召回专题

NLP-信息抽取-NER-2015-BiLSTM+CRF(一):命名实体识别【预测每个词的标签】【评价指标:精确率=识别出正确的实体数/识别出的实体数、召回率=识别出正确的实体数/样本真实实体数】
一、命名实体识别介绍 命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型。是信息提取, 问答系统, 句法分析, 机器翻译等应用领域的重要基础工具, 在自然语言处理技术走向实用化的过程中占有重要地位. 包含行业, 领域专有名词, 如人名, 地名, 公司名, 机构名, 日期, 时间, 疾病名, 症状名, 手术名称, 软

自然语言处理-应用场景-聊天机器人(三):MaLSTM【基于FAQ 的问答系统】【文本向量化-->问题召回(利用PySparNN句子相似度计算海选相似问题)-->问题排序(深度学习:句子相似度计算)】
一、问答机器人介绍 1. 问答机器人 在前面的课程中,我们已经对问答机器人介绍过,这里的问答机器人是我们在分类之后,对特定问题进行回答的一种机器人。至于回答的问题的类型,取决于我们的语料。 当前我们需要实现的问答机器人是一个回答编程语言(比如python是什么,python难么等)相关问题的机器人 2. 问答机器人的实现逻辑 主要实现逻辑:从现有的问答对中,选择出和问题最相似的问题,

准确率,召回率,mAP,ROC,AUC,特异性,敏感性,假阴性,假阳性
P/R和ROC是两个不同的评价指标和计算方式,一般情况下,检索用准确率、召回率、F1、AP和mAP,分类、识别等用ROC和AUC(特异性和敏感性是ROC当中的一个部分)。 准确率、召回率、F1、AP和mAP这几个指标需要依次看,不然直接看AP和mAP看不明白。而ROC和AUC可以直接看不需要看前面的指标。 PR曲线和ROC曲线上点都是对预测的数据进行划分,首先都是按照置信度排序,而PR

知识图谱问答召回机制-llm-graph-builder
背景 以Neo4j开源的 llm-graph-builder (以下简称 LGB)为例,说明 graph + RAG的模式下,如何进行知识的召回操作。 原理说明 graph + RAG模式下,依旧保持了RAG的思想,使用了向量作为语义召回的手段。 在 LGB 中,对于用户提出的问题,系统首先会将问题进行 Embedding 操作,从而得到问题的向量表示。使用问题的向量表示,去neo4j中召
推荐算法实战五-召回(下)
一、FM的召回功能 (一)打压热门物料 FM主要应用于U2I召回场景,正样本采用与用户正向交互过的样本。负样本来源于两个途径,一个是随机采样,一个是曝光但未点击的负向物料。由于热门物料曝光率高,因此正负样本中热门物料参与度都不小,为了确保推荐结果的多样性,对正负样本分别采取不同的热门物料打压策略。 1、热门物料在正样本中要降采样 降低热门物料被选为正样本的概率,曝光率越高,选为正样本的概率
准确率、精确率、召回率、F1(F-Measure)都是什么?
