本文主要是介绍llama-factory微调chatglm3,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、定义
- 案例/多卡
二、实现
- 案例
1. 下载chatglm3-6b-32k模型
2. 配置数据集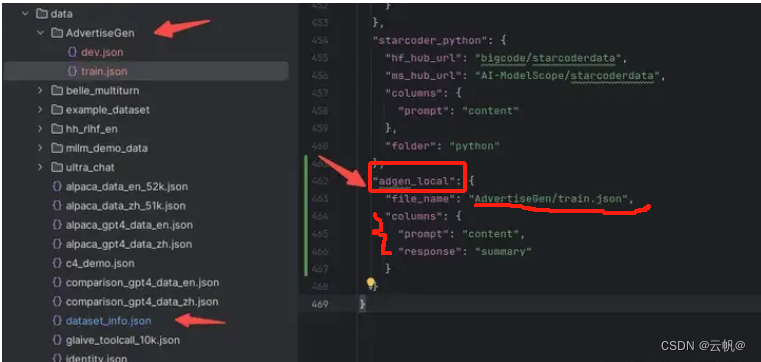
- 微调指令
CUDA_VISIBLE_DEVICES=0,1 llamafactory-cli train \--stage sft \--do_train True \--model_name_or_path /home/chatglm3-6b-32k \--finetuning_type lora \--template chatglm3 \--dataset_dir ./data \--dataset adgen_local \--cutoff_len 1024 \--learning_rate 5e-05 \--num_train_epochs 3.0 \--max_samples 1000 \--per_device_train_batch_size 2 \--gradient_accumulation_steps 8 \--lr_scheduler_type cosine \--max_grad_norm 1.0 \--logging_steps 5 \--save_steps 100 \--warmup_steps 0 \--optim adamw_torch \--output_dir saves/ChatGLM3-6B/lora/sft \--fp16 True \--lora_rank 8 \--lora_alpha 16 \--lora_dropout 0.1 \--lora_target query_key_value \--plot_loss True

4. 推理
CUDA_VISIBLE_DEVICES=0 llamafactory-cli chat \--model_name_or_path /home/chatglm3-6b-32k \--adapter_name_or_path ./saves/ChatGLM3-6B/lora/sft \--template chatglm3 \--finetuning_type lora

5. 合并并导出
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \--model_name_or_path /home/chatglm3-6b-32k \--adapter_name_or_path ./saves/ChatGLM3-6B/lora/sft \--template chatglm3 \--finetuning_type lora \--export_dir megred-model-chatglm3 \--export_size 2 \--export_device auto \--export_legacy_format False

这篇关于llama-factory微调chatglm3的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







