stochastic专题

AI学习指南深度学习篇-随机梯度下降法(Stochastic Gradient Descent,SGD)简介
AI学习指南深度学习篇-随机梯度下降法(Stochastic Gradient Descent,SGD)简介 在深度学习领域,优化算法是至关重要的一部分。其中,随机梯度下降法(Stochastic Gradient Descent,SGD)是最为常用且有效的优化算法之一。本篇将介绍SGD的背景和在深度学习中的重要性,解释SGD相对于传统梯度下降法的优势和适用场景,并提供详细的示例说明。 1.
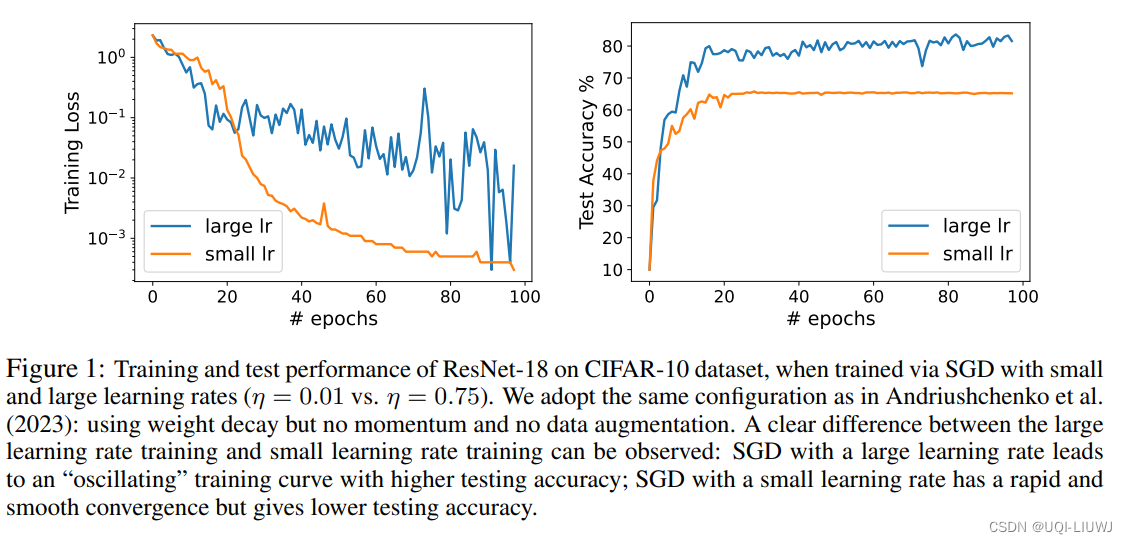
论文略读:Benign Oscillation of Stochastic Gradient Descent with Large Learning Rate
iclr 2024 reviewer评分 368 论文从理论上研究了通过随机梯度下降(SGD)且采用大学习率训练的神经网络(NN)的泛化特性论文的发现是,由于SGD的大学习率引起的NN权重的振荡,实际上有利于NN的泛化,潜在地优于通过SGD以小学习率训练的、更平滑收敛的相同NN ——>将这种现象称为“良性振荡”论文证明,通过振荡SGD且学习率较大训练的NN可以有效地学习在那些强特征存在的情况下的
带延迟的随机逼近方案(Stochastic approximation schemes):在网络和机器学习中的应用
1. 并行队列系统中的动态定价Dynamic pricing 1.1 系统的表述 一个含有并行队列的动态定价系统,该系统中对于每个队列有一个入口收费(entry charge) ,且系统运行的目标是保持队列长度接近于某个理想的配置。 这里是这个系统的几个关键假设: a. 存在 K 个并行队列(parallel queues):每个队列 i
无监督学习 - t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)
什么是机器学习 t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)是一种非线性降维技术,用于将高维数据映射到低维空间,以便更好地可视化数据的结构。t-SNE主要用于聚类分析和可视化高维数据的相似性结构,特别是在探索复杂数据集时非常有用。 t-SNE的基本原理 相似度测量: 对于高维数据中的每一对数据点,计算它们之间的相似度。

【机器学习:Stochastic gradient descent 随机梯度下降 】机器学习中随机梯度下降的理解和应用
【机器学习:随机梯度下降 Stochastic gradient descent 】机器学习中随机梯度下降的理解和应用 背景随机梯度下降的基本原理SGD的工作流程迭代方法示例:线性回归中的SGD历史主要应用扩展和变体隐式更新(ISGD)动量平均 AdaGradRMSPropAdam基于符号的随机梯度下降回溯行搜索二阶方法 连续时间的近似优点与缺点GPT可视化示例 随机梯度下降(通

Stochastic Gradient Descent vs Batch Gradient Descent vs Mini-batch Gradient Descent
梯度下降是最小化风险函数/损失函数的一种经典常见的方法,下面总结下三种梯度下降算法异同。 1、 批量梯度下降算法(Batch gradient descent) 以线性回归为例,损失函数为 BGD算法核心思想为每次迭代用所有的训练样本来更新Theta,这对于训练样本数m很大的情况是很耗时的。 BGD算法表示为 或者表示为 其中X(m*n)为训练样本矩阵,α为学习速率,m为样

机器学习: t-Stochastic Neighbor Embedding 降维算法 (一)
Introduction 在计算机视觉及机器学习领域,数据的可视化是非常重要的一个应用,一般我们处理的数据都是成百上千维的,但是我们知道,目前我们可以感知的数据维度最多只有三维,超出三维的数据是没有办法直接显示出来的,所以需要做降维的处理,数据的降维,简单来说就是将高维度的数据映射到较低的维度,如果要能达到数据可视化的目的,就要将数据映射到二维或者三维空间。数据的降维是一种无监督的学习过程,我们

【论文记录】Stochastic gradient descent with differentially private updates
记录几条疑问 The sample size required for a target utility level increases with the privacy constraint.Optimization methods for large data sets must also be scalable.SGD algorithms satisfy asymptotic guara

PyTorch深度学习实践 3.梯度下降算法-->mini-batch stochastic gradient descent
分治法 w1和w2 假设横竖都是64 横竖都分成4份,一共16份。 第一次在这16份里,找出比较小的点, 再来几轮,基本就OK了。 从原来的16x16变成了16+16 贪心法 梯度下降法,局部最优,实际上,大家发现神经网络里并没有很多的局部最优点 鞍点g=0,无法迭代了 import numpy as npimport matplotlib.pyplot as pltxxl=0.
fractional Brownian Motion driven stochastic integrals
See https://mathoverflow.net/questions/304366/fractional-brownian-motion-driven-stochastic-integrals

Batch Gradient Descendent (BGD) Stochastic Gradient Descendent (SGD)
SGD, BGD初步描述(原文来自:http://blog.csdn.net/lilyth_lilyth/article/details/8973972,@熊均达@SJTU 做出解释及说明) 梯度下降(GD)是最小化风险函数、损失函数(注意Risk Function和Cost Function在本文中其实指的一个意思,在不同应用领域里面可能叫法会有所不同。解释:@熊均达@SJTU)的

Stochastic Trajectory Prediction with Social Graph Network
基于社会图网络的随机轨迹预测 摘要 由于现实世界中人类社会行为的复杂性和未来运动的不确定性,行人轨迹预测是一项具有挑战性的任务。对于第一个问题,现有的方法采用完全连通的拓扑来建模社会行为,而忽略了非对称的成对关系。为了有效地捕捉相关行人的社交行为,我们利用了一个基于及时位置和速度方向动态构建的有向社交图。基于社会图,我们进一步提出了一个收集社会效应和累积个体表征的网络,以生成面向目的地和社会感