本文主要是介绍召回与排序算法总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
尊敬的读者您好:笔者很高兴自己的文章能被阅读,但原创与编辑均不易,所以转载请必须注明本文出处并附上本文地址超链接以及博主博客地址:https://blog.csdn.net/vensmallzeng。若觉得本文对您有益处还请帮忙点个赞鼓励一下,笔者在此感谢每一位读者,如需联系笔者,请记下邮箱:zengzenghe@gmail.com,谢谢合作!
近期在做给交叉用户进行酒店资源推荐时,学习并尝试了不少的召回与排序算法,下面将对这些算法进行总结梳理,以备后续复习巩固。
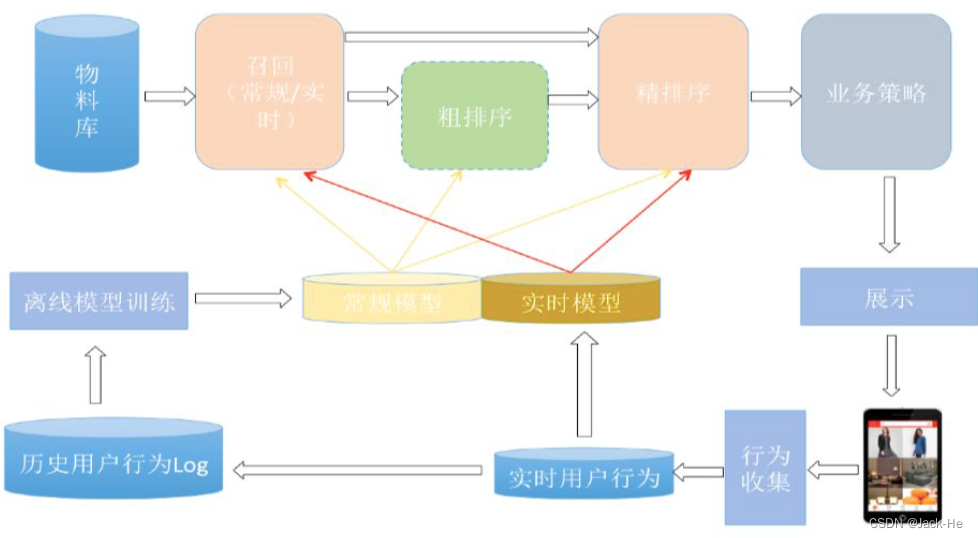
1、推荐系统架构选取
在酒店资源推荐中,我们采用的推荐系统结构与业界大多数的推荐系统相似,具体结构如下:
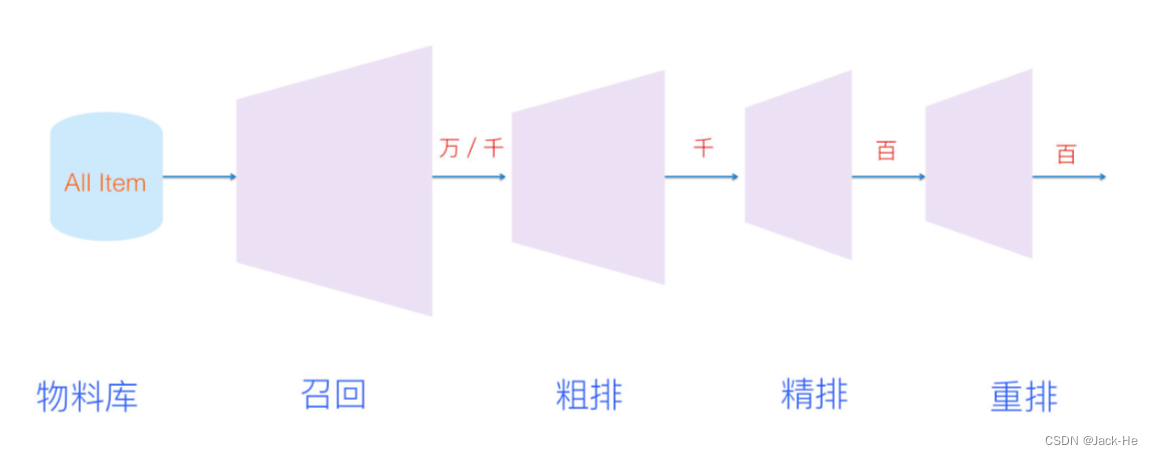
2、推荐系统流程
推荐系统流程一般会有四个环节,其中分别为:召回->粗排->精排(Ranking)->重排(ReRank)。
(1) 召回环节(召回是源头决定着整个推荐的天花板)
首先是因为面临的侯选数据集非常大,而最根本的要求是速度快,因为要求速度快,所以就不能部署太复杂的模型。另外要使用少量的特征,这是召回阶段的特性。召回阶段要掌握一点:怎么快怎么来,但是也要兼顾用户兴趣。简单来说,召回会把大量的物料减到几百上千的量级,然后扔给后面的粗排/ranking阶段。
