descent专题

AI学习指南深度学习篇-随机梯度下降法(Stochastic Gradient Descent,SGD)简介
AI学习指南深度学习篇-随机梯度下降法(Stochastic Gradient Descent,SGD)简介 在深度学习领域,优化算法是至关重要的一部分。其中,随机梯度下降法(Stochastic Gradient Descent,SGD)是最为常用且有效的优化算法之一。本篇将介绍SGD的背景和在深度学习中的重要性,解释SGD相对于传统梯度下降法的优势和适用场景,并提供详细的示例说明。 1.

神经网络算法 - 一文搞懂Gradient Descent(梯度下降)
本文将从梯度下降的本质、梯度下降的原理、梯度下降的算法 三个方面,带您一文搞懂梯度下降 Gradient Descent | GD。 梯度下降 机器学习“三板斧”:选择模型家族,定义损失函数量化预测误差,通过优化算法找到最小化损失的最优模型参数。 机器学习 vs 人类学习 定义一个函数集合(模型选择) 目标:确定一个合适的假设空间或模型家族。 示例:线性回归、逻辑回归、神
[deeplearning-001] stotisticks gradient descent随机梯度下降算法的最简单例子解释
1.gradient descent梯度下降优化 1.1假设要优化一个函数 f(x)=(x−1)2 f(x)=(x-1)^2求它的最小值。这个函数在 x=1 x=1 时有最小值,这是解析解。如果用梯度下降法,是这样的: f′(x)=2(x−1) f^{'}(x)=2(x-1) 每一步的迭代公式是: xi+1=xi−ηf′(xi) x_{i+1}=x_{i} - \eta f^{'}(x
梯度下降(Gradient Descent)原理以及Python代码
给定一个函数,我们想知道当是值是多少的时候使这个函数达到最小值。为了实现这个目标,我们可以使用梯度下降(Gradient Descent)进行近似求解。 梯度下降是一个迭代算法,具体地,下一次迭代令 是梯度,其中是学习率(learning rate),代表这一轮迭代使用多少负梯度进行更新。梯度下降非常简单有效,但是其中的原理是怎么样呢? 原理 为什么每次使用负梯度进行更新呢?这要从泰勒
![[Android] Android绘制文本基本概念之- top, bottom, ascent, descent, baseline](https://img-blog.csdn.net/20160826134143820)
[Android] Android绘制文本基本概念之- top, bottom, ascent, descent, baseline
介绍 通过一个图来了解一下这些概念: baseline是基线,在Android中绘制文本都是从baseline处开始的,从baseline往上至至文本最高处的距离称之为ascent(上坡度),baseline至文本最低处的距离称之为descent(下坡度)。 top和bottom是绘制文本时在最外层留出的一些内边距。 baseline是基线,baseline以上是负值,baseli

