chatglm3专题

关于springboot对接chatglm3-6b大模型的尝试
之前我们通过阿里提供的cloud ai对接了通义千问。cloud ai对接通义千问 那么接下来我们尝试一些别的模型看一下,其实这个文章主要是表达一种对接方式,其他的都大同小异。都可以依此方法进行处理。 一、明确模型参数 本次我们对接的理论支持来自于阿里云提供的文档。阿里云大3-6b模型文档 我们看到他其实支持多种调用方式,包括sdk和http,我本人是不喜欢sdk的,因为会有冲突或者版本之类的

chatglm3-6b下载时,需要下载哪些文件
在huggingface或modelscope上下载chatglm3-6b时,会发现有两种可执行文件,一种是.bin,一种是.safetensors,在使用的时候你如果直接用git命令git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git直接下载,你会发现它会把所有的文件都下载下来。 因为文件很大,就很占用硬盘空间。所以当你使用.

llama-factory微调chatglm3
一、定义 案例/多卡 二、实现 案例 1. 下载chatglm3-6b-32k模型 2. 配置数据集微调指令 CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli train \--stage sft \--do_train True \--model_name_or_path /home/chatglm3-6b-32k \--finetuning_type
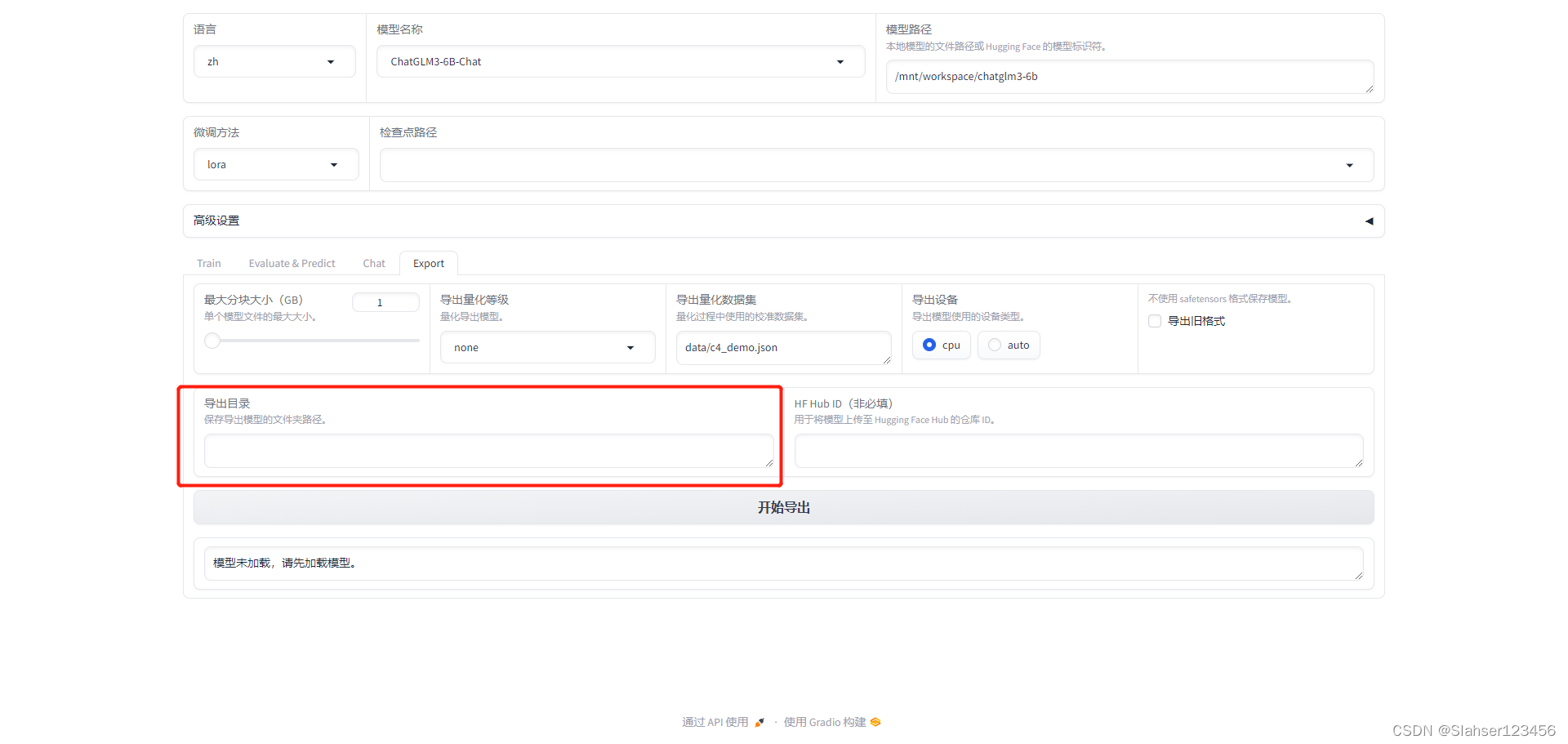
【记录】ChatGLM3-6B大模型部署、微调(二):微调
前言 上文记录了ChatGLM3-6B大模型本地化部署过程,本次对模型进行微调,目的是修改模型自我认知。采用官方推荐微调框架:LLaMA-Factory 安装LLaMA-Factory # 克隆项目 git clone https://github.com/hiyouga/LLaMA-Factory.git 安装依赖 # 安装项目依赖 cd LLaMA-Fa

