本文主要是介绍浅谈互联网搜索之召回,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景
在搜索系统中,一般会把整个搜索系统划分为召回和排序两大子系统。本文会从宏观上介绍召回系统,并着重介绍语义召回。谨以此文,希望对从事和将要从事搜索行业的工作者带来一些启发与思考。
二、搜索系统召回方法
不同于推荐系统,检索系统是在输入query的前提下,快速召回与query相关的文本,特点为要求是快,注重召回轻准确。注意,在工业界考虑到用户体验,往往要求百毫秒以内完成召回,甚至在地图、电商类的sug 场景(边输入边推荐提示)召回要求十毫秒内完成。由此可见,召回在工业界的技术和工程要求比较高。
在召回系统中往往采用多路召回构建召回体系,当前召回体系可以抽象为三大方向:
(1)倒排索引召回:
倒排索引可以理解为 k,v 对,对doc(文档)分词,每个词可以看做 k,包含该词的文档可以看做 v,这样就构建了以词为key的拉链,如下图所示。当用户输入query时,根据用户输入query切词粒度term进行倒排拉链召回(如query 清华大学,切分为清华和大学两个term,会召回清华和大学相关文本),这是非常经典和基础的传统召回方法。当用户输入规范且输入信息量较足的情况下,能够准确召回用户所需要文档。然而,在现实场景中,当用户存在输入错误以及输入同义的情况下,就会存在召回率不足的问题,影响检索体验。

(2)个性化召回:
基于倒排索引召回是严格基于文本词粒度term结构完成query和doc的匹配,而个性化的召回则是基于用户行为的召回方法,最简单的方法是统计用户历史query对文档的点击,根据点击doc构建个性化召回集合。个性化召回相对于文本召回的优势在于不需要精准的term命中即可召回相关文档,缺点在于如果相关性把握不好,会引入一些影响用户体验的badcase。
(3)语义召回:
语义召回是搜索引擎发展的新趋势,能够更加精准地满足用户需求,因此受到了广泛关注。语义召回是利用神经网络计算用户输入query和目标doc之间的语义匹配度,并召回 top-k最相关的文档。具体做法为,离线经过模型对 doc 向量化,并通过最近邻建库算法(fassi、hnsw等)构建向量索引库,在线通过模型对query进行向量化,召回向量库中相似度最高的N个文档,这种方法虽然能够一定程度上解决query泛化的问题,但是会因为召回的准确率等问题引入杂质,召回后需要通过语义质量控制杂质问题。下面重点介绍一下语义召回。
三、语义召回
不同用户甚至不同终端输入千差万别,query 往往包含汉字、拼音、阿拉伯数字,甚至五笔笔画偏旁输入。这些复杂的输入组成千差万别的query组合,对刻画用户搜索需求造成巨大挑战,当前基于倒排索引的规则召回难以满足这种复杂query的输入。而语义召回是搜索引擎发展的新趋势,泛化能力甚至精准召回能力近年来都变得越来越强,因此受到了广泛关注。下面介绍几种搜索领域常见的召回方法,简单归纳一下主要有传统语义召回(DSSM双塔为代表)、带有场景信息的多源语义召回(图语义召回、多模语义召回等),大模型预训练语义召回。具体如下:
(1)传统语义召回
DSSM是一种典型的朴素双塔召回,出自微软,是当前推广搜算法最通用的向量召回算法之一。
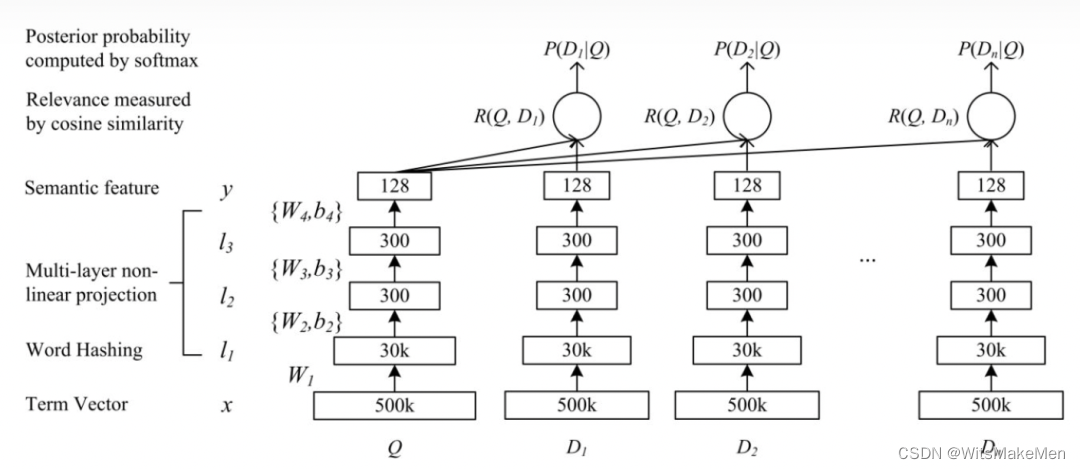
作为最典型的语义召回算法,将用户侧和文档侧特征组成的稀疏向量通过多层深度网络压缩到同一个低维向量空间,并通过余弦相似度来计算两个语义向量的距离,最终训练出代表用户和文档在高维空间语义相似度模型。在线预测时利用训练好的用户向量最近邻检索文档向量返回top-k近似文档。该方法的特点为用户侧和文档侧向量分离,工程落地容易,同时能够利用深度学习的丰富表达能力,达到比较好的效果。
(2)多源语义召回
这里所谓的多源语义召回,是指融合多个场景信息,比如引入图像的多模语义召回,引入只是图谱的图语义召回等。这些场景信息相当于为模型提供辅助信息,在一些query输入比较短语义不明确的场景中(比如搜索领域的sug)辅助信息尤为重要,因为能够提供更丰富的输入表达。比如,在电商领域,对图片进行映射表达为向量;在地图领域,对用户的地理位置进行表达作用用户的输入;在美食领域,对用户的搜索历史构建只是图谱,作为用户的输入,能够达到千人千面的召回效果。
(3)大模型预训练语义召回
为了提升在检索领域召回的效果,最近提出了使用预训练阶段细粒度交互向粗粒度交互蒸馏的策略,训练出面向检索场景的基础大模型。同时,进一步以大模型为热启,基于海量点击数据post-train的双塔匹配、召回模型,在多项QT双塔语义匹配、召回任务中取得效果提升。具有以下优点:充分利用海量数据,尤其利用人工精标的相关性数据进行fine-tune,在偏文本的召回,排序等任务上取得了比较不错的效果。
四、总结与展望
本文介绍了搜索中的三大召回方法:倒排索引召回、个性化召回和语义召回,以及重点介绍了搜索领域召回新趋势语义召回。倒排索引作为搜索领域的召回基石长久不衰,该方法简单高效,能够解决大多数召回场景case,但长尾Query的搜索会导致输入意图一致的相似词无法解决。随着语义召回的发展,不仅能够解决长尾case,甚至具有代替倒排索引的能力,在一些大厂中,正不断迭代语义召回,逐步下掉倒排索引,我相信在不就得将来,强大的语义召回会成成为搜索领域的主流。还是那句话,随着新技术和新想法的不断涌现,搜索引擎还有很多可以完善的地方,需要你我共同建设。
这篇关于浅谈互联网搜索之召回的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