第一周-机器学习-梯度下降(gradient descent)
这仅是本人在cousera上学习机器学习的笔记,不能保证其正确性,谨慎参考 1、梯度下降函数,一直重复下面公式直到收敛(repeat until convergence),此时即可收敛得到局部最小值(converge to local minimum),该梯度下降法对多参数也可用(例如θ0,θ1,θ2,θ3,θ4,θ5……θn),注意该过程对每一次的j迭代是需要同步更新参数的(At each i
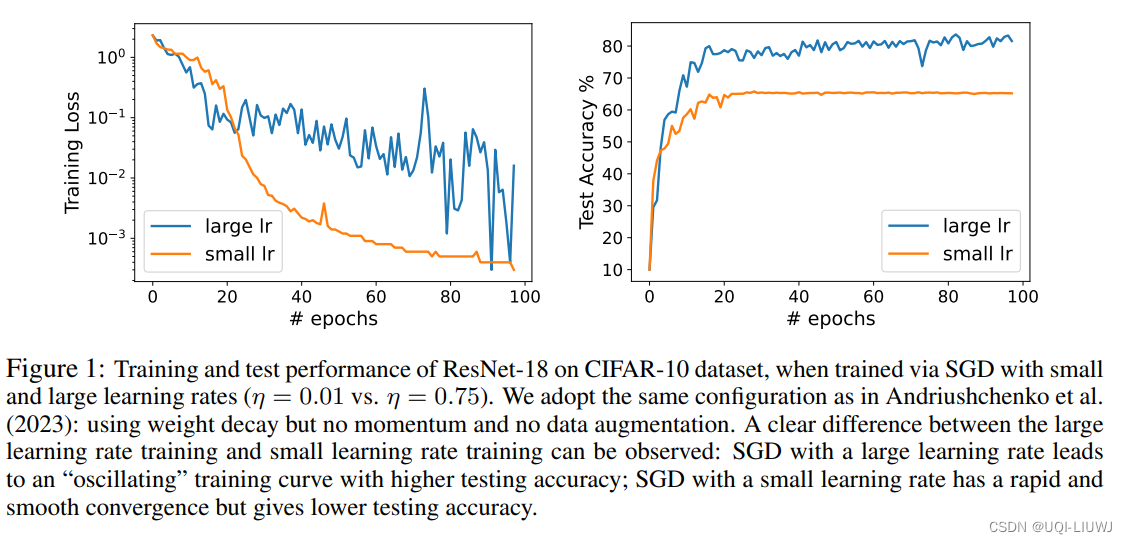
论文略读:Benign Oscillation of Stochastic Gradient Descent with Large Learning Rate
iclr 2024 reviewer评分 368 论文从理论上研究了通过随机梯度下降(SGD)且采用大学习率训练的神经网络(NN)的泛化特性论文的发现是,由于SGD的大学习率引起的NN权重的振荡,实际上有利于NN的泛化,潜在地优于通过SGD以小学习率训练的、更平滑收敛的相同NN ——>将这种现象称为“良性振荡”论文证明,通过振荡SGD且学习率较大训练的NN可以有效地学习在那些强特征存在的情况下的
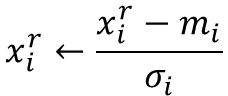
DL2020_Day2_Gradient Descent
目录 Gradient Descenthomework 1题目代码梯度下降介绍学习速率大小与loss function迭代关系AdagradStochastic Gradient DescentFeature Scaling Gradient Descent homework 1 题目 代码 下面是利用梯度下降法做线性回归预测,用了三种方法。效果发现直接写梯度下
04-Gradient Descent
我们上一篇文章讲了线性回归算法, 并且我们提到了一种解析式的求模型参数的方法——最小二乘法, 但是该方法具有局限性,我们使用该方法的前提要求是我们输入的特征矩阵必须是可逆的, 但很有可能我们的矩阵不是可逆的, 那么这时我们就无法使用最小二乘法了 。而且使用最小二乘法也需要满足我们的拟合函数是线性的, 如果我们的拟合函数不是线性的, 我们就需要通过一些技巧转化为线性才可以使用。所以仅用最小二乘法求解
Machine Learning ---- Gradient Descent
目录 一、The concept of gradient: ① In a univariate function: ②In multivariate functions: 二、Introduction of gradient descent cases: 三、Gradient descent formula and its simple understandi
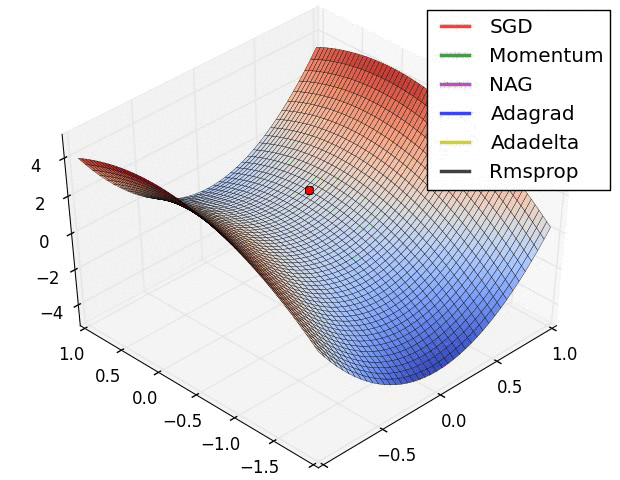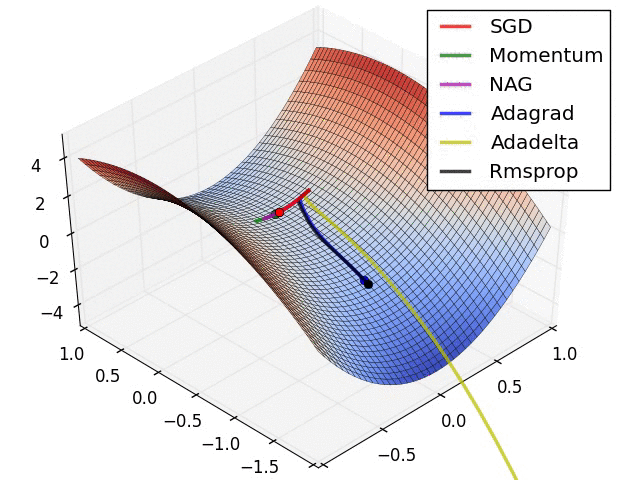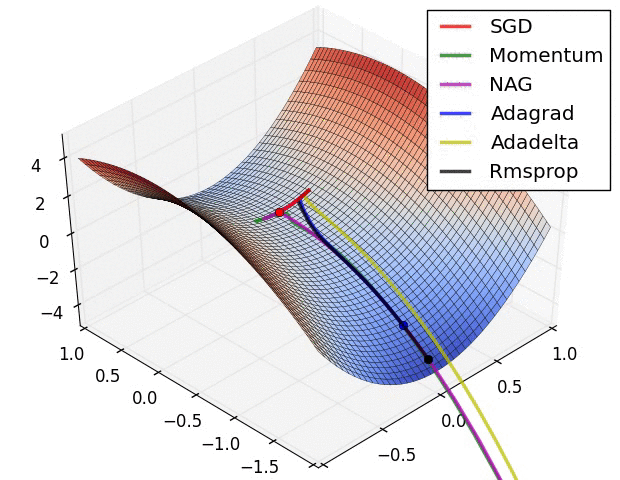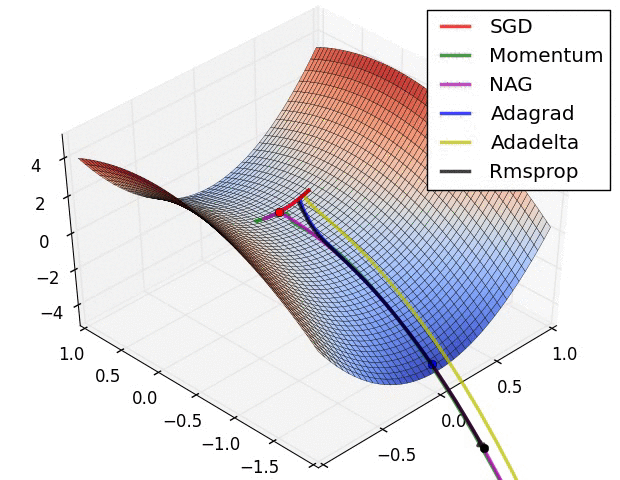
梯度下降优化算法概述 An overview of gradient descent optimization algorithms 论文阅读
寄语 今天开始学习读paper,希望自己能脚踏实地,勤奋努力不偷懒。正所谓“不积跬步,无以至千里;不积小流,无以成江海。” 吴恩达大大独门绝技 – “6分钟读论文” 学习论文,首先要构建一个知识架构,即大体分为哪几部分。然后再关注Abstract、Introduction、Conclusion,接着看非数学的部分,最后再去看相关的数学公式。 首先,带着这4个问题去读: 作者试图解决什么问

