gradient专题

css渐变色背景|<gradient示例详解
《css渐变色背景|<gradient示例详解》CSS渐变是一种从一种颜色平滑过渡到另一种颜色的效果,可以作为元素的背景,它包括线性渐变、径向渐变和锥形渐变,本文介绍css渐变色背景|<gradien... 使用渐变色作为背景可以直接将渐China编程变色用作元素的背景,可以看做是一种特殊的背景图片。(是作为背

Nn criterions don’t compute the gradient w.r.t. targets error「pytorch」 (debug笔记)
Nn criterions don’t compute the gradient w.r.t. targets error「pytorch」 ##一、 缘由及解决方法 把这个pytorch-ddpg|github搬到jupyter notebook上运行时,出现错误Nn criterions don’t compute the gradient w.r.t. targets error。注:我用

【CSS渐变】背景中的百分比:深入理解`linear-gradient`,进度条填充
在现代网页设计中,CSS渐变是一种非常流行的视觉效果,它为网页背景或元素添加了深度和动态感。linear-gradient函数是实现线性渐变的关键工具,它允许我们创建从一种颜色平滑过渡到另一种颜色的视觉效果。在本篇博客中,我们将深入探讨linear-gradient函数中的百分比值,特别是像#C3002F 50%, #e8e8e8 0这样的用法,以及它们如何影响渐变效果。 什么是linear-g

AI学习指南深度学习篇-随机梯度下降法(Stochastic Gradient Descent,SGD)简介
AI学习指南深度学习篇-随机梯度下降法(Stochastic Gradient Descent,SGD)简介 在深度学习领域,优化算法是至关重要的一部分。其中,随机梯度下降法(Stochastic Gradient Descent,SGD)是最为常用且有效的优化算法之一。本篇将介绍SGD的背景和在深度学习中的重要性,解释SGD相对于传统梯度下降法的优势和适用场景,并提供详细的示例说明。 1.
[数字信号处理][Python] numpy.gradient()函数的算法实现
先看实例 import numpy as npsignal = [3,2,1,3,8,10]grad = np.gradient(signal)print(grad) 输出结果是 [-1. -1. 0.5 3.5 3.5 2. ] 这个结果是怎么来的呢? np.gradient 计算信号的数值梯度,也就是信号值的变化率。它使用中心差分法来计算中间点的梯度,并使用前向差分法和后向差分法

机器学习-有监督学习-集成学习方法(六):Bootstrap->Boosting(提升)方法->LightGBM(Light Gradient Boosting Machine)
机器学习-有监督学习-集成学习方法(六):Bootstrap->Boosting(提升)方法->LightGBM(Light Gradient Boosting Machine) LightGBM 中文文档 https://lightgbm.apachecn.org/ https://zhuanlan.zhihu.com/p/366952043

基于Python的机器学习系列(18):梯度提升分类(Gradient Boosting Classification)
简介 梯度提升(Gradient Boosting)是一种集成学习方法,通过逐步添加新的预测器来改进模型。在回归问题中,我们使用梯度来最小化残差。在分类问题中,我们可以利用梯度提升来进行二分类或多分类任务。与回归不同,分类问题需要使用如softmax这样的概率模型来处理类别标签。 梯度提升分类的工作原理 梯度提升分类的基本步骤与回归类似,但在分类任务中,我们使

linear-gradient 渐变
CSS3 Gradient 分为 linear-gradient(线性渐变)和 radial-gradient(径向渐变)。而我们今天主要是针对线性渐变来剖析其具体的用法。为了更好的应用 CSS3 Gradient,我们需要先了解一下目前的几种现代浏览器的内核,主要有 Mozilla(Firefox,Flock等)、WebKit(Safari、Chrome等)、Opera(Opera浏览器

神经网络算法 - 一文搞懂Gradient Descent(梯度下降)
本文将从梯度下降的本质、梯度下降的原理、梯度下降的算法 三个方面,带您一文搞懂梯度下降 Gradient Descent | GD。 梯度下降 机器学习“三板斧”:选择模型家族,定义损失函数量化预测误差,通过优化算法找到最小化损失的最优模型参数。 机器学习 vs 人类学习 定义一个函数集合(模型选择) 目标:确定一个合适的假设空间或模型家族。 示例:线性回归、逻辑回归、神
让IE8支持CSS3属性(border-radius、box-shadow、linear-gradient)
下载 PIE-1.0.0.zip解压后,将文件夹重命名为PIE,放到项目目录下在CSS3文件中添加一行代码 behavior: url(PIE/PIE.htc); 例如: .form__input{border-radius: 0.3em;behavior: url(PIE/PIE.htc);} 参考: TYStudio-专注WEB前端开发 css3pie