机器学习ML、自然语言处理NLP、信息检索IR等领域,评估(Evaluation)是一个必要的工作,而其评论价值指标往往有如下几点: 准确率 Accuracy; 精准率 Precision; 召回率 Recal; F1-Measure; TP: True Positive 把正的判断为正的数目True Positive,判断正确,且判为了正,即正的预测为正的; FN:False N
【中文】PDF文档切分\切片\拆分最优方案-数据预处理阶段,为后续导入RAG向量数据库和ES数据库实现双路召回
目的 将PDF文档拆开,拆开后每个数据是文档中的某一段,目的是保证每条数据都有较完整的语义,并且长度不会太长 项目自述 看了很多切分项目,包括langchain、Langchain-Chatchat、、Chinese-LangChain、LangChain-ChatGLM-Webui、ChatPDF、semchunk等等,效果还行,但是不够完美,毕竟他们的对"\n"的优先级设置的较高,使用p

混淆矩阵-召回率、精确率、准确率
混淆矩阵 1 混淆矩阵2 混淆矩阵指标2.1 准确率2.2 精确率2.3 召回率2.4 特异度2.4 假正率2.5 假负率2.6 F1 分数 3 总结 1 混淆矩阵 混淆矩阵是一种用于评估分类模型性能的重要工具。它通过矩阵形式清晰地展示了模型对样本进行分类的结果,帮助我们理解模型在不同类别上的表现。 ————预测为正类预测为负类实际为正类True Positive (TP)Fa

苹果发布云AI系统;谷歌警告0day漏洞被利用;微软紧急推迟 AI 召回功能;劫持活动瞄准 K8s 集群 | 网安周报0614
苹果发布私有云计算,开创 AI 处理新时代,隐私保护再升级! 苹果宣布推出一个名为“私有云计算”(PCC)的“开创性云智能系统”,该系统专为在云中以保护隐私的方式处理人工智能(AI)任务而设计。 这家科技巨头将 PCC 描述为“为云人工智能计算大规模部署的最先进安全架构”。 PCC 与新的生成式人工智能(GenAI)功能的到来相吻合——统称为苹果智能,或简称 AI——这是 iPhone

【推荐算法】召回模型总结
文章目录 1、传统召回算法2、向量化召回统一建模架构2.1、如何定义正样本2.2、重点关注负样本2.3、召回生成Embedding:要求用户、物料解耦2.4、如何定义优化目标2.4.1、Softmax Loss、NCE Loss、NEG Loss2.4.2、Sampled Softmax Loss2.4.3、Pairwise Loss 3、Word2Vec:转为Item2Vec4、Airb

微软无所不知的人工智能召回功能“Recall”被推迟,将不会与 Copilot Plus PC 一起提供