12.实战私有数据微调ChatGLM3
实战私有数据微调ChatGLM3 实战私有数据微调ChatGLM3实战构造私有的微调数据集基于 ChatGPT 设计生成训练数据的 Prompt使用 LangChain + GPT-3.5-Turbo 生成训练数据样例训练数据解析、数据增强和持久化存储自动化批量生成训练数据集流水线提示工程(Prompt Engineering):强化返回格式,不断测试结果 实战私有数据微调 ChatGLM3
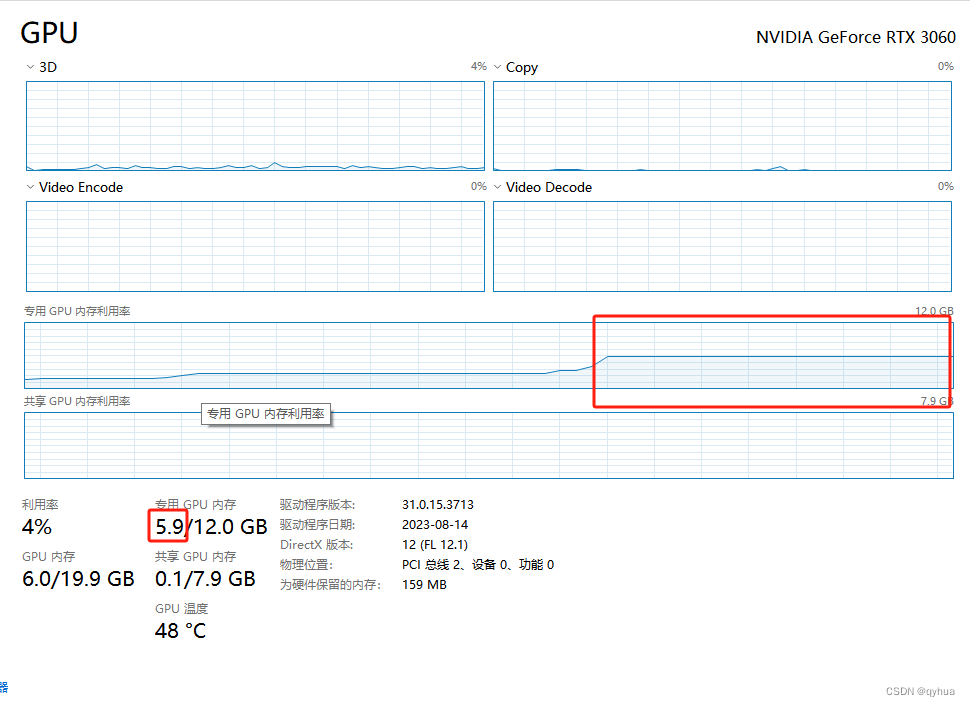
本地GPT-window平台 搭建ChatGLM3-6B
一 ChatGLM-6B 介绍 ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,新一代开源模型 ChatGLM3-6B 已发布,拥有10B以下最强的基础模型,支持工具调用(Function Call)、代码执行(Code Interpreter)、Agent 任务等功能,结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB
利用阿里云PAI平台微调ChatGLM3-6B
1.介绍ChatGLM3-6B ChatGLM3-6B大模型是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。 1.1 模型规模 模型规模通常用参数数量(parameters)来衡量。参数数量越多,模型理论上越强大,但也更耗费资源。以下是一些典型模型的参数数量对比: ChatTGLM3-6b:6 billion (60亿) 参数 GPT-3:175 billion (1750亿

