本文主要是介绍推荐系统学习笔记(四)--基于向量的召回,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
离散特征处理
离散特征:性别,国籍,英文单词,物品id,用户id
处理:
建立字典:eg:china = 1
向量化:eg:one-hot /embedding(低维稠密向量)
one-hot--适合低维度
例如:
性别:男,女
字典:男 = 1,女 = 2
one-hot:
未知[0 , 0]
男 [1 , 0]
女 [0 , 1]
one-hot局限:
例1: nlp中,对单词编码,维度上万
例2:推荐系统中,对物品id编码,上亿笔记
类别数量很大时,不用one-hot
embedding(嵌入)
例子:国籍embeddding
参数数量:向量维度 * 类别数量
embedding : 4 * 200 = 800
embedding层:参数以矩阵形式保存,大小为:向量维度 * 类别数量
输入:序号,eg:美国序号为2
输出:向量,eg:美国对应参数矩阵第二列
神经网络关键在于embedding层,对它的优化是一个关键点
one-hot和embedding关系
embedding = one-hot * 参数矩阵
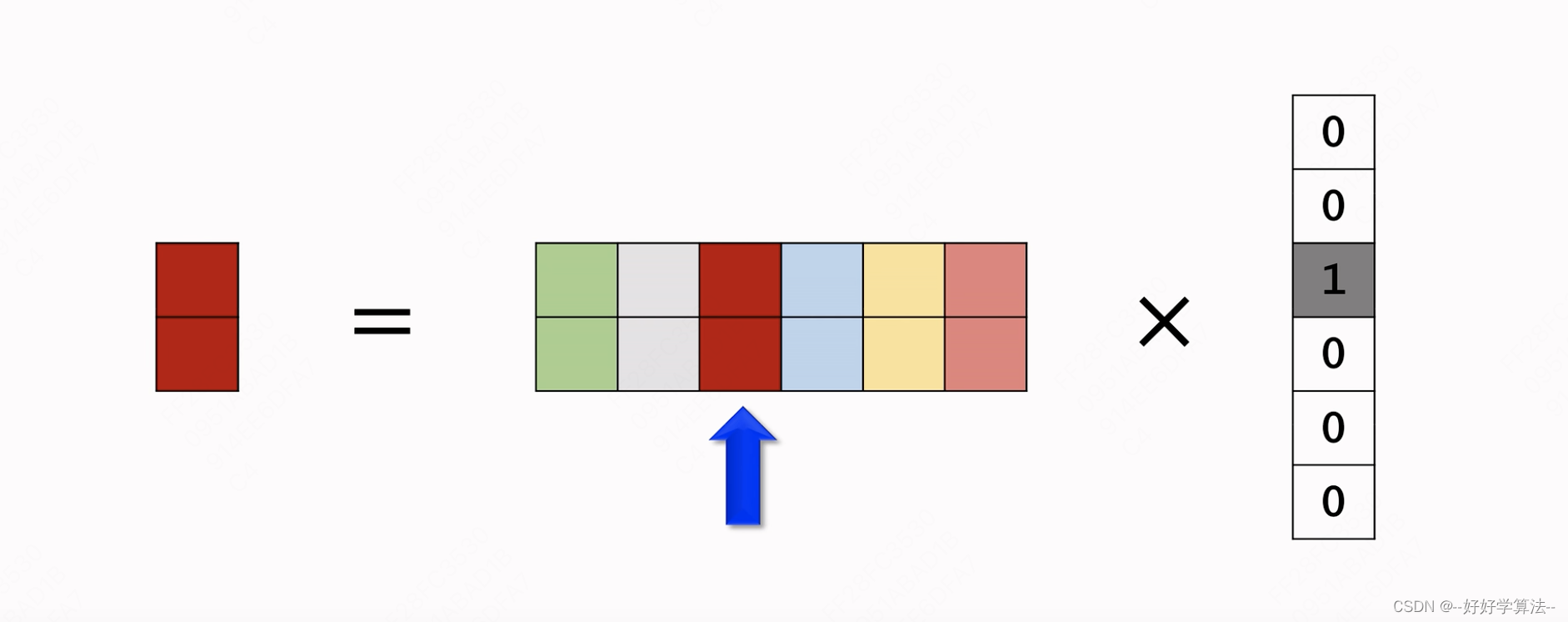
矩阵补充(目前不常用)
训练:
用户embedding层,矩阵A,每个用户对应一列
物品embedding层,矩阵B,每个物品对应一列
内积就是第u个用户对第i个商品兴趣的预估值
训练的目的:学习矩阵A和B
数据集:(用户id a,物品id b,真实兴趣分数 y)------>三元组
优化问题:

行:用户,列:物品,灰色位置表示未曝光,绿色位置代表分数
为什么叫矩阵补充?