AI播客下载:The Gradient-AI前沿见解
The Gradient 是一个致力于让更多人轻松了解人工智能,并促进人工智能社区内讨论的组织。我们目前开展的项目包括 The Gradient 杂志、The Gradient 播客、The Update 通讯以及 Mastodon 实例 Sigmoid Social。 我们是一个由来自不同机构和公司的研究生、研究人员及工程师组成的非盈利、志愿者运营团队。我们成立于 2017 年,由斯坦福人工智
[deeplearning-001] stotisticks gradient descent随机梯度下降算法的最简单例子解释
1.gradient descent梯度下降优化 1.1假设要优化一个函数 f(x)=(x−1)2 f(x)=(x-1)^2求它的最小值。这个函数在 x=1 x=1 时有最小值,这是解析解。如果用梯度下降法,是这样的: f′(x)=2(x−1) f^{'}(x)=2(x-1) 每一步的迭代公式是: xi+1=xi−ηf′(xi) x_{i+1}=x_{i} - \eta f^{'}(x
Imgs,GT,Edge,Gradient_all,Gradient_Foreground
保存一下: 做个记录: import cv2import osimport numpy as np# 对整张图片做canny检测 得到纹理图def canny_all(input_path, output_path):# 遍历文件夹中的所有文件for filename in os.listdir(input_path):# 构造完整的文件路径image_path = os.path.jo
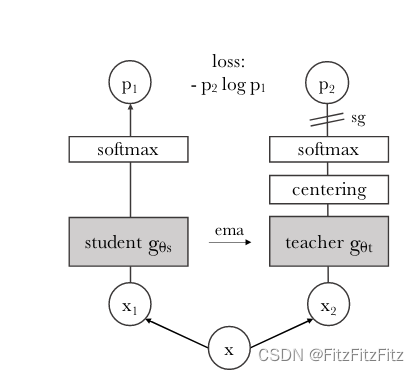
DINO结构中的exponential moving average (ema)和stop-gradient (sg)
DINO思路介绍 在 DINO 中,教师和学生网络分别预测一个一维的嵌入。为了训练学生模型,我们需要选取一个损失函数,不断地让学生的输出向教师的输出靠近。softmax 结合交叉熵损失函数是一种常用的做法,来让学生模型的输出与教师模型的输出匹配。具体地,通过 softmax 函数把教师和学生的嵌入向量尺度压缩到 0 到 1 之间,并计算两个向量的交叉熵损失。这样,在训练过程中,学生模型可以通
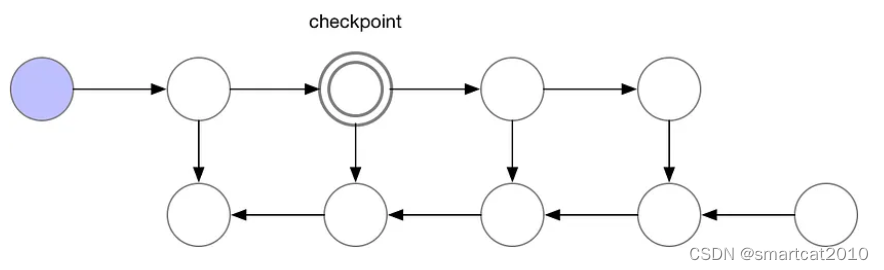
Gradient-checkpointing的原理
原文: 将更大的网络安装到内存中。|by 雅罗斯拉夫·布拉托夫 |张量流 |中等 (medium.com) 前向传播时,隔几层就保留一层activation数据,其余层的activation都释放掉; 反向传播时,从最近的checkpoint去重新跑forward,这次跑的不删除;计算梯度每用完一层,才释放掉该层的activation; N层网络,使用sqrt(N)个checkpo
梯度下降(Gradient Descent)原理以及Python代码
给定一个函数,我们想知道当是值是多少的时候使这个函数达到最小值。为了实现这个目标,我们可以使用梯度下降(Gradient Descent)进行近似求解。 梯度下降是一个迭代算法,具体地,下一次迭代令 是梯度,其中是学习率(learning rate),代表这一轮迭代使用多少负梯度进行更新。梯度下降非常简单有效,但是其中的原理是怎么样呢? 原理 为什么每次使用负梯度进行更新呢?这要从泰勒

Pytorch入门(7)—— 梯度累加(Gradient Accumulation)
1. 梯度累加 在训练大模型时,batch_size 最大值往往受限于显存容量上限,当模型非常大时,这个上限可能小到不可接受。梯度累加(Gradient Accumulation)是一个解决该问题的 trick梯度累加的思想很简单,就是时间换空间。具体而言,我们不在每个 batch data 梯度计算后直接更新模型,而是多算几个 batch 后,使用这些 batch 的平均梯度更新模型,从而放大

前端css中线性渐变(linear-gradient)的使用
前端css中线性渐变 一、前言二、关键词句三、主要内容说明(一)、线性渐变方向1.角度调整方向2.负值角度,源码13.源码1运行效果4.关键字调整方向5.to right向右线性渐变,源码26.源码2运行效果 (二)、线性渐变颜色断点1.颜色断点距离,源码32.源码3运行效果 四、结语五、定位日期 一、前言 linear-gradient线性渐变是一种两个以上颜色之间的平滑过渡