基于ChatGLM3的本地问答机器人部署流程
基于ChatGLM3的本地问答机器人部署流程 前言一、确定文件结构1.新建文件夹储存本地模型2.下载源码和模型 二、Anaconda环境搭建1.创建anaconda环境2.安装相关库3.设置本地模型路径4.启动 三、构建本地知识库1.下载并安装postgresql2.安装c++库3.配置向量插件 四、线上运行五、 全部命令 前言 部署完成后视频演示 https://www.bi

chatglm3-6b小试
原本想在VMware中装个unbutu,再搞chatglm,但经过调研发现业内都是采用双系统来搞chat的开发。于是只好用rufus制作了一个ubuntu22.04的系统盘,你需要准备8G,因为制作好镜像后是7个多G。安装这里就不说了。 1 ubuntu环境 安装好ubuntu后,先更新apt的源 # vim是vi的扩展版本sudo apt install vimcd /etc/aptsu
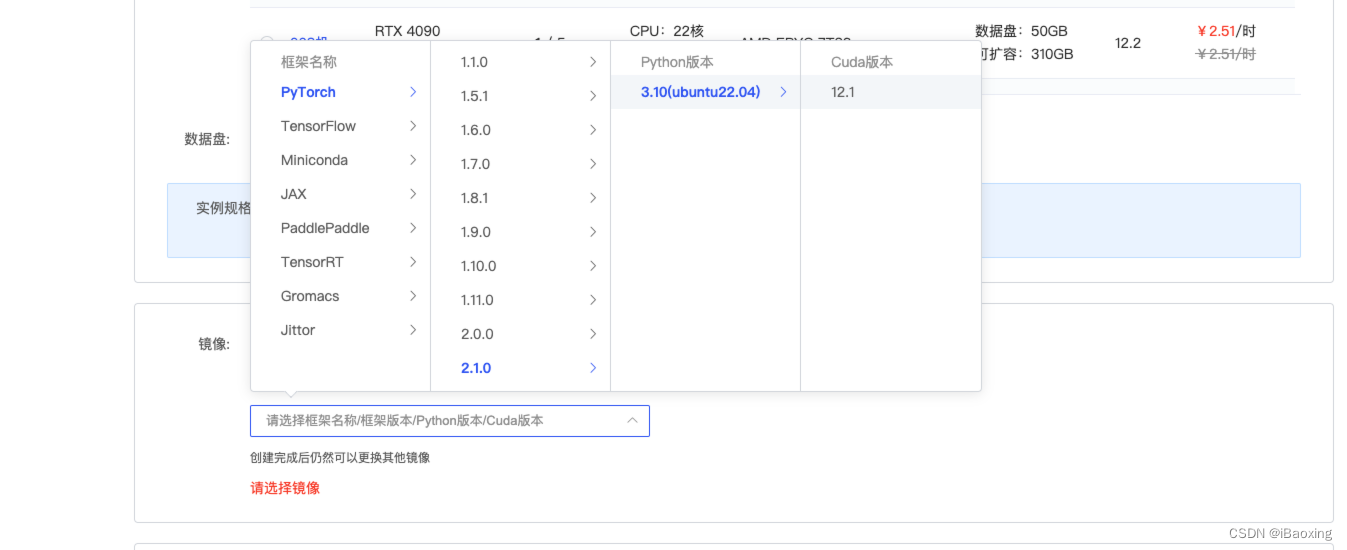
AutoDL搭建 ChatGLM3
租用新实例 这里选择的西北 B 区、RTX 409024GB 创建虚拟环境并激活 # 安装虚拟环境至数据盘conda create --prefix /root/autodl-tmp/envs/chatglm3-demo python=3.10# 激活虚拟环境conda activate /root/autodl-tmp/envs/chatglm3-demo 拉取ChatGLM3
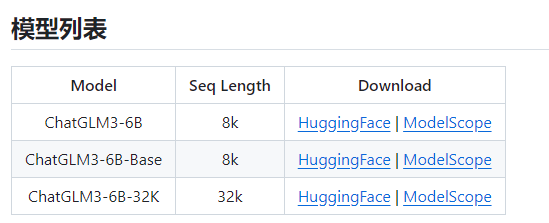
实战之快速完成 ChatGLM3-6B 在 GPU-8G的 INT4 量化和本地部署
ChatGLM3 (ChatGLM3-6B) 项目地址 https://github.com/THUDM/ChatGLM3 大模型是很吃CPU和显卡的,所以,要不有一个好的CPU,要不有一块好的显卡,显卡尽量13G+,内存基本要32GB+。 清华大模型分为三种(ChatGLM3-6B-Base,ChatGLM3-6B,ChatGLM3-6B-32K) 从上图也可以看到,ChatGLM3-