大多数都是灰色的,我们并不知道这些用户对这些物品的兴趣,用绿色的部分训练,得到矩阵AB,将灰色部分补全,补全之后就可以给用户做推荐了
工业界不用
缺点:
1.没有利用物品和用户的属性,仅仅使用了id做embedding
2.负样本选取方式不对:
正样本:曝光后点击
负样本:曝光后未点击(这是一个“想当然”的设计,其实不对,工业界不采用,后面会详细讲如何构造负样本)
3.训练的方法不好,内积不如余弦相似度,平方损失(回归)不如交叉熵损失(分类)判断正负样本
线上服务
模型存储
训练得到的矩阵AB可能会很大,A--用户,B---物品
矩阵A:
存到key-value表,key是用户id,value是A的一列。
矩阵B:
比较复杂
线上服务
1.利用用户id,查找kv表,得到向量a
2.最近邻查找:查找最有可能的k个物品
物品的embedding向量bi,计算内积<a,bi>,返回最大的k个物品
缺点:时间复杂度正比于物品数量,暴力枚举导致无法实时运转。
如何加速
近似最近邻查找
定义标准:余弦相似度最大(常用) or 内积最大 or 欧氏距离小。
如果系统不支持计算余弦相似度:
将向量归一化(二范数等于1),此时计算出的内积就等于余弦相似度。
方法:
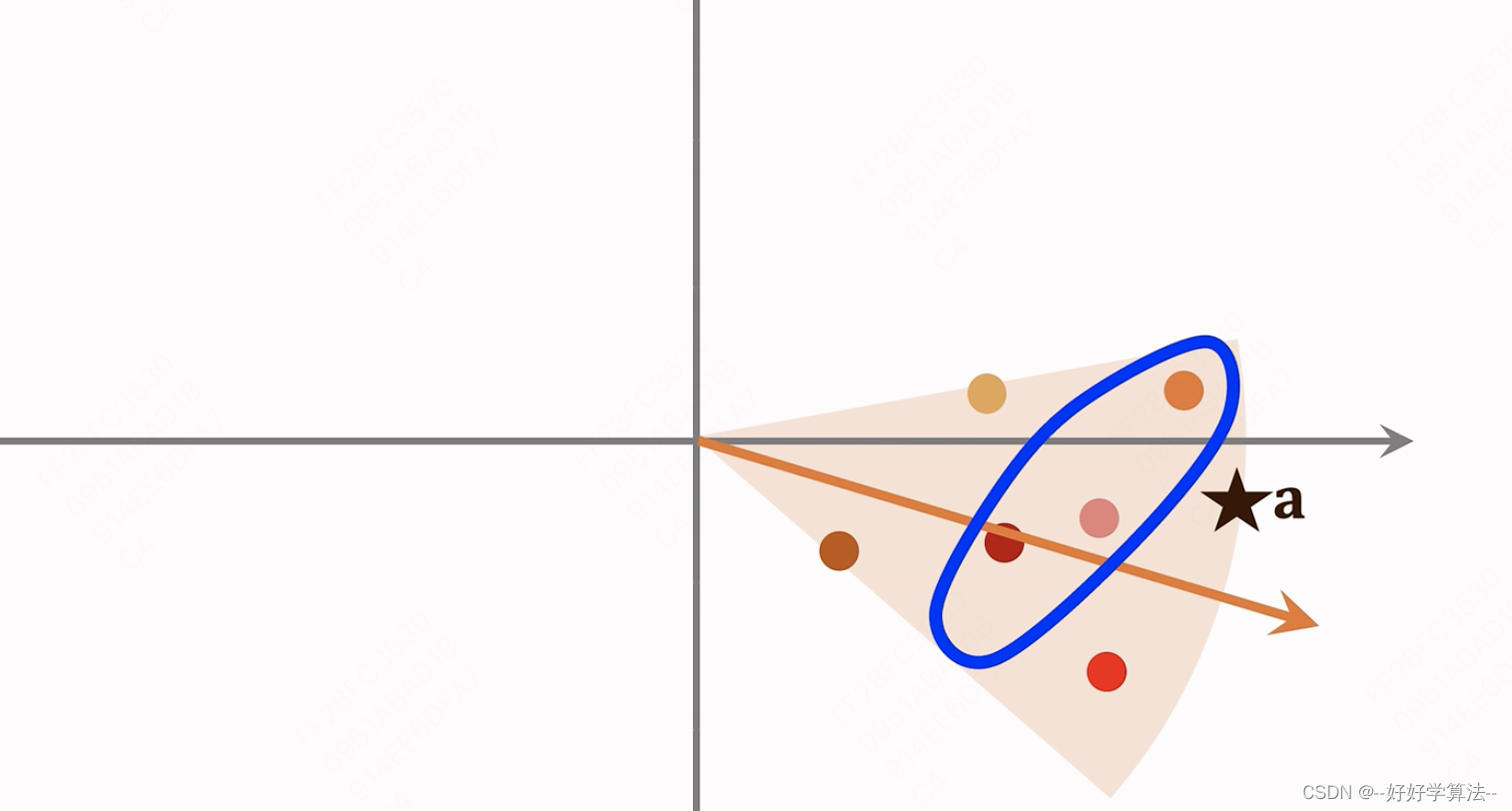
1.数据预处理:分成多个区域,每个区域用一个长度为1的单位向量表示,建立索引,向量作为key,点列表作为value,给定一个向量,就可以返回区域内所有点。
如何划分:余弦相似度---扇形,欧氏距离---多边形
2.线上快速找回:用户向量a,与所有单位索引向量对比,计算相似度,找到最相似的,通过索引,找到所有点,再计算所有点的相似度
这篇关于推荐系统学习笔记(四)--基于向量的召回的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