李宏毅机器学习笔记( 三)Gradient Descent
gradient descent 梯度下降 复习:选两个参数 求偏微分 核心还是寻找低点 Tip 1: Tuning your learning rates 不能过大过小 不同的速率导致的loss不同
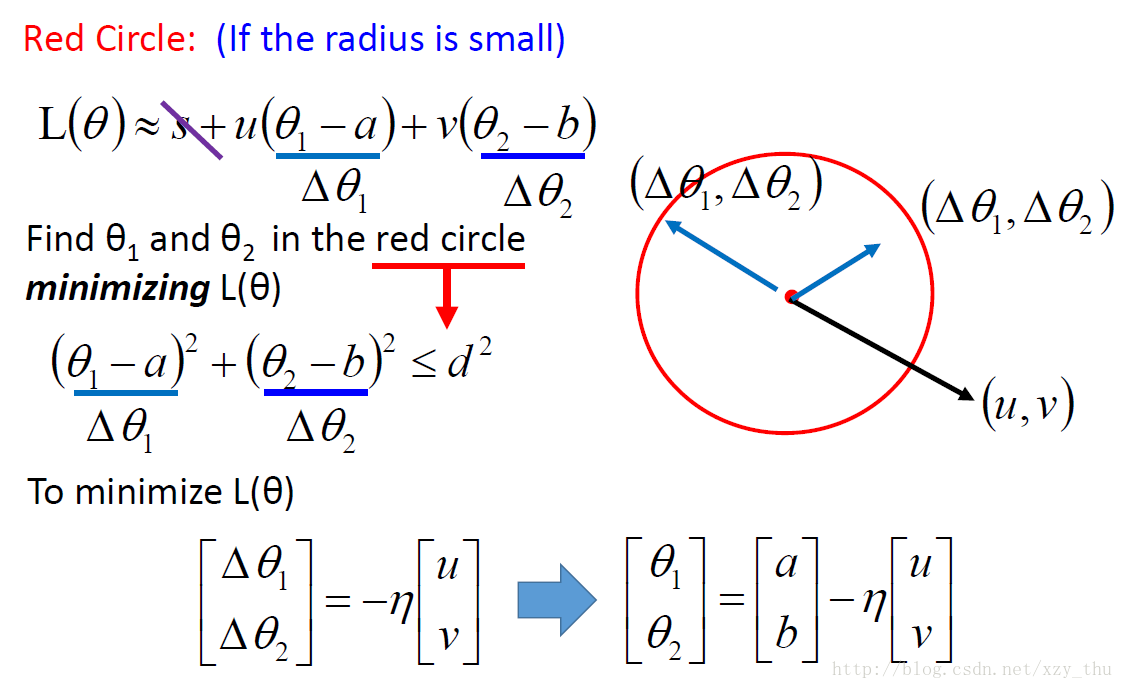
李宏毅机器学习课程笔记1:Regression、Error、Gradient Descent
台湾大学李宏毅老师的机器学习课程是一份非常好的ML/DL入门资料,李宏毅老师将课程录像上传到了YouTube,地址:NTUEE ML 2016 。 这篇文章是学习本课程第1-3课所做的笔记和自己的理解。 Lecture 1: Regression - Case Study machine learning 有三个步骤,step 1 是选择 a set of function, 即选择一个

