本文主要是介绍DL2020_Day2_Gradient Descent,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- Gradient Descent
- homework 1
- 题目
- 代码
- 梯度下降介绍
- 学习速率大小与loss function迭代关系
- Adagrad
- Stochastic Gradient Descent
- Feature Scaling
Gradient Descent
homework 1
题目

代码
下面是利用梯度下降法做线性回归预测,用了三种方法。效果发现直接写梯度下降的代码效果比调用sklearn中线性回归模型以及岭回归模型要好。可能与直接编写的代码中针对学习速率做了调整有关。
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import SGDRegressor, Ridge
from sklearn.metrics import mean_squared_error# 读取训练数据和测试数据
train_data = pd.read_csv(r"C:\Users\dell\Desktop\机器学习\DL2020\data\hw1\train.csv", encoding='big5')
test_data = pd.read_csv(r"C:\Users\dell\Desktop\机器学习\DL2020\data\hw1\test.csv", encoding='big5')# 把NR这里的值先换成0,然后去掉前面多余的列,记住PM2.5位于每项第十行
train_data = train_data.replace(to_replace='NR', value=0)
test_data = test_data.replace(to_replace='NR', value=0)
train_data = train_data.iloc[:, 3:]
# print(train_data.shape)
# print(test_data.shape)
# print(train_data.head(30))# 按照训练的要求,要把原始数据也分为10个一组。用前九个小时的数据作为训练的输入,最后一个小时的PM2.5作为训练的目标值。# (1)根据shape的查看结果,有12个月、每个月20天的数据。我们把数据分为12组,每组480小时和18个特征。
data1 = train_data.to_numpy() # np.array形式,切片[]
month_data = {}
for month in range(12):sample = np.empty([18, 480]) # 以十八个特征为行,480小时为列的空矩阵for day in range(20):sample[:, day * 24: (day + 1) * 24] = data1[18 * (20 * month + day): 18 * (20 * month + day + 1), :]# 把18个特征为一循环,20天一个月,所以"18 * (20 * month + day)到18 * (20 * month + day + 1)"是把当月当天的所有数据放入sample中# 此时sample行是被填满的,所以是不断往sample列中填,这样就能解释"sample[:, day * 24: (day + 1) * 24]"了month_data[month] = sample # 把每个月的数据矩阵放到总的字典中# print(month_data) # 查看一下结果# (2)每十个小时为一笔资料,比如第0小时到第9小时,第1小时到第10小时。这样每个月数据就有(480-10+1=471)。
# 每笔资料10hours*18features,特征值为(12*471,9*18),目标值为12*471,1*1个(只有一行、一个PM2.5特征值,所以不乘以18)
x = np.empty([12 * 471, 18 * 9], dtype=float) # (列中包含了前九个小时9*18=162个数据)
y = np.empty([12 * 471, 1], dtype=float) # 行就是数据的笔,就是每份数据。
for month in range(12):for day in range(20):for hour in range(24):if day == 19 and hour > 14: # 最后一天hour到14就推不下去了哦,14-23为最后一组数据continuex[month * 471 + day * 24 + hour, :] = month_data[month][:, day * 24 + hour: day * 24 + hour + 9].reshape(1, -1)y[month * 471 + day * 24 + hour, 0] = month_data[month][9, day * 24 + hour + 9] # y只有一列
# print(x.shape) # (5652, 162)
# print(y.shape) # (5652, 1)# 正则化,y是PM2.5的值,就不正则化了
std = StandardScaler()
x = std.fit_transform(x)
# print(x)# 因为按原则情况,我们没有测试集,所以需要分割训练集x,y
x_test, x_train, y_test, y_train = train_test_split(x, y, test_size=0.25)
# print(x_test.shape)
# print(x_train.shape)
# print(y_test.shape)
# print(y_train.shape)
# (4239, 162)
# (1413, 162)
# (4239, 1)
# (1413, 1)# 数据处理完之后就可以开始训练模型了
# ****************************************************
# 这里没管分割
dim = 18 * 9 + 1 # 加一是把b看成w0
w = np.zeros([dim, 1]) # w是一个列向量,它特征有18*9+1个
x = np.concatenate((np.ones([12 * 471, 1]), x), axis=1).astype(float) # 加一列为1的列,与w0相乘可构成b
learning_rate = 100
iter_time = 1000
adagrad = np.zeros([dim, 1])
eps = 0.0000000001
for t in range(iter_time):loss = np.sqrt(np.sum(np.power(np.dot(x, w) - y, 2))/(471*12)) # 损失函数if(t%100 == 0):print(str(t) + ":" + str(loss))gradient = 2 * np.dot(x.transpose(), np.dot(x, w) - y) # dim*1adagrad += gradient ** 2 # 调整学习速率w = w - learning_rate * gradient / np.sqrt(adagrad + eps)
# np.save('weight.npy', w) # 存好训练后的权重
# ****************************************************
# sgd = SGDRegressor()
# sgd.fit(x_train, y_train)
# print(sgd.coef_)
# y_sgd_predict = sgd.predict(x_test)
# print('梯度下降均方误差:', mean_squared_error(y_test, y_sgd_predict))
# np.save('weight.npy', sgd.coef_) # 存好训练后的权重
# ****************************************************
# rg = Ridge(solver='sag')
# rg.fit(x_train, y_train)
# print(rg.coef_)
# y_sgd_predict = rg.predict(x_test)
# print('梯度下降均方误差:', mean_squared_error(y_test, y_sgd_predict))
# np.save('weight.npy', rg.coef_) # 存好训练后的权重
补:代码中梯度下降公式按下图编写

梯度下降介绍
学习速率大小与loss function迭代关系

Adagrad
gt代表梯度下降的值。
与传统学习速率不同,Adagrad除以了之前梯度的平方和,是的学习速率能根据需要变化。(学习速率太小,就会变大。太大就会变小。)
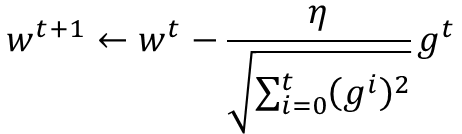

Stochastic Gradient Descent
这个梯度下降只参考了某个变量下降的方向,虽然loss function不一定在每次迭代中都下降,但人家运行速度快鸭。
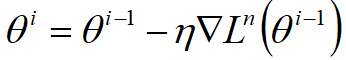
Feature Scaling
这个就是正则化,让每个特征值对训练的影响差不多相同。
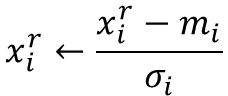
这篇关于DL2020_Day2_Gradient Descent的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