LLAMA-Factory微调chatglm3-6b出现KeyError: ‘instruction‘错误
之前我也遇到过这样的错误就是在LLAMA-Factory微调chatglm3-6b时报错KeyError: ‘instruction‘。那时候是因为数据现存在少部分格式不同,这才导致KeyError: 'instruction'错误。 但是候来又遇到了KeyError: ‘instruction‘,但这次没有格式不同的问题。 究其原因,LLAMA-Factory只能接受特定格式的数据集 {"

CHATGLM3应用指南(三)——模型微调
CHATGLM3的本地部署可以见博客:CHATGLM3应用指南(一)——本地部署_chatglm3需要多大内存-CSDN博客 一、微调数据集制作 数据集的形式如下图所示: 可使用下面代码对数据集格式调整 #! /usr/bin/env pythonprint('!!!!!')import jsonfrom collections import Counterfrom argp

AI大模型探索之路-训练篇22: ChatGLM3微调实战-从原理到应用的LoRA技术全解
系列篇章💥 AI大模型探索之路-训练篇1:大语言模型微调基础认知 AI大模型探索之路-训练篇2:大语言模型预训练基础认知 AI大模型探索之路-训练篇3:大语言模型全景解读 AI大模型探索之路-训练篇4:大语言模型训练数据集概览 AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化 AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理 AI大模型探索之路-训练篇7:大语言模型

LLM大语言模型(十五):LangChain的Agent中使用自定义的ChatGLM,且底层调用的是remote的ChatGLM3-6B的HTTP服务
背景 本文搭建了一个完整的LangChain的Agent,调用本地启动的ChatGLM3-6B的HTTP server。 为后续的RAG做好了准备。 增加服务端role:observation ChatGLM3的官方demo:openai_api_demo目录 api_server.py文件 class ChatMessage(BaseModel):# role: Litera

【工程记录】ChatGLM3-6B微调实践的更新说明
目录 写在前面1. 环境依赖更新2. 微调数据格式更新3. 微调方式更新4. 微调后模型推理验证方式更新 写在前面 仅作个人学习记录用。本文对上一篇 【工程记录】ChatGLM3-6B微调实践(Windows) 的内容进行更新与补充说明。 1. 环境依赖更新 注意:ChatGLM3-6B 微调示例需要 python>=3.10;除基础的 torch 依赖外,其他重要依赖与
LLM大语言模型(十二):关于ChatGLM3-6B不兼容Langchain 的Function Call
背景 基于本地的ChatGLM3-6B直接开发LangChain Function Call应用,发现其输出的action和action_input非常不稳定。 表现为生成的JSON格式回答非常容易出现不规范的情况,导致LangChain的Agent执行报错,或者进入死循环。 ChatGLM3-6B不兼容Langchain 的Function Call Langchain 作
LLM大语言模型(十三):ChatGLM3-6B兼容Langchain的Function Call的一步一步的详细转换过程记录
# LangChain:原始prompt System: Respond to the human as helpfully and accurately as possible. You have access to the following tools: Calculator: Useful for when you need to calculate math problems,

开源模型应用落地-chatglm3-6b-集成langchain(十)
一、前言 langchain框架调用本地模型,使得用户可以直接提出问题或发送指令,而无需担心具体的步骤或流程。通过LangChain和chatglm3-6b模型的整合,可以更好地处理对话,提供更智能、更准确的响应,从而提高对话系统的性能和用户体验。 二、术语 2.1. ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B

