本文主要是介绍论文略读:Benign Oscillation of Stochastic Gradient Descent with Large Learning Rate,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
iclr 2024 reviewer评分 368
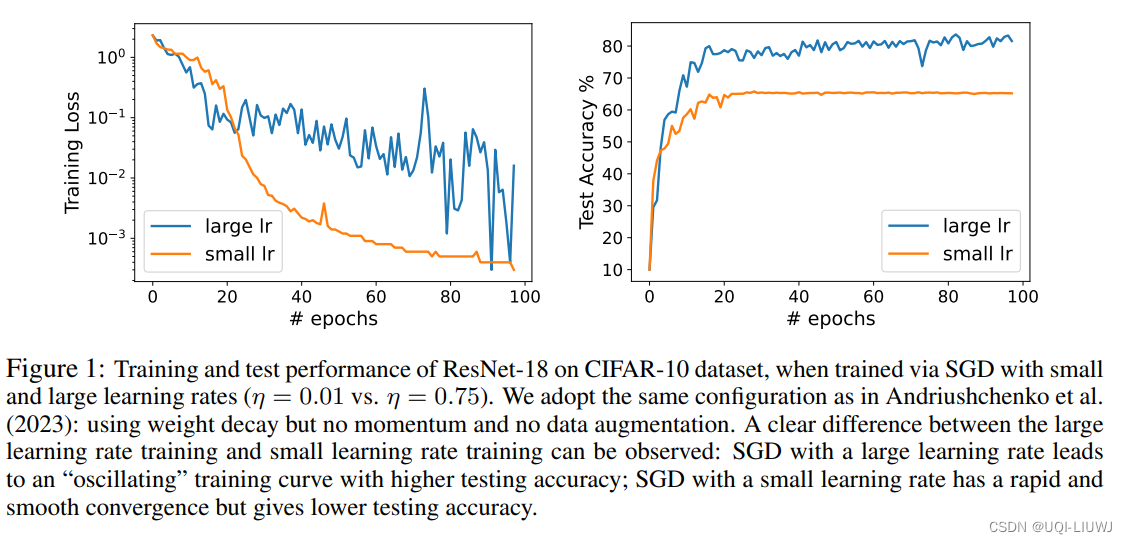
- 论文从理论上研究了通过随机梯度下降(SGD)且采用大学习率训练的神经网络(NN)的泛化特性
- 论文的发现是,由于SGD的大学习率引起的NN权重的振荡,实际上有利于NN的泛化,潜在地优于通过SGD以小学习率训练的、更平滑收敛的相同NN
- ——>将这种现象称为“良性振荡”
- 论文证明,通过振荡SGD且学习率较大训练的NN可以有效地学习在那些强特征存在的情况下的弱特征。相比之下,通过SGD且学习率较小训练的NN只能学习强特征,而在学习弱特征方面几乎没有进展
- ——>当面对只包含弱特征的新测试数据点时,通过振荡SGD且学习率较大训练的NN仍然可以做出正确的预测,而通过SGD且学习率较小训练的NN则不能
这篇关于论文略读:Benign Oscillation of Stochastic Gradient Descent with Large Learning Rate的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

