本文主要是介绍推荐算法架构 :召回(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
召回模块面对几百上千万的推荐池物料规模,候选集十分庞大。由于后续有排序模块作为保障,故不需要十分准确,但必须保证不要遗漏和低延迟。目前主要通过多路召回来实现,一方面各路可以并行计算,另一方面取长补短。召回通路主要有非个性化和个性化两大类。
1 推荐算法整体架构
1.1 推荐算法意义
随着互联网近十年来的大力发展,用户规模和内容规模均呈现迅猛发展。用户侧日活过亿早已不是什么新鲜事,内容侧由于 UGC 生产方式的普及,拥有几十亿内容库的平台也屡见不鲜。如何让海量用户在海量内容中找到自己喜欢的,以及如何让海量内容被海量用户精准消费,一直以来都是每个公司十分核心的问题。在这个背景下,搜索系统和推荐系统应运而生。搜索系统主要解决用户寻找感兴趣的内容,偏主动型消费。推荐系统则主要解决内容推送给合适用户,偏被动型消费。二者一边牵引用户,一边牵引内容,是实现用户与内容匹配的中间媒介。推荐系统在每个公司都是十分核心的地位,其意义主要有
- 用户侧,为用户及时精准的推送感兴趣的个性化内容,并不断发现和培养用户的潜在兴趣,满足用户消费需求,提升用户体验,从而提升用户活跃度和留存。
- 内容侧,作为流量分发平台,对生产者(如 UGC 作者、电商卖家等)有正向反馈刺激能力,通过扶持有潜力的中小生产者,可以促进整体内容生态的繁荣发展
- 平台侧,推荐系统对内容分发的流量和效率都至关重要。通过提升用户体验,可提升用户留存,从而提升日活。通过提升用户转化和流量效率,可提升电商平台订单量和内容平台用户人均时长等核心指标。通过提升用户消费深度,可提升平台整体流量,为商业化目标(如广告)打下基础,提升 ARPU(每用户平均收入)等核心指标。推荐系统与公司很多核心指标息息相关,有极大的牵引和推动作用,意义十分重要。
1.2 推荐算法基本模块
当前基于算力和存储的考虑,还没办法实现整体端到端的推荐。一般来说推荐系统分为以下几个主要模块:
- 推荐池:一般会基于一些规则,从整体物料库(可能会有几十亿甚至百亿规模)中选择一些 item 进入推荐池,再通过汰换规则定期进行更新。比如电商平台可以基于近 30 天成交量、商品在所属类目价格档位等构建推荐池,短视频平台可以基于发布时间、近 7 天播放量等构建推荐池。推荐池一般定期离线构建好就可以了。
- 召回:从推荐池中选取几千上万的 item,送给后续的排序模块。由于召回面对的候选集十分大,且一般需要在线输出,故召回模块必须轻量快速低延迟。由于后续还有排序模块作为保障,召回不需要十分准确,但不可遗漏(特别是搜索系统中的召回模块)。目前基本上采用多路召回解决范式,分为非个性化召回和个性化召回。个性化召回又有 content-based、behavior-based、feature-based 等多种方式。
- 粗排:获取召回模块结果,从中选择上千 item 送给精排模块。粗排可以理解为精排前的一轮过滤机制,减轻精排模块的压力。粗排介于召回和精排之间,要同时兼顾精准性和低延迟。一般模型也不能过于复杂
- 精排:获取粗排模块的结果,对候选集进行打分和排序。精排需要在最大时延允许的情况下,保证打分的精准性,是整个系统中至关重要的一个模块,也是最复杂,研究最多的一个模块。精排系统构建一般需要涉及样本、特征、模型三部分。
- 重排:获取精排的排序结果,基于运营策略、多样性、context 上下文等,重新进行一个微调。比如三八节对美妆类目商品提权,类目打散、同图打散、同卖家打散等保证用户体验措施。重排中规则比较多,但目前也有不少基于模型来提升重排效果的方案。
