本文主要是介绍人类偏好导向:DPO技术重塑SDXL-1.0图像生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
在AI领域,适应和理解人类偏好一直是技术发展的重要方向。斯坦福大学研究团队最近提出的Diffusion-DPO方法,旨在将这一理念应用于图像生成模型,特别是在文本到图像的转换领域。
-
Huggingface模型下载: https://huggingface.co/mhdang/
-
AI快站模型免费加速下载: https://aifasthub.com/models/mhdang/

技术创新
Diffusion-DPO方法基于直接偏好优化(Direct Preference Optimization)技术,这是一种相对于传统的基于人类反馈的强化学习(RLHF)的简化替代方案。它可以直接优化模型在分类目标下最能满足人类偏好的策略。通过这种方法,研究团队对图像生成模型进行了重大调整,以便更好地适应和反映人类偏好。

应用实例
实验中使用了名为Pick-a-Pic的数据集,包含851,000个成对偏好数据,来对Stable Diffusion XL (SDXL)-1.0模型进行微调。微调后的模型在人类评估中表现出色,尤其是在视觉吸引力和对文本提示的响应方面,超过了原始SDXL-1.0模型及其更大型版本。
技术优势
Diffusion-DPO技术之前主要应用于语言模型,而斯坦福大学研究团队的这一突破性应用,将其成功扩展到了图像生成模型中,特别是在文本到图像的转换上。这一技术的核心优势在于它的独特训练方法。传统的图像生成模型通常依赖于大量的数据和复杂的算法来优化性能,而Diffusion-DPO技术则通过模拟人类偏好来训练模型。这种方法不仅使模型能够更加贴近人类的审美和理解,而且提高了模型对于复杂和抽象文本提示的响应能力。使用DPO技术的模型在人类评估中表现出了卓越的性能,尤其在理解文本提示和视觉吸引力方面胜过了其他现有技术。这表明,通过直接优化模型以适应人类偏好,可以在不增加模型复杂度的同时提升其整体性能。

此外,这种方法还提高了模型在创建复杂图像元素方面的能力,例如在手部和眼神对齐方面的表现比以往任何模型都要准确。这在以前的模型中常常是一个挑战,因为这些细节需要精确的视觉理解和生成能力。这种新模型的实用性在于,即使未直接针对特定应用场景如图像编辑进行训练,也能展现出潜在的优势。这意味着模型可以在更广泛的场景中被应用,如艺术创作、广告设计和内容生成等,为这些领域带来更为丰富和准确的视觉内容。
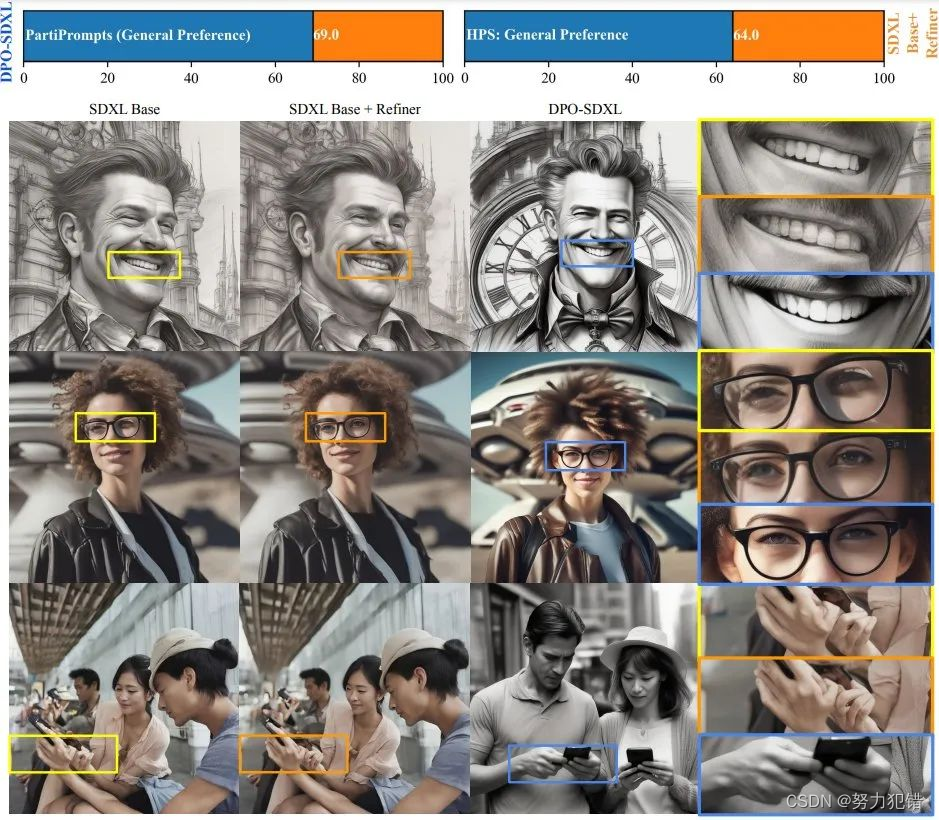
结论
Diffusion-DPO技术的引入,不仅是图像生成领域的一项重要进步,更在理论上对强化学习和人类反馈理论的理解与实践具有深远意义。它展示了通过直接对齐人类偏好来提高模型性能的潜力,为未来AI技术的发展提供了新的思路。
模型下载
Huggingface模型下载
https://huggingface.co/mhdang/
AI快站模型免费加速下载
https://aifasthub.com/models/mhdang/
这篇关于人类偏好导向:DPO技术重塑SDXL-1.0图像生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