(2) 粗排环节(粗排是初筛一般不会上复杂模型)
有时候因为每个用户召回环节返回的物品数量还是太多,怕排序环节速度跟不上,所以可以在召回和精排之间加入一个粗排环节,通过少量用户和物品特征,简单模型,来对召回的结果进行个粗略的排序,在保证一定精准的前提下,进一步减少往后传送的物品数量,粗排往往是可选的,可用可不同,跟场景有关。
(3) 精排环节(精排是推荐的重中之重,使用特征和模型都会比较复杂)
它和召回阶段的特性完全不一样,ranking阶段只有一点需要记住:模型要够准,这是它的根本。此外,因为这一阶段处理的数据量比较少了,所以可以上你能承受速度极限的复杂模型,使用能想到的任意有用的特征,尽量精准地对物品进行个性化排序,但归根结底是为了一件事:怎么准怎么来。
(4) 重排环节(重排是做打散或满足业务运营的特定强插需求,一般不使用复杂模型)
一般会结合各种技术及业务策略,比如去已读、去重、打散、多样性保证、固定类型物品插入等等,主要是技术产品策略主导或者为了改进用户体验的。
3、召回常用模型
召回环节主要解决的是从海量候选酒店中召回千级别的酒店问题。具体包括以下几种。
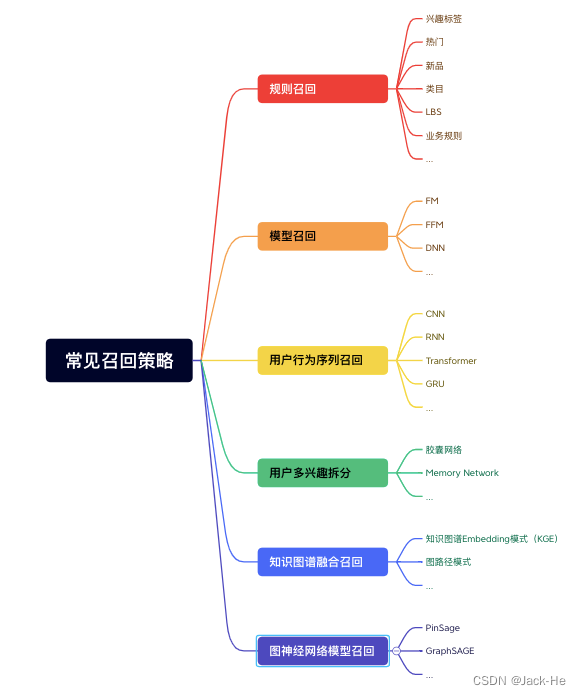
(1) 规则召回
主要是通过一些人工规则去多路召回家酒店,比如用户出行类型、热门酒店等,但当召回路数较多时,会导致多路召回每路截断条数的超参个性化问题。