- 混排:多个业务线都想在 Feeds 流中获取曝光,则需要对它们的结果进行混排。比如推荐流中插入广告、视频流中插入图文和 banner 等。可以基于规则策略(如广告定坑)和强化学习来实现。

推荐系统包含模块很多,论文也是层出不穷,相对来说还是十分复杂的。我们掌握推荐系统算法最重要的还是要梳理清楚整个算法架构和大图,知道每个模块是怎么做的,有哪些局限性和待解决问题,可以通过什么手段优化等。并通过算法架构大图将各个模块联系起来,融会贯通。从而不至于深陷某个细节,不能自拔。看论文的时候也应该先了解它是为了解决什么问题,之前已经有哪些解决方案,再去了解它怎么解决的,以及相比其他方案有什么改进和优化点。本文主要讲解推荐算法架构大图,帮助读者掌握全局,起到提纲挈领作用。
2 召回
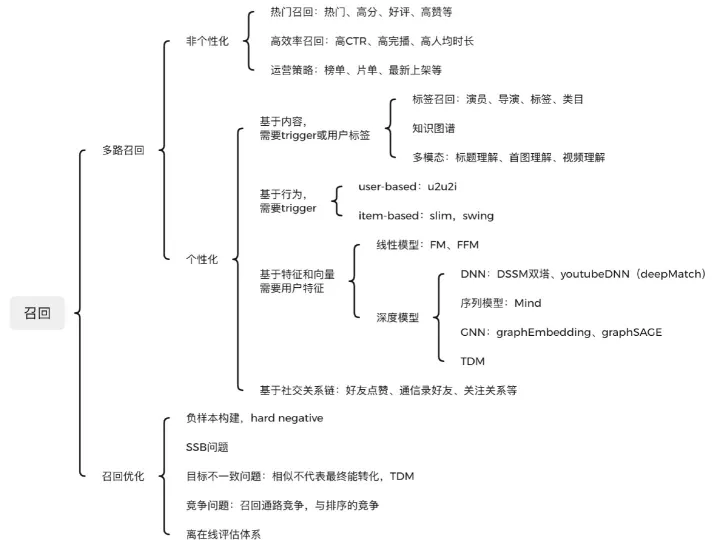
2.1 多路召回
召回模块面对几百上千万的推荐池物料规模,候选集十分庞大。由于后续有排序模块作为保障,故不需要十分准确,但必须保证不要遗漏和低延迟。目前主要通过多路召回来实现,一方面各路可以并行计算,另一方面取长补短。召回通路主要有非个性化和个性化两大类。
2.1.1 非个性化召回
非个性化召回与用户无关,可以离线构建好,主要有
- 热门召回:比如近 7 天播放 vv 比较高的短视频,可以结合 CTR 和时间衰减做平滑,并过滤掉人均时长偏低的疑似骗点击 item。还可以选择用户点赞多、好评多的 item 等。这部分主要基于规则实现即可。由于热门 item 容易导致马太效应,如果热门召回占整体通路比例过大,可以考虑做一定打压。
- 高效率召回:比如高 CTR、高完播率、高人均时长的短视频,这类 item 效率较高,但可能上架不久,历史播放 vv 不多,好评也需要时间积累,有可能不在热门召回内。
- 运营策略召回:例如运营构建的各个类目的榜单、片单,最新上架 item 等。
2.1.2 个性化召回
个性化召回与用户相关,千人千面,根据构建方式主要有
- content-based:基于内容,可以通过用户标签,比如新注册时填写的喜欢的导演、演员、类目等信息,也可以通过用户历史行为作为 trigger,来选取与之内容相似的 item。主要有:
- 标签召回:比如演员、导演、item 标签 tag、类目等。
- 知识图谱
- 多模态:比如标题语义相似的 item,首图相似的 item,视频理解相似的 item 等
一般先离线构建好倒排索引,在线使用时通过用户标签或者历史行为 item 作为 trigger,取出对应候选即可。基于内容来构建倒排索引,不需要 item 有丰富的行为,对冷启 item 比较友好。
- behavior-based:基于行为,主要是 userCF 和 itemCF 两种,都是通过行为来找相似,需要 user 或者 item 有比较丰富的行为。userCF 先找到与 user 行为相似的 user,选取他们行为序列中的 item 作为候选。itemCF 则找到每个 item 被行为相似的其他 item,构建倒排索引。构建方式主要有 CF 和 MF 两大类,MF 又称 model-based CF,就不具体展开了。
- feature-based:基于特征,比如 user 的年龄、性别、机型、地理位置、行为序列等,item 的上架时间、视频时长、历史统计信息等。基于特征的召回构建方式,信息利用比较充分,效果一般也比较好,对冷启也比较友好,是最近几年来的研究重点。又主要分为
- 线性模型:比如 FM、FFM 等,就不具体展开了
