本文主要是介绍Ubuntu 部署ChatGLM3大语言模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Ubuntu 部署ChatGLM3大语言模型
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的对话预训练模型。
源码:https://github.com/THUDM/ChatGLM3
部署步骤
1.服务器配置
Ubuntu 20.04
8核(vCPU) 32GiB 5Mbps GPU NVIDIA T4 16GB 硬盘 100GiB
CUDA 版本 12.2.2/Driver 版本 535.161.07/CUDNN 版本 8.9.4
查看CUDA版本:nvidia-smi
2.程序和模型文件
程序:
程序保存目录/home/ubuntu/ChatGLM3Test2,注意目录权限要可写
https://github.com/THUDM/ChatGLM3
模型:
建议从魔塔下载
模型保存目录/home/ubuntu/THUDM
https://www.modelscope.cn/models/ZhipuAI/chatglm3-6b/summary
注意:记得修改程序里面的模型目录
文件:composite_demo/client.py 第18行
3.Python环境
服务器安装Python3.10.0,参考https://blog.csdn.net/luobowangjing/article/details/137726093
安装Python3.10.0虚拟环境,参考https://blog.csdn.net/luobowangjing/article/details/131081787
cd /home/ubuntu/ChatGLM3Test2
#安装虚拟环境依赖
pip install virtualenv#*创建虚拟环境
virtualenv venv
#*激活虚拟环境
source venv/bin/activate#退出虚拟环境
deactivate
4.安装依赖包
进入虚拟环境进行操作
前面安装虚拟环境时已经进入了。
#设置pip源设置为清华大学的镜像,如果已设置就不用设置查看镜像源使用命令pip config get global.index-url
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
#如果版本是24.0就不用更新
python -m pip install --upgrade pip#*安装项目依赖
pip install -r requirements.txt
#*安装Demo依赖,注意修改requirements.txt里面的huggingface_hub==0.19.4,否则运行demo会报错
pip install -r composite_demo/requirements.txt
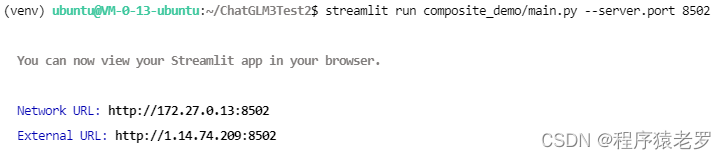
5.运行测试
streamlit run composite_demo/main.py --server.port 8502
6.配置服务器自启动
6.1.设置启动脚本 llmservice2.sh,vi llmservice2.sh,退出:wq
#!/bin/sh
cd /home/ubuntu/ChatGLM3Test2
source venv/bin/activate
streamlit run composite_demo/main.py --server.port 8502
6.2.新建启动服务
路径:/usr/lib/systemd/system/llmservice2.service
[Unit]
Description=llmservice
After=network.target[Service]
ExecStart=/home/ubuntu/llmservice2.sh[Install]
WantedBy=default.target
7.服务自启动
sudo systemctl enable llmservice2.service
sudo systemctl start llmservice2.service
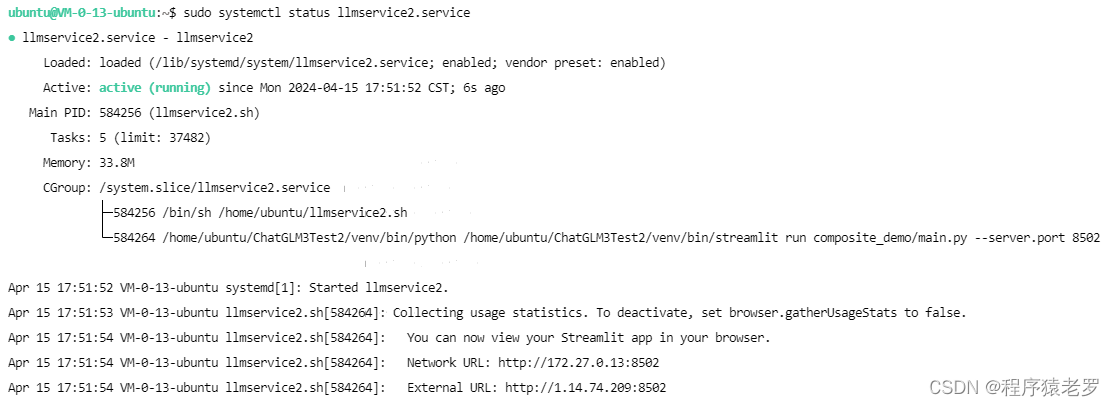
sudo systemctl status llmservice2.service
sudo systemctl stop llmservice2.service
sudo systemctl restart llmservice2.service
8.启动成功截图
这篇关于Ubuntu 部署ChatGLM3大语言模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