AI大模型探索之路-应用篇16:GLM大模型-ChatGLM3 API开发实践
目录 一、ChatGLM3-6B模型API调用 1. 导入相关的库 2. 加载tokenizer 3. 加载预训练模型 4. 实例化模型 5.调用模型并获取结果 二、OpenAI风格的代码调用 1. Openai api 启动 2. 使用curl命令测试返回 3. 使用Python发送POST请求测试返回 4. 采用GLM提供的chat对话方式 5. Embedding处理

AI大模型探索之路-应用篇15:GLM大模型-ChatGLM3-6B私有化本地部署
目录 前言 一、ChatGLM3-6B 简介说明 二、ChatGLM3-6B 资源评估 三、购买云服务器 四、git拉取GLM 五、pip安装依赖 六、运行测试 七、本地部署安装 总结 前言 ChatGLM3-6B 是 OpenAI 推出的一款强大的自然语言处理模型,它在前两代模型的基础上进行了优化和改进,具有更高的性能和更广泛的应用场景。本文将从技术角度对

llama-factory SFT系列教程 (三),chatglm3-6B 大模型命名实体识别实战
文章列表: llama-factory SFT系列教程 (一),大模型 API 部署与使用llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署 llama-factory SFT系列教程 (三),chatglm3-6B 命名实体识别实战 简介 利用 llama-factory 框架,基于 chatglm3-6B 模型 做命名实体识别任务; 本次实
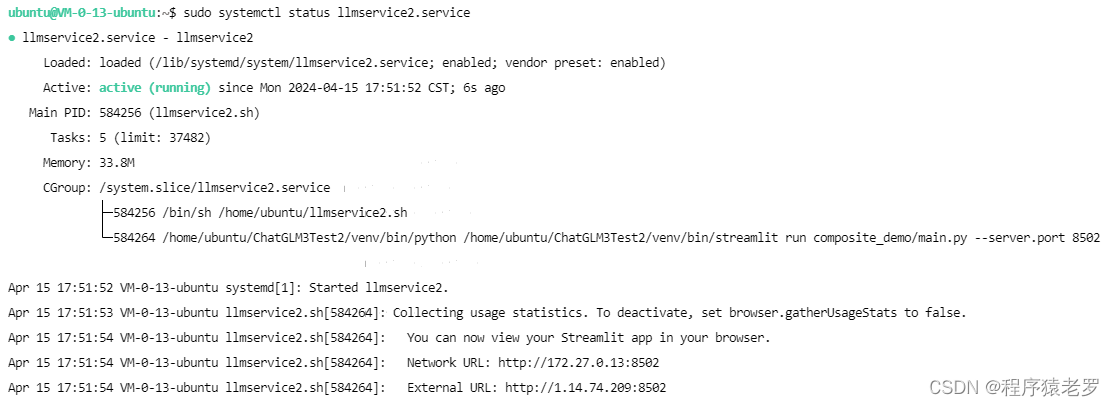
Ubuntu 部署ChatGLM3大语言模型
Ubuntu 部署ChatGLM3大语言模型 ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。 源码:https://github.com/THUDM/ChatGLM3 部署步骤 1.服务器配置 Ubuntu 20.04 8核(vCPU) 32GiB 5Mbps GPU NVIDIA T4 16GB 硬盘 100GiB CUDA 版本 12.2.2