微软计划下周推出新的 Copilot Plus 个人电脑,取消其备受争议的 Recall 功能,该功能可以截取您在这些新笔记本电脑上所做的所有操作。该软件制造商推迟了 Recall,以便可以通过 Windows Insider 程序对其进行测试,此前该公司最初承诺将 Recall 作为一项可选功能提供,并进行额外的安全改进。 喜好儿网 微软在更新的博客文章中表示:“我们正在调整 Recal

基于用户的协同过滤推荐算法单机版代码实现(包含输出用户-评分矩阵模型、用户间相似度、最近邻居、推荐结果、平均绝对误差MAE、查准率、召回率)
基于用户的协同过滤推荐算法单机版代码实现(包含输出用户-评分矩阵模型、用户间相似度、最近邻居、推荐结果、平均绝对误差MAE、查准率、召回率) 一、开发工具及使用技术 MyEclipse10、jdk1.7、mahout API、movielens数据集。 二、实现过程 1、定义用户-电影评分矩阵: /** * 用户-电影评分矩阵工具类 */ public class DataMo
推荐系统学习笔记(四)--基于向量的召回
离散特征处理 离散特征:性别,国籍,英文单词,物品id,用户id 处理: 建立字典:eg:china = 1 向量化:eg:one-hot /embedding(低维稠密向量) one-hot--适合低维度 例如: 性别:男,女 字典:男 = 1,女 = 2 one-hot: 未知[0 , 0] 男 [1 , 0] 女 [0 , 1]


【经典论文阅读10】MNS采样——召回双塔模型的最佳拍档
这篇发表于2020 WWW 上的会议论文,提出一种MNS方式的负样本采样方法。众所周知,MF方法难以解决冷启动问题,于是进化出双塔模型,但是以双塔模型为基础的召回模型的好坏十分依赖负样本的选取。为了解决Batch内负样本带来的选择性偏差问题,本文提出MNS方法融合了批采样和均匀采样。实验表明,配合这种负样本的采样的双塔模型的召回能力得到了明显提升。 1. 贡献 本文提出一种新颖的负
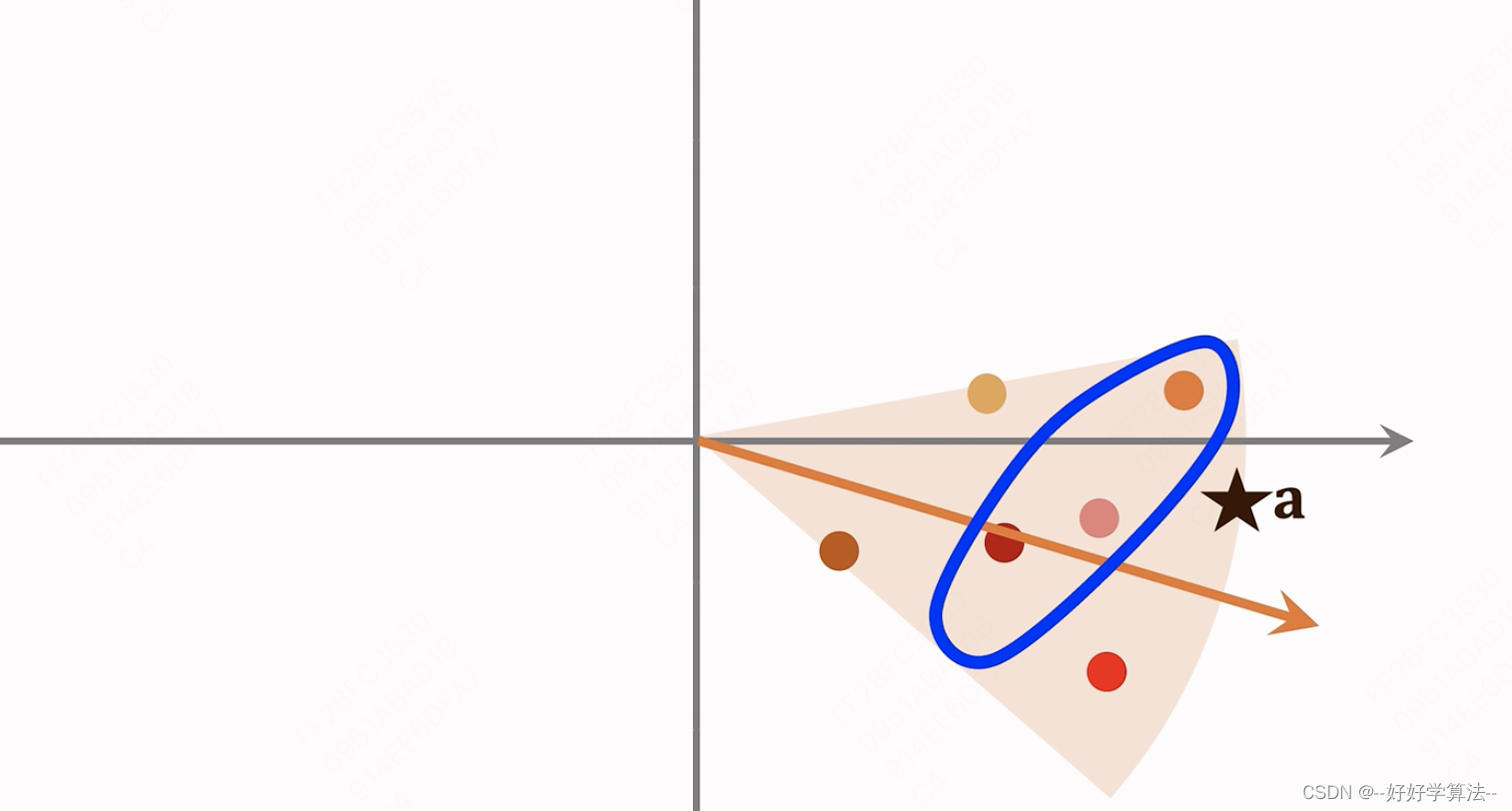
【AI】图示:精确度(查准率)Precision、召回率(查全率)Recall
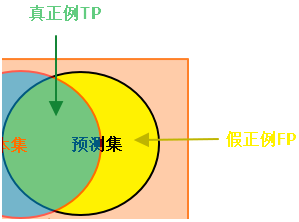
对Precision、Recall的直译是“精确度”和“召回率”,第一次接触这两个词,很难从字面上知道它们的含义。而翻译成“查准率”和“查全率”就比较好理解,下面统一使用“查准率”和“查全率”。 1、真假正负例 真正例(True Positive, TP):预测值和真实值都为1 假正例(False Positive,FP):预测值为1,真实值为0 真负例(True Negative,TN)

YOLOv3的NMS参数调整对模型的准确率和召回率分别有什么影响?
