本文主要是介绍【统计学】Top-down自上而下的角度模型召回率recall,精确率precision,特异性specificity,模型评价,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在学 logistic regression model,又遇见了几个之前的老面孔。
召回率recall, 精确率precision,特异性spcificity,准确率accuracy,True positive rate,false positive rate等等名词在学习之初遇到的困难在于,理解各自的意思,对于评估模型的意义,以及将相关名词联系在一起。也是初学者,谨希望给大家学习时提供一些思路。
1.召回率recall, 精确率precision,特异性spcificity,准确率accuracy这些指标分别让我们了解什么(通俗版)
想象我们有一个样本集,其中有我们需要的数据,以及我们不需要的数据;或者想象一个数据集包括不同的人脸,有笑脸,哭脸、面无表情脸,我们其中需要识别的是笑脸
准确率accuracy:做出正确预测的能力
你能做出正确的预测的概率(我们测试的模型识别出是笑脸的数据和不是笑脸的数据其中识别正确的部分)
召回率recall: 对需要识别的数据是否敏感
另外一个名字是敏感性sensitivity,代表给你需要识别的正的样本中,你能识别的部分;对正确的样本识别能力,是否能有效地捕捉我们所需要的样本?(给你所有的笑脸图像,你能识别的部分)(真实情况中,我们并不知道有多少数据是笑脸,我们需要知道的是模型能否有效地将尽可能多地笑脸识别出来(从茫茫数据海中捞出来,带回来,召回来),因此理解成召回率)
精确率precision识别判断准确的能力,你选出正确的部分有多少是确实正确的,也叫Hit rate(你说这些是笑脸图,那么我需要知道里面确实是笑脸图的部分;精确到小数点后x位,证明着x位之前的数字都是对的)How many patients predicted as having stroke really has stroke.
特异性specificity 识别非样本的能力specific翻译成中文可以是具体、明确、独特、特定的,代表你指出的不属于我要找的样本中,有多少确实不属于?(确实不是笑脸的样本中你能识别出确实不属于笑脸图的部分;不要往“你能识别出不是笑脸图的,确实不属于笑脸图的部分“或者”不属于笑脸图这个判断正确的概率“去想,会导致你对分母及计算方式的误解)
通过上面的学习,先把中文和英文对应上,然后咱们再来区分
1.(i)精确、具体、敏感之间怎么区分
总结下,精确——做出(正确)判断正确的概率,
敏感——对正确集做出正确分类与识别的概率
具体——对错误集进行正确分类与识别的概率
Specificity 与 Sensitivity(敏感性,也称为 True Positive Rate 或 Recall)一起使用可以提供全面的模型性能评估。在某些应用中,需要权衡 Specificity 和 Sensitivity,以确定模型的最佳工作点,具体取决于问题的重要性和应用背景。
1.(ii) 引入Confusion Matrix
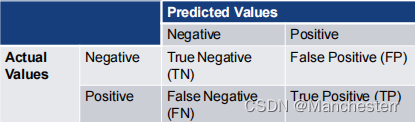
- Accuracy = TP+TN/(TP+TN+FP+FN) %
- Recall/True Positive Rate/Sensitivity = TP/(TP+FN)
- Specificity = TN/(TN+FP)
- Precision/Hit Rate (of Event) = TP/(TP+FP)
1.(iii) TP, TN, FP, FN Rate区分及计算方式
这四个指标出现在Confusion Matrix里面,因为计算方式与之前认识的四个指标中部分相同,所以也同样会用于评价模型的效果
Negative和Positive代表的是模型做出的判断,因为列代表的是predicted values即模型的结果,所以一个列是N一列是P
True 和False 代表的是该判断是错还是对,因为行代表的是Actual values,一行必定有一个判断正确,一个判断错误,所以对角线上的T或P值会相同
这四个指标从中文理解比较方便,比如FN假阴性,做出了阴性的假定但是错了, 实际上它是阳性的Positive的;FP做出了阳性的假定但是这个假定是错的,实际上它是阴性的
Rate这个理解比较重要,规律就是除以实际的T或者P。比如FNR就是对于
True Positive rate 真阳性= TP/Actual Yes=TP/(TP+FN)
True Negative rate 真负类= TN/Actual No=TN/(TN+FP)
False Positive rate 假阳性= FP/Actual No=FP/(FP+TN)
False Negative rate假阴性 = FN/Actual Yes=FN/(FN+TP)
跟之前学习的Recall, precision, accuracy, specificity联动一下
TP rate = recall, sensitivity
TN rate = specificity
对了,还记得统计学学过的两类错误吗,Type1 某个人怀孕了你测不出来(原假设为真时却错误地拒绝了原假设,弃真)=FP rate
Type2 某个人没怀孕,你说它怀孕了(原假设为假时却错误地未能拒绝原假设,被坏人骗了)= FN Rate
ps: 在某些情况下,降低 Type 2 error 的重要性更大,特别是当未能检测到某种效应或差异可能具有严重后果时。例如,在医学诊断中,未能检测到疾病可能导致病人未能获得及时的治疗,从而增加了危险。所以FN rate很重要。
这篇关于【统计学】Top-down自上而下的角度模型召回率recall,精确率precision,特异性specificity,模型评价的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