- 深度模型:比如基于 DNN 的 DSSM 双塔、youtubeDNN(又叫 deepMatch)。基于用户序列的 Mind。基于 GNN 的 graphSAGE 等。
线上使用时,可以有两种方式:
-
- 向量检索:通过生成的 user embedding,采用近邻搜索,寻找与之相似的 item embedding,从而找到具体 item。检索方式有哈希分桶、HNSW 等多种方法
- i2i 倒排索引:通过 item embedding,找到与本 item 相似的其他 item,离线构建 i2i 索引。线上使用时,通过用户历史行为中的 item 作为 trigger,从倒排索引中找到候选集
- social-network:通过好友点赞、关注关系、通信录关系等,找到社交链上的其他人,然后通过他们来召回 item。原则就是好友喜欢的 item,大概率也会喜欢,物以类聚人以群分嘛。
2.2 召回优化
多路召回的各通路主要就是这些,那召回中主要有哪些问题呢,个人认为主要有
- 负样本构建问题:召回是样本的艺术,排序是特征的艺术,这句话说的很对。召回正样本可以选择曝光点击的样本,但负样本怎么选呢?选择曝光未点击的样本吗,肯定不行
- 曝光未点击样本,能从已有召回、粗排、精排模块中竞争出来,说明其 item 质量和相关性都还是不错的,作为召回负样本肯定不合适
- SSB 问题,召回面向的全体推荐池,但能得到曝光的 item 只是其中很小的子集,这样构建负样本会导致十分严重的 SSB(sample selection bias)问题,使得模型严重偏离实际
基于这个问题,我们可以在推荐池中随机选择 item 作为负样本,但又会有一个问题,随机选择的 item,相对于正样本来说,一般很容易区分,所以需要有 hard negative sample 来刺激和提升召回模型效果。构建 hard negative sample,是目前召回研究中比较多的一个方向,主要有:
-
- 借助精排模型:比如选取精排打分处于中间位置的 item,如排名 100~500 左右的 item,它们不是很靠前,可以看做负样本,也不是吊车尾,与正样本有一定相关性,区分起来有一定难度。
- 业务规则:比如选择同类目、同价格档位等规则的 item,可以参考 Airbnb 论文的做法。
- 主动学习:召回结果进行人工审核,bad case 作为负样本
一般会将 hard negative 与 easy negative,按照一定比例,比如 1: 100,同时作为召回负样本。
- SSB 问题:召回面向的是全体推荐池,item 数量巨大,故需要做一定的负采样,有比较大的 SSB 样本选择偏差问题。故需要让选择出来的负样本,尽可能的能代表全体推荐池,从而提升模型泛化能力。主要问题仍然是负采样,特别是 hard negative sample 的问题。
- 目标不一致问题:目前的召回目标仍然是找相似,不论是基于内容的,还是基于行为和特征的。但精排和最终实际业务指标仍然看的是转化,相似不代表就能得到很好的转化,比如极端情况,全部召回与用户最近播放相似的短视频,显然最终整体的转化是不高的。
- 竞争问题:各召回通路最终会做 merge 去重,各通道之间重复度过高则没有意义,特别是新增召回通路,需要对历史通路有较好的补充增益作用,各召回通路之间存在一定的重叠和竞争问题。同时,召回通路的候选 item,不一定能在精排中竞争透出,特别是历史召回少的 item,由于其曝光样本很少,精排中打分不高,所以不一定能透出。召回和精排的相爱相杀,还需要通过全链路优化来缓解。
这篇关于推荐算法架构 :召回(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