YOLOv3中的非极大值抑制(Non-Maximum Suppression, NMS)是一种关键的后处理步骤,用于从模型的预测中去除重叠的边界框,从而提高检测的准确性。NMS参数的调整直接影响到模型的准确率(Precision)和召回率(Recall),具体如下: 1. NMS阈值(`nms_thresh`): - 提高NMS阈值:会减少被抑制的边界框数量,从而保留更多的边界框。这可能会
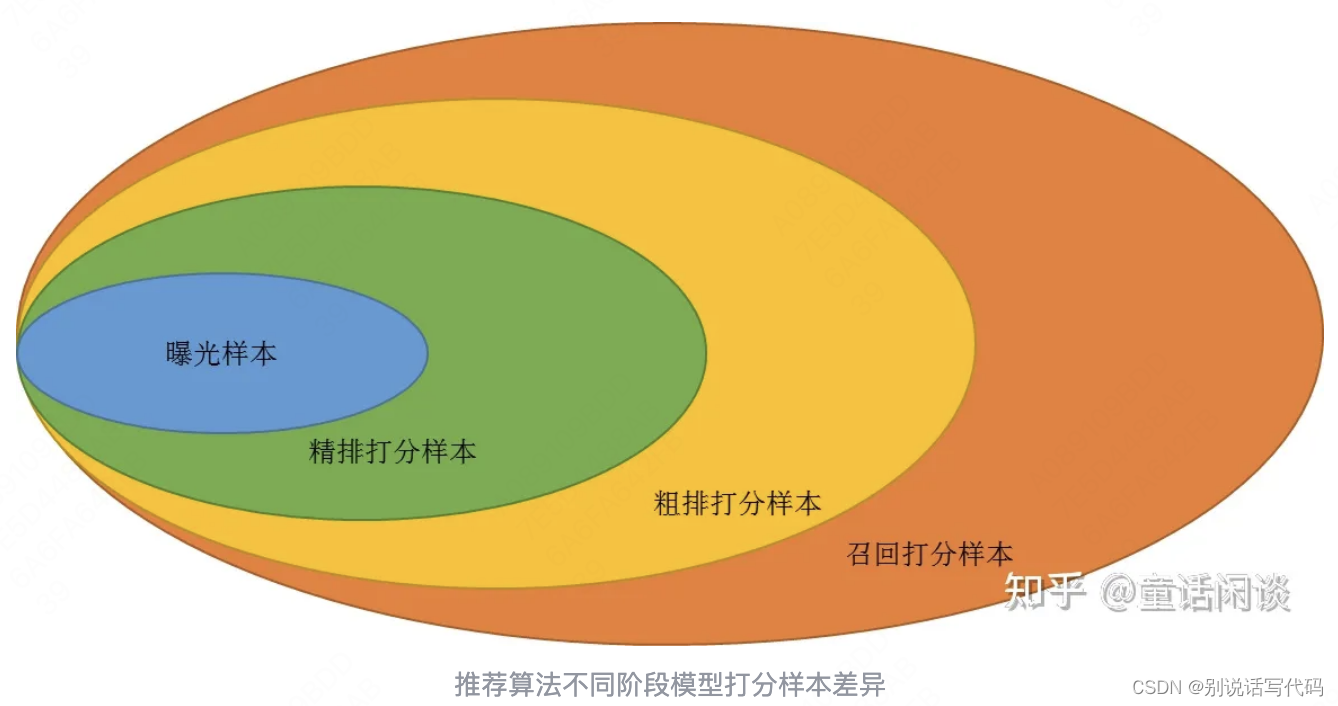
双塔模型在召回和粗排的区别
答案参考:推荐系统中,双塔模型用于粗排和用于召回的区别有哪些? - 知乎 召回和粗排在不同阶段面临样本不一样,对双塔来说样本分布差异会使召回和粗排采取不一样的方式。