有的人类偏好模型(如 Bradley-Terry 模型)下进行优化。实质上,策略网络既代表语言模型,又代表奖励。


RLHF开源工具
- TRL
- RL4LM
TRL实践
- demo.py
# 0. imports
import torch
from transformers import GPT2Tokenizerfrom trl import AutoModelForCausalLMWithValueHead, PPOConfig, PPOTrainer# 1. load a pretrained model
model = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
model_ref = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token# 2. initialize trainer
ppo_config = {"batch_size": 1}
config = PPOConfig(**ppo_config)
ppo_trainer = PPOTrainer(config, model, model_ref, tokenizer)# 3. encode a query
query_txt = "This morning I went to the "
query_tensor = tokenizer.encode(query_txt, return_tensors="pt").to(model.pretrained_model.device)# 4. generate model response
generation_kwargs = {"min_length": -1,"top_k": 0.0,"top_p": 1.0,"do_sample": True,"pad_token_id": tokenizer.eos_token_id,"max_new_tokens": 20,
}
response_tensor = ppo_trainer.generate([item for item in query_tensor], return_prompt=False, **generation_kwargs)
response_txt = tokenizer.decode(response_tensor[0])# 5. define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0, device=model.pretrained_model.device)]# 6. train model with ppo
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
这篇关于RLHF学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