开源模型应用落地-chatglm3-6b-批量推理-入门篇(四)
一、前言 刚开始接触AI时,您可能会感到困惑,因为面对众多开源模型的选择,不知道应该选择哪个模型,也不知道如何调用最基本的模型。但是不用担心,我将陪伴您一起逐步入门,解决这些问题。 在信息时代,我们可以轻松地通过互联网获取大量的理论知识和概念。然而,仅仅掌握理论知识并不能真正帮助我们成长和进步。实践是将理论知识转化为实际技能和经验的关键。 本章将学习如何在低成本下
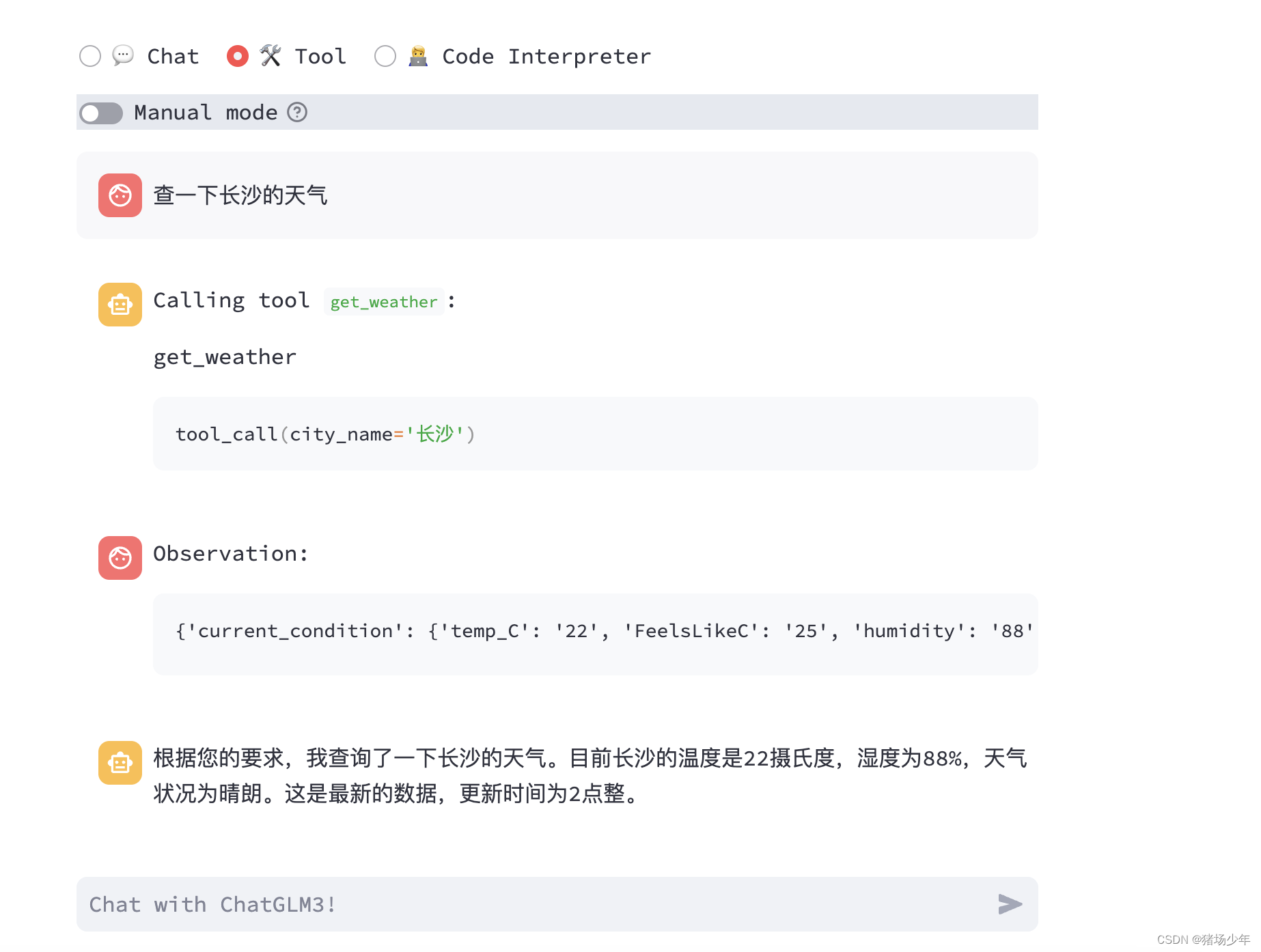
ChatGLM3初体验
mac本地化部署ChatGLM3 写在前面环境准备1. python环境2. 安装第三方依赖torch3.