召回打分空间是全部item空间,曝光只有很少一部分,同时双塔召回只是多路召回的一种,因此双塔会从几个方面优化: 召回负样本选择,会采用一些策略进行负样本采样。 粗排打分空间已经变小,曝光样本和打分样本差异相对较小,曝光对粗
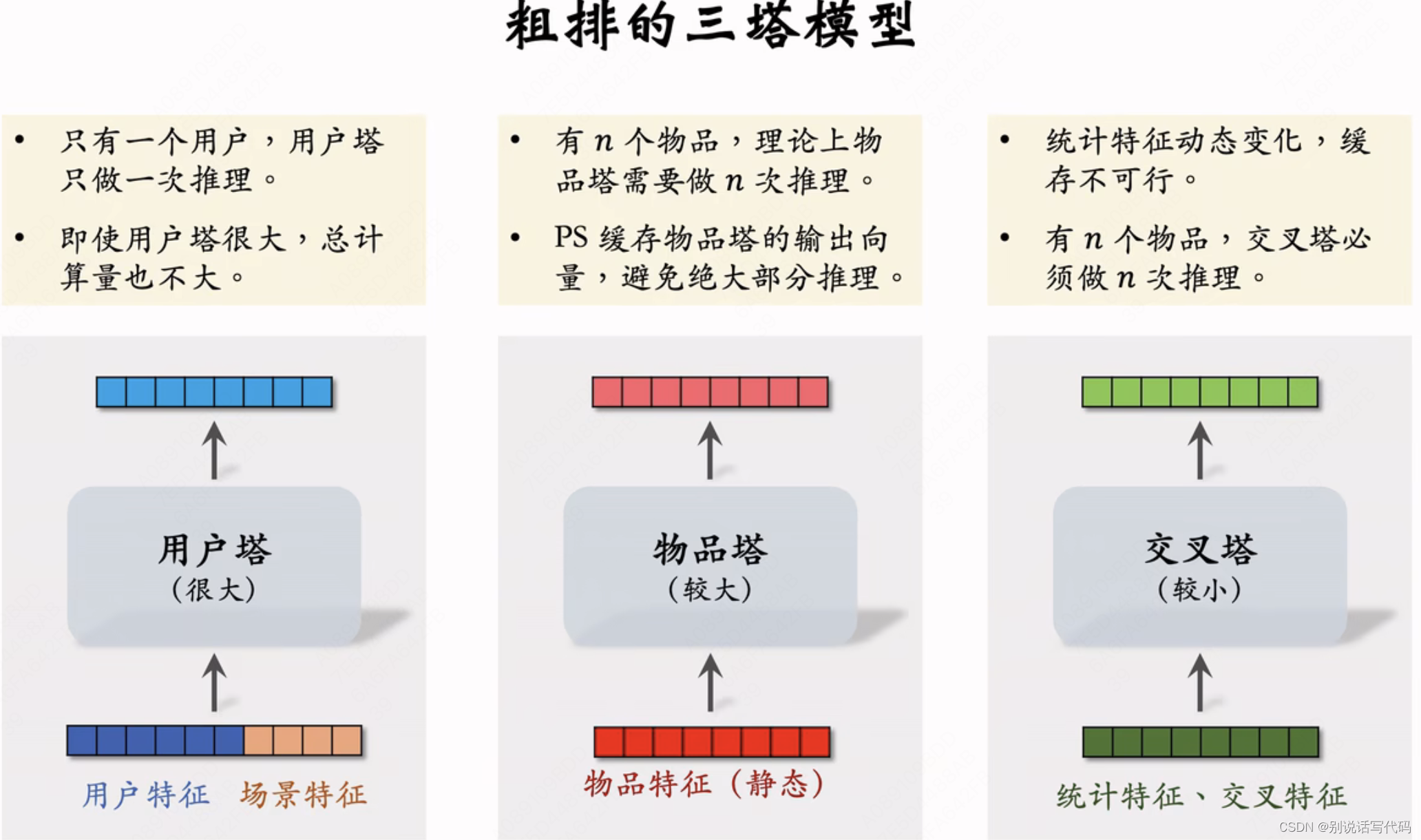
特征的前期融合与后期融合在召回、粗排、精排应用
前期融合:先对所有特征做concat,再输入DNN,一般常见于精排模型 特点:线上推理代价大,若有n个候选item需要做n次模型计算 后期融合:把用户和物品特征分别输入不同的神经网络,不对用户和物品做融合,常见于召回双塔 