使用CSS3创建文字颜色渐变(CSS3 Text Gradient)
转载请标明出处:蒋宇捷(hfahe) http://blog.csdn.net/hfahe 考虑一下,如何在网页中达到类似以下文字渐变的效果? 传统的实现中,是用一副透明渐变的图片覆盖在文字上。具体实现方式可参考http://www.qianduan.net/css-gradient-text-effect.html。这种方式优点是图片可控,所

第一周-机器学习-梯度下降(gradient descent)
这仅是本人在cousera上学习机器学习的笔记,不能保证其正确性,谨慎参考 1、梯度下降函数,一直重复下面公式直到收敛(repeat until convergence),此时即可收敛得到局部最小值(converge to local minimum),该梯度下降法对多参数也可用(例如θ0,θ1,θ2,θ3,θ4,θ5……θn),注意该过程对每一次的j迭代是需要同步更新参数的(At each i
深度强化学习系列tensorflow2.0自定义loss函数实现policy gradient策略梯度
本篇文章利用tensorflow2.0自定义loss函数实现policy gradient策略梯度,自定义loss=-log(prob) *Vt现在训练最高分能到193分,但是还是不稳定,在修改中,欢迎一起探讨文章代码也有参考莫烦大佬的代码action_dim = 2 //定义动作state_dim = 4 //定义状态env = gym.make('CartPole-v0')class

渐变效果-gradient(秒懂网页中的渐变效果)
目录 一、渐变介绍 1.概念 2.特点 3.功能 4.好处 5.高级特性 二、渐变用法 1.线性渐变 1.1 线性渐变-从上到下(默认情况) 1.2 线性渐变-从左到右 1.3 线性渐变-对角 1.4.使用角度 1.5.使用多个颜色节点 1.6,使用透明度 1.7.重复的线性渐变 2.径向渐变 3.角向渐变 三、应用场景 四、总结 一、

linear-gradient与radial-gradient
渐变可以创建类似于彩虹的效果,低版本的浏览器不的不使开发者用图片来实现,CSS3将会轻松实现网页渐变效果。 要得上面的线性渐变效果,我们这样去定义CSS3样式: background-image: -moz-linear-gradient(top, #8fa1ff, #3757fa); /* Firefox */background-image: -webkit-gradient(lin

【强化学习的数学原理-赵世钰】课程笔记(九)策略梯度方法(Policy Gradient Method)
目录 一.policy gradient 的基本思路(Basic idea of policy gradient) 二.定义最优策略的 metrics,也就是 objective function 是什么 三.objective function 的 gradient 四.梯度上升算法(REINFORCE) 五.总结 上节课介绍了 value function approxim
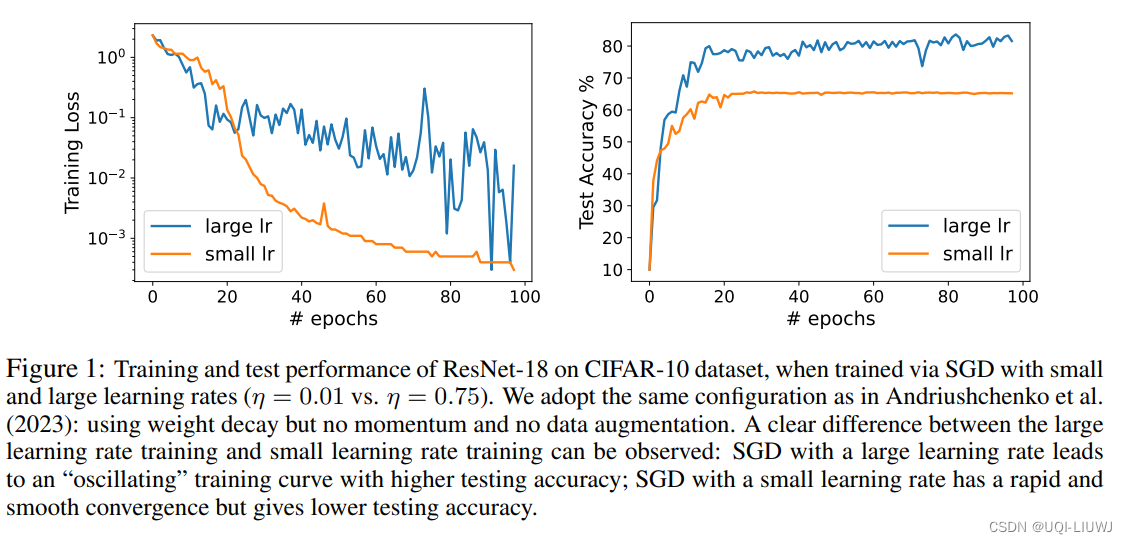
论文略读:Benign Oscillation of Stochastic Gradient Descent with Large Learning Rate
iclr 2024 reviewer评分 368 论文从理论上研究了通过随机梯度下降(SGD)且采用大学习率训练的神经网络(NN)的泛化特性论文的发现是,由于SGD的大学习率引起的NN权重的振荡,实际上有利于NN的泛化,潜在地优于通过SGD以小学习率训练的、更平滑收敛的相同NN ——>将这种现象称为“良性振荡”论文证明,通过振荡SGD且学习率较大训练的NN可以有效地学习在那些强特征存在的情况下的