台大李宏毅课程笔记2——Gradient Descent(梯度下降)
李宏毅课程笔记2 AdagradStochastic Gradient DescentFeature Scaling(特征缩放)梯度下降的理论解释 本次笔记主要包含三节课:Gradient Descent 1 2 3(梯度下降)李老师将梯度下降分为三节来讲,本次笔记对其进行统一的总结和记录。 先放上视频链接: Gradient Descent 1 https://www.bilib

梯度下降法(Gradient Descent)
梯度下降法(英语:Gradient descent)是一个一阶最优化算法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点;这个过程则被称为梯度上升法。 梯度下降法是最早最简单,也是最为常用的最优化方法。梯度下降法实现简单,当目标函数是凸函数时,梯度下
![[机器学习入门] 李宏毅机器学习笔记-3 (Gradient Descent ;梯度下降)](https://img-blog.csdn.net/20170601105719428?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc291bG1lZXRsaWFuZw==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
[机器学习入门] 李宏毅机器学习笔记-3 (Gradient Descent ;梯度下降)
[机器学习入门] 李宏毅机器学习笔记-3 (Gradient Descent ;梯度下降) PDFVIEDO Review 梯度下降的三个小贴士 Tip 1 Tuning your learning rates 最流行也是最简单的做法就是:在每一轮都通过一些因子来减小learning rate。 最开始时,我们距离最低点很远,所以我们用较大的步长。经过几轮后
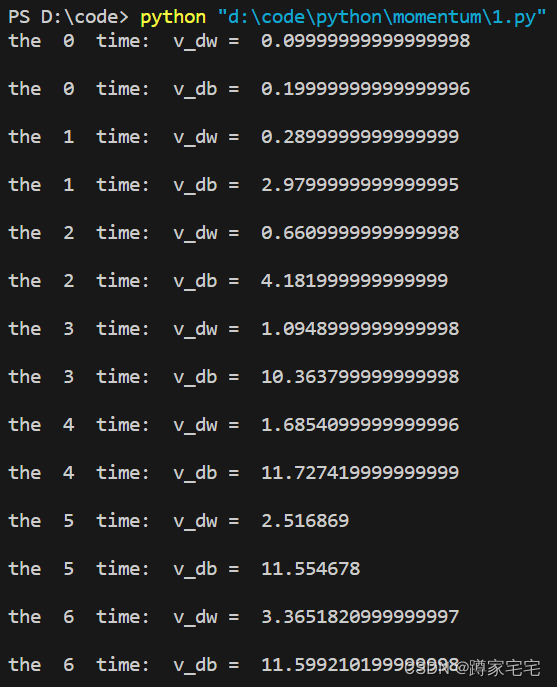
深度学习记录--Momentum gradient descent
Momentum gradient descent 正常的梯度下降无法使用更大的学习率,因为学习率过大可能导致偏离函数范围,这种上下波动导致学习率无法得到提高,速度因此减慢(下图蓝色曲线) 为了减小波动,同时加快速率,可以使用momentum梯度下降: 将指数加权平均运用到梯度下降,成为momentum梯度下降(图中红色曲线) 原理: 纵轴上,平均过程中正负数相互抵消,所以纵轴上的平