下载模型 代码准备1.clone代码 run效果 写在前面 建议直接去看官方文档 https://github.com/THUDM/ChatGLM3?tab=readme-ov-file 环境准备 1. python环境 python -V## 3.11.4 2
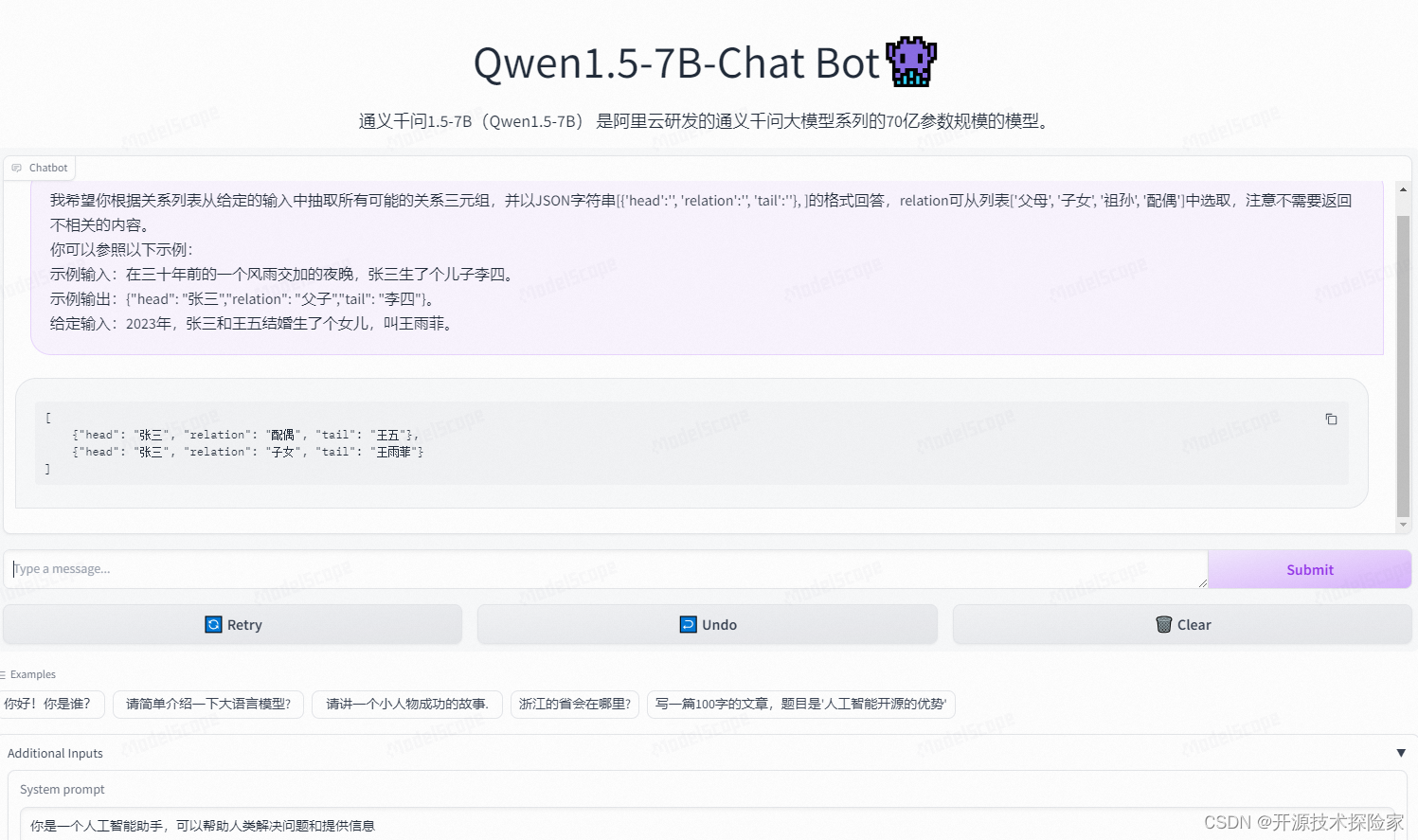
开源模型应用落地-chatglm3-6b-zero/one/few-shot-入门篇(五)
一、前言 Zero-Shot、One-Shot和Few-Shot是机器学习领域中重要的概念,特别是在自然语言处理和计算机视觉领域。通过Zero-Shot、One-Shot和Few-Shot学习,模型可以更好地处理未知的情况和新任务,减少对大量标注数据的依赖,提高模型的适应性和灵活性。这对于推动人工智能在现实世界中的应用具有重要意义,尤其是在面对数据稀缺、标注成本高昂或需要快速适应新环境