本文主要是介绍论文阅读--An overview of gradient descent optimization algorithms,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
An overview of gradient descent optimization algorithms∗
文章目录
- An overview of gradient descent optimization algorithms∗
- Abstract
- 1 Introduction
- 2 Gradient descent variants
- 2.1 Batch gradient descent
- 2.2 Stochastic gradient descent
- 2.3 Mini-batch gradient descent
- 3 Challenges
- 4 Challenges
- 4.1 Momentum
- 4.2 Nesterov accelerated gradient
- 4.3 Adagrad
- 4.4 Adadelta
- 4.5 RMSprop
- 4.6 Adam
- 4.7 AdaMax
- 4.8 Nadam
- 4.9 Visualization of algorithms
- 4.10 Which optimizer to use?
Abstract
梯度下降法(Gradient Descent)优化算法,越来越受欢迎,通常用作black-box优化器,但是实践证明他们的优点和缺点都很难克服。本文旨在提供不同算法的表现,主要是梯度下降法的变体,总结了解决问题的挑战,介绍了常见的优化算法,而且调查了优化梯度下降方法的策略。
1 Introduction
梯度下降法是处理优化最受欢迎的算法,而且是目前优化神经网络常见的方法。同时,每个最新的深度学习包都包含了优化梯度下降的不同算法的实现(lasagne,caffe,Keras),这些算法通常作为black-box优化器。
本文主要对不同优化梯度下降的算法进行介绍:
section 2:了解梯度下降的不同变体;
section 3:总结训练时的挑战;
section 4:介绍最常见的优化算法和如何处理这些挑战及算法的流程,更新的规则;
section 5:并行和分布式的方法如何优化梯度下降法;
section 6:介绍优化梯度下降的其他策略。
梯度下降法最下化目标函数 J ( θ ) J(\theta) J(θ),参数是 θ ∈ R d \theta \in {\Bbb R}^d θ∈Rd,通过目标函数 ∇ θ J ( θ ) {\nabla}_{\theta}J(\theta) ∇θJ(θ)。学习速率 η \eta η决定到达(局部)最小值的步数,换句话说,在目标函数的图上,随着表面坡度一直下降,直到山谷。
2 Gradient descent variants
有三种梯度下降法的变体,差别在于用多少数据来计算目标函数的梯度。根据数据的大小,在参数更新的准确率和进行更新所需的时间上进行trade-off。
2.1 Batch gradient descent
Vanilla gradient descent 和 aka batch gradient descent计算关于整个数据集的参数 θ \theta θ的损失函数的梯度:
(1) θ = θ − η ⋅ ∇ θ J ( θ ) \theta = \theta-\eta\cdot{\nabla}_{\theta}J(\theta) \tag{1} θ=θ−η⋅∇θJ(θ)(1)
一次更新就要计算整个数据集的梯度,batch gradient descent非常慢,而且当数据无法全部加载到内存时无法处理。批梯度下降法无法在线更新模型,比如如果有新的样本。
for i in range ( nb_epochs ):params_grad = evaluate_gradient ( loss_function , data , params )params = params - learning_rate * params_grad对于预先定义好的迭代次数,首先计算整个数据集的损失函数的梯度向量params_grad,现在一些深度学习包提供了自动微分的算法计算梯度。根据梯度的方向计算参数,然后决定学习速率的大小。batch gradient descent在凸优化问题上可以收敛到全局最优,非凸问题可以收敛到局部最优。
2.2 Stochastic gradient descent
Stochastic gradient descent (SGD)对每个训练样本 ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i))进行参数更新:
(2) θ = θ − η ⋅ ∇ θ J ( θ ; x ( i ) , y ( i ) ) \theta = \theta-\eta\cdot{\nabla}_{\theta}J(\theta;x^{(i)}, y^{(i)}) \tag{2} θ=θ−η⋅∇θJ(θ;x(i),y(i))(2)
Batch gradient descent对于大数据集进行的多余的计算,因为在进行参数更新时,相似的样本也要重新计算。SGD通过更新一次计算一次处理这个问题。SGD通常比较快,而且可以处理在线问题,由于SGD频繁更新导致高方差,这就导致目标函数振荡严重,如图所示。
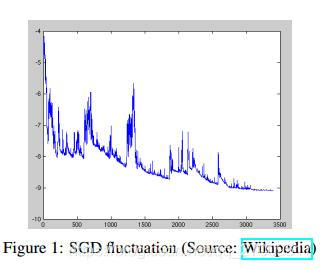
当batch gradient descent收敛到参数空间的最优点时,SGD的振荡却可以跳到新的可能局部最优点,另外,SGD的过度调整使最小点变得复杂。但是,当逐渐降低学习速率,SGD和batch gradient descent有相同的收敛方式,通常肯定会收敛到局部最优(non-convex)或全局最优(convex),代码只是在训练样本上添加一个循环,并且分别估计每个样本的梯度,代码如下:
for i in range ( nb_epochs ):np. random . shuffle ( data )for example in data :params_grad = evaluate_gradient ( loss_function , example , params )params = params - learning_rate * params_grad
2.3 Mini-batch gradient descent
Mini-batch gradient descent 有以上两个的优点,对一个mini-batch的 n n n个训练样本进行更新,公式如下:
(3) θ = θ − η ⋅ ∇ θ J ( θ ; x ( i : i + n ) , y ( i : i + n ) ) \theta=\theta-\eta\cdot{\nabla}_{\theta}J(\theta;x^{(i:i+n)}, y^{(i:i+n)}) \tag{3} θ=θ−η⋅∇θJ(θ;x(i:i+n),y(i:i+n))(3)
这种方法,a)降低了参数更新的方差,可以获得更稳定的收敛;b)可以充分使用优化矩阵算法,和关于mini-batch的梯度的深度学习包相似。和大小在50-256之间的mini-batch相似,但不同的应用不同。mini-batch梯度下降法只是训练神经网络时的一种选择,使用mini-batch时使用SGD。
在代码中,不是循环训练样本,假设mini-batches=50
for i in range ( nb_epochs ):np. random . shuffle ( data )for batch in get_batches (data , batch_size =50):params_grad = evaluate_gradient ( loss_function , batch , params )params = params - learning_rate * params_grad
3 Challenges
Vanilla mini-batch gradient descent不能保证很好的收敛,但提供了一些需要处理的挑战:
- 选择恰当的学习速率很难。小的学习速率导致慢的收敛速度,大的学习速率会阻碍收敛,导致损失函数在最小值附近动荡,甚至发散。
- Learning rate schedules通过退火算法调整学习速率,比如通过预先定义好的日程降低学习速率或是两个epoch之间的降低低于某个阈值。这些日程和阈值,必须先定义好并且无法根据数据的特性进行调整。
- 另外,所有的参数更新使用相同的学习速率。如果数据集是稀疏的,并且特征有不同的频率,我们可能不想使用相同的程度更新他们,但对于较少出现的特征更新更大。
- 最小化神经网络的高维非凸误差函数的主要挑战是如何避免陷入大量的局部最优点中。Dauphin et al认为导致困难的不是局部最优点而是鞍点,比如点的某一维斜率上升而另一维下降。这些鞍点通常由同一错误包围,SGD很难处理这些,因为每一维的梯度都接近零。
4 Challenges
接下来介绍处理之前的挑战的算法,不介绍无法处理高维数据的算法,比如二阶方法,牛顿方法。
4.1 Momentum
SGD有navigating ravines(沟壑),比如在表面曲线更陡的维度,而另一维不会,通常在局部最优点上。这种情况下,SGD在沟壑的陡峭处振荡,导致往低处的速度很慢。
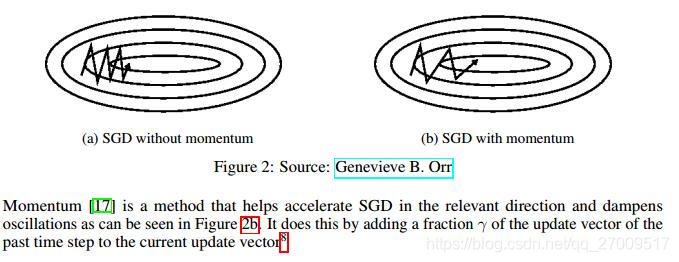
Momentum在相关方向帮助SGD和降低动荡的危害。通过增加一个摩擦系数 γ \gamma γ来更新向量