特点:线上计算量小,用户塔只需要做一次线上推理,计算用户表征a,物品表征b事先存储在向量数据库,物品塔在线上不做推理;预估准确性不如精排模型。 粗排模型:一般介于
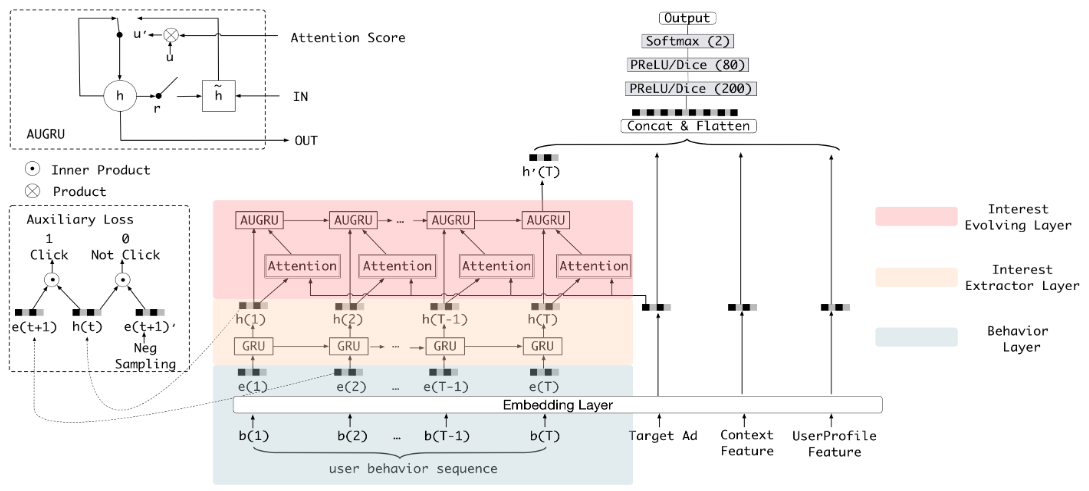

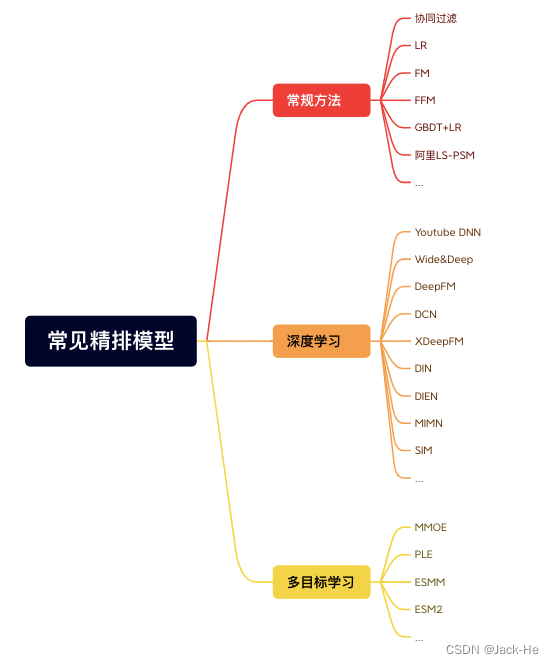
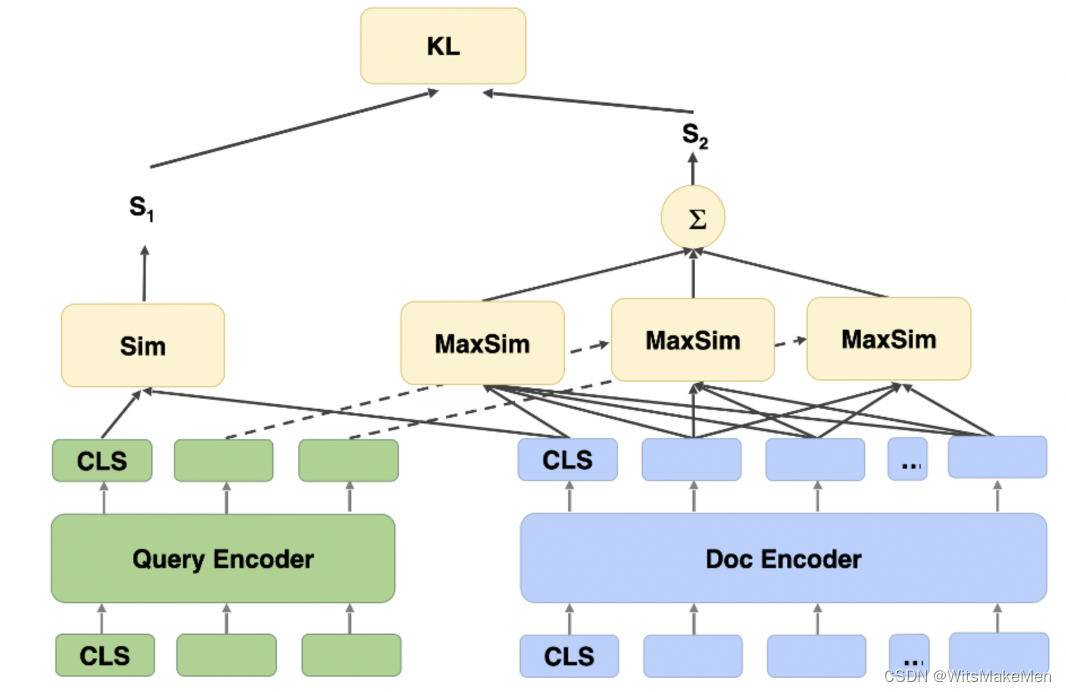
浅谈互联网搜索之召回
一、背景 在搜索系统中,一般会把整个搜索系统划分为召回和排序两大子系统。本文会从宏观上介绍召回系统,并着重介绍语义召回。谨以此文,希望对从事和将要从事搜索行业的工作者带来一些启发与思考。 