深度学习记录--mini-batch gradient descent
batch vs mini-batch gradient descent batch:段,块 与传统的batch梯度下降不同,mini-batch gradient descent将数据分成多个子集,分别进行处理,在数据量非常巨大的情况下,这样处理可以及时进行梯度下降,大大加快训练速度 mini-batch gradient descent的原理 两种方法的梯度下降图如下图所示
论文阅读--An overview of gradient descent optimization algorithms
An overview of gradient descent optimization algorithms∗ 文章目录 An overview of gradient descent optimization algorithms∗Abstract1 Introduction2 Gradient descent variants2.1 Batch gradient descent2.2

梯度下降优化( gradient descent optimization)
梯度下降优化 一个深度学习项目一般由数据、模型、损失、优化、训练和预测等部分构成,对于其中的“优化”部分,我们最熟悉的可以说就是 梯度下降(gradient descent) 算法了。然而,在实际的深度学习架构中,我们却经常看到的是Adam优化器,那么Adam和梯度下降算法有什么关系呢?又有哪些梯度下降算法的变体呢?以及又有哪些优化梯度下降算法的策略呢? 本文参考Sebastian Ruder的

【机器学习:Stochastic gradient descent 随机梯度下降 】机器学习中随机梯度下降的理解和应用
【机器学习:随机梯度下降 Stochastic gradient descent 】机器学习中随机梯度下降的理解和应用 背景随机梯度下降的基本原理SGD的工作流程迭代方法示例:线性回归中的SGD历史主要应用扩展和变体隐式更新(ISGD)动量平均 AdaGradRMSPropAdam基于符号的随机梯度下降回溯行搜索二阶方法 连续时间的近似优点与缺点GPT可视化示例 随机梯度下降(通
【学习笔记】[AGC060D] Same Descent Set
本来是想做点多项式调节一下,结果发现这玩意太肝了,似乎并没有起到调节作用。 设 f ( S ) f(S) f(S)表示符号为 < < <的下标集合恰好为 S S S的方案数,因为两个序列完全等同,因此答案等于 ∑ S ⊆ { 1 , 2 , . . . , n − 1 } f ( S ) 2 \sum_{S\subseteq \{1,2,...,n-1\}}f(S)^2 S⊆{1,2,...
![Leetcode 2110. Number of Smooth Descent Periods of a Stock [Python]](/front/images/it_default2.jpg)
Leetcode 2110. Number of Smooth Descent Periods of a Stock [Python]
DP。DP的每一位表示的是以此位数字为结尾的光滑下降序列。则,如果prices[i] + 1 == prices[i-1]。那么无论有多少光滑下降序列以prices[i-1]结尾,都有这样的数量再加上1(也就是prices[i]自己)结尾于prices[i]. class Solution:def getDescentPeriods(self, prices: List[int]) -> int
用人话讲明白梯度下降Gradient Descent(以求解多元线性回归参数为例)
文章目录 1.梯度2.多元线性回归参数求解3.梯度下降4.梯度下降法求解多元线性回归 梯度下降算法在机器学习中出现频率特别高,是非常常用的优化算法。 本文借多元线性回归,用人话解释清楚梯度下降的原理和步骤。 1.梯度 梯度是什么呢? 我们还是从最简单的情况说起,对于一元函数来讲,梯度就是函数的导数。 而对于多元函数而言,梯度是一个向量,也就是说,把求得的偏导数以向

Stochastic Gradient Descent vs Batch Gradient Descent vs Mini-batch Gradient Descent
梯度下降是最小化风险函数/损失函数的一种经典常见的方法,下面总结下三种梯度下降算法异同。 1、 批量梯度下降算法(Batch gradient descent) 以线性回归为例,损失函数为 BGD算法核心思想为每次迭代用所有的训练样本来更新Theta,这对于训练样本数m很大的情况是很耗时的。 BGD算法表示为 或者表示为 其中X(m*n)为训练样本矩阵,α为学习速率,m为样
Coordiante ascent VS Gradient descent
Coordiante ascent 坐标上升算法 详细解释可参考:http://cs229.stanford.edu/notes/cs229-notes3.pdf“>stanford ML 算法demo Gradient descent 梯度下降算法 详细参考:参考Andrew NG讲义 blog demo 现在谈谈两个算法的异同: 1.坐标上升法:坐标上升与坐标下降可以看做是一对,