v t = γ v t − 1 + η ∇ θ J ( θ ) v_t = {\gamma}v_{t-1}+ {\eta}{\nabla}_{\theta}J(\theta) vt=γvt−1+η∇θJ(θ)
θ = θ − v t \theta=\theta-v_t θ=θ−vt
momentum项 g a m m a gamma gamma通常设为0.9或相似的值。
使用momentum时,相当于在斜坡推一个球,这个球在往下滚时积累了momentum,变得越来越快(直到到达最终的速度)。参数更新也是相似的:momentum项在梯度相同的方向增加,在梯度改变方向时减少。因此,获得更快的收敛速度和降低振荡。
4.2 Nesterov accelerated gradient
球在斜坡下滚时是没有目的的,我们需要一个更聪明的球,知道如何走。
Nesterov accelerated gradient (NAG)使momentum有这个认知。我们要把momentum项 γ v t − 1 {\gamma}v_{t-1} γvt−1移到参数 θ \theta θ处,计算 θ − γ v t − 1 \theta-{\gamma}v_{t-1} θ−γvt−1可得参数的下个大概位置,大体上我们的参数如何修改。现在我们可以有效计算梯度,不是关于当前的参数 θ \theta θ,而是参数未来的大概位置:
v t = γ v t − 1 + η ∇ θ J ( θ − γ v t − 1 ) v_t={\gamma}v_{t-1}+\eta\nabla_{\theta}J(\theta-{\gamma}v_{t-1}) vt=γvt−1+η∇θJ(θ−γvt−1)
θ = θ − v t \theta=\theta-v_t θ=θ−vt
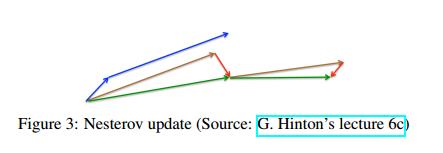
另外momentum项设置为 γ \gamma γ设置为0.9,第一个momentum计算当前的梯度,然后在更新了的积累梯度的方向上跳一大步,NAG在首先在之前积累的梯度上跳一步,测量梯度,然后获得正确的。这个预想更新可以防止更新太快,并且快反应,在RNNs的许多任务上提高了性能。
现在我们可以根据误差函数的斜率更新参数,并且加速SGD,而且可以根据每个参数进行更新,就是根据参数的重要性进行小的或大的更新。
4.3 Adagrad
Adagrad是基于梯度的算法,使学习速率的更新是根据参数的,出现频繁的参数更新小,不频繁的参数更新大。基于这个原因,处理稀疏数据比较好。Dean et al发现adagrad可以提高SGD的鲁棒性,并且用来训练大的神经网络,比如识别YouTube的猫的视频。另外,Pennington 使用Adagrad来训练GloVe词向量,因为频率少的词比其他词需要更大的更新系数。
之前,所有参数 θ \theta θ的更新使用相同的学习速率 η \eta η,Adagrad中,不同的参数 θ i \theta_i θi使用不同的学习速率,在每个time step t t t,首先是adagrad的每个参数的更新,为了简化,假设 g ( t , i ) g_(t,i) g(t,i)是关于参数 θ i \theta_i θi在time step t t t时的目标函数的梯度:
g t , i = ∇ θ t J ( θ t , i ) g_{t, i}=\nabla_{\theta_t}J(\theta_{t, i}) gt,i=∇θtJ(θt,i)
SGD在每个time step t t t上更新每个参数 θ i \theta_i θi:
θ t + 1 , i = θ t , i − η ⋅ g t , i \theta_{t+1, i}=\theta_{t, i}-\eta{\cdot}g_{t, i} θt+1,i=θt,i−η⋅gt,i
在更新规则中,adagrad在每个time step t t t修改每个参数 θ i \theta_i θi的学习速率 η \eta η:
(8) θ t + 1 , i = θ t , i − η G ( t , i i ) + ε ⋅ g t , i \theta_{t+1, i}=\theta_{t, i}- \frac{\eta}{\sqrt{G_(t, ii)+\varepsilon}} \cdot g_{t, i} \tag{8} θt+1,i=θt,i−G(t,ii)+εη⋅gt,i(8)
G t ∈ R d × d G_t \in {\Bbb R}^{d \times d} Gt∈Rd×d<
这篇关于论文阅读--An overview of gradient descent optimization algorithms的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









