本文主要是介绍CHATGLM3应用指南(三)——模型微调,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CHATGLM3的本地部署可以见博客:CHATGLM3应用指南(一)——本地部署_chatglm3需要多大内存-CSDN博客
一、微调数据集制作
数据集的形式如下图所示:

可使用下面代码对数据集格式调整
#! /usr/bin/env python
print('!!!!!')
import json
from collections import Counter
from argparse import ArgumentParser
import osparser = ArgumentParser()
parser.add_argument("--path", type=str, required=True)args = parser.parse_args()
print(args.path)
print('!!!!!')
with open(args.path ,encoding="utf-8") as f:data = [json.loads(line) for line in f]train_examples = [{"prompt": x['content'],"response": x['summary'],
} for x in data]os.makedirs("formatted_data", exist_ok=True)with open("formatted_data/EE_term_define_2.jsonl", "w",encoding="utf-8") as f:for e in train_examples:f.write(json.dumps(e, ensure_ascii=False) + "\n")
二、微调模型的训练
运行finetune_pt.sh文件,使用命令
sh finetune_pt.sh
二、微调模型的推理
(1)在终端输入“jupyter notebook”

跳转到浏览器的jupyter
(2)创建以下的.ipynb文件
import argparse
from transformers import AutoConfig, AutoModel, AutoTokenizer
import torch
import os# parser = argparse.ArgumentParser()
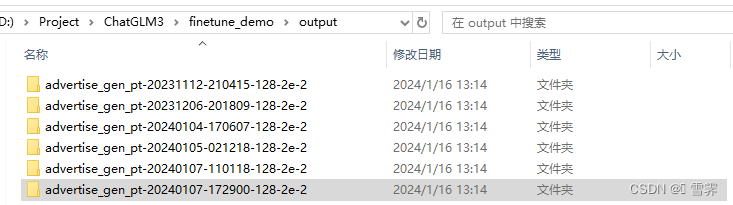
# parser.add_argument("--pt-checkpoint", type=str, default=r"D:\Jupyter_file\ChatGLM3\chatgalm3-6b\finetune_demo\output\advertise_gen_pt-20231206-201809-128-2e-2\checkpoint-1000", help="The checkpoint path")
# parser.add_argument("--model", type=str, default=r"D:\Jupyter_file\ChatGLM3\chatgalm3-6b", help="main model weights")
# parser.add_argument("--tokenizer", type=str, default=None, help="main model weights")
# parser.add_argument("--pt-pre-seq-len", type=int, default=128, help="The pre-seq-len used in p-tuning")
# parser.add_argument("--device", type=str, default="cuda")
# parser.add_argument("--max-new-tokens", type=int, default=128)args={'pt_checkpoint':r"D:\Project\ChatGLM3\finetune_demo\output\advertise_gen_pt-20231206-201809-128-2e-2\checkpoint-1000",'model':r"D:\Project\LLM\Model\llm\chatglm3",'tokenizer':None,'pt-pre-seq-len':128,'device':"cuda",'max_new_tokens':128}
if args['tokenizer'] is None:args['tokenizer'] = args['model']if args['pt_checkpoint']:tokenizer = AutoTokenizer.from_pretrained(args['tokenizer'], trust_remote_code=True)config = AutoConfig.from_pretrained(args['model'], trust_remote_code=True, pre_seq_len=128)model = AutoModel.from_pretrained(args['model'], config=config, trust_remote_code=True)prefix_state_dict = torch.load(os.path.join(args['pt_checkpoint'], "pytorch_model.bin"))new_prefix_state_dict = {}for k, v in prefix_state_dict.items():if k.startswith("transformer.prefix_encoder."):new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = vmodel.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
else:tokenizer = AutoTokenizer.from_pretrained(args['tokenizer'], trust_remote_code=True)model = AutoModel.from_pretrained(args['model'], trust_remote_code=True)model = model.to(args['device'])while True:prompt = input("Prompt:")inputs = tokenizer(prompt, return_tensors="pt")inputs = inputs.to(args['device'])response = model.generate(input_ids=inputs["input_ids"], max_length=inputs["input_ids"].shape[-1] + args['max_new_tokens'])response = response[0, inputs["input_ids"].shape[-1]:]print("Response:", tokenizer.decode(response, skip_special_tokens=True))(3)修改“pt_checkpoint”为自己训练好的微调模型的“output”文件夹,修改“model”为chatglm3—6b底座模型的存放路径。
(4)确认所使用的内核,如果不对应,可以点击“内核” —>“更换内核” (5)点击运行,等待一段时间后,在prompt输入提示词,即可出现回答。
(5)点击运行,等待一段时间后,在prompt输入提示词,即可出现回答。

这篇关于CHATGLM3应用指南(三)——模型微调的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