二、搜索系统召回方法 不同于推荐系统,检索系统是在输入query的前提下,快速召回与query相关的文本,特点为要求是快,注重召回轻准确。注意,在工业界考虑到用户体验,往往要求百毫秒以内完成召回,甚至在地图、电
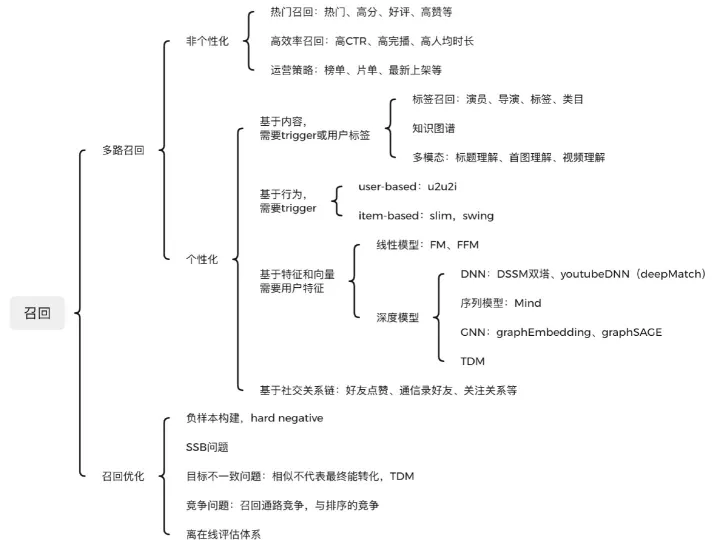
推荐算法架构 :召回(1)
召回模块面对几百上千万的推荐池物料规模,候选集十分庞大。由于后续有排序模块作为保障,故不需要十分准确,但必须保证不要遗漏和低延迟。目前主要通过多路召回来实现,一方面各路可以并行计算,另一方面取长补短。召回通路主要有非个性化和个性化两大类。 1 推荐算法整体架构 1.1 推荐算法意义 随着互联网近十年来的大力发展,用户规模和内容规模均呈现迅猛发展。用户侧日活过亿早已不是什么新鲜事,内容侧由