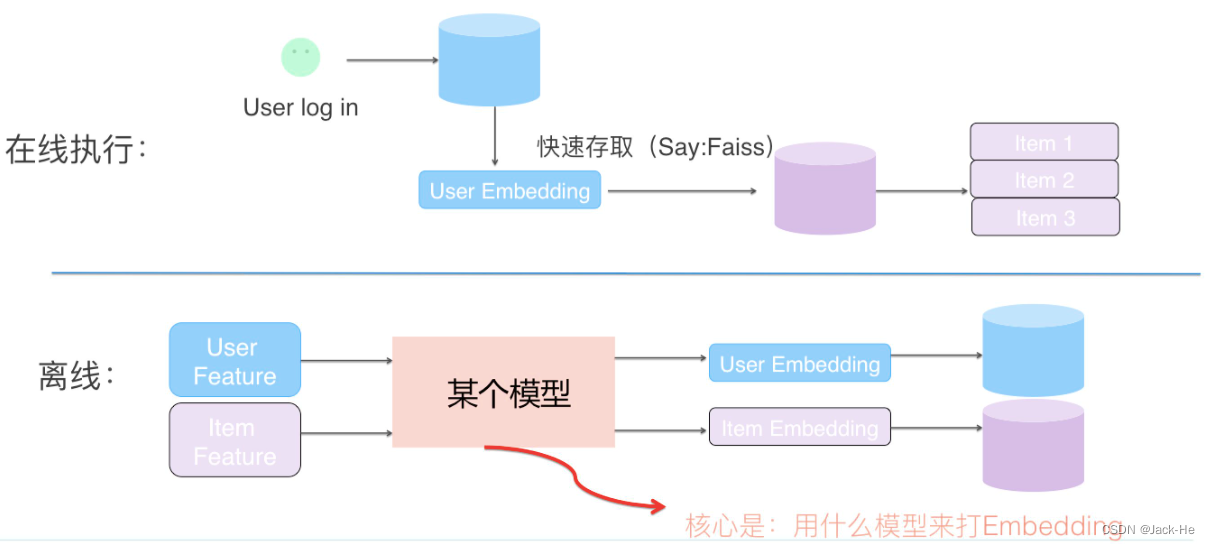
(2) 模型召回
将用户特征和物品特征分离,各自通过某个具体的模型,分别打出用户Embedding以及物品Embedding。在线上,可以根据用户兴趣Embedding,采用类似Faiss等高效Embedding检索工具,快速找出和用户兴趣匹配的物品,这样就等于做出了利用多特征融合的召回模型了。
(3) 用户行为序列召回
利用用户行为过的物品序列对用户兴趣建模,即输入是用户行为过的物品序列,可以只用物品ID表征,也可以融入物品的Side Information比如名称,描述,图片等,以这些物品信息作为输入,通过一定的方法把这些进行糅合到一个embedding里,而这个糅合好的embedding,就代表了用户兴趣。无论是在召回过程,还是排序过程,都可以融入用户行为序列。在召回阶段,我们可以用用户兴趣Embedding采取向量召回,而在排序阶段,这个embedding则可以作为用户侧的特征。
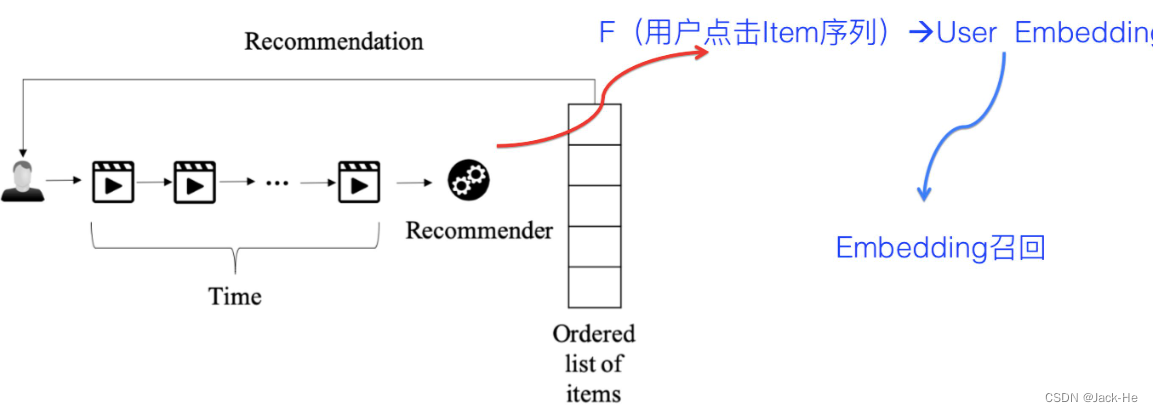
(4) 用户多兴趣拆分
通过用户兴趣embedding拉回来的物料,可能集中在头部优势领域中,造成弱势兴趣不太能体现出来的问题。而如果把用户兴趣进行拆分,每个兴趣embedding各自拉回部分相关的物料,则可以很大程度缓解召回的头部问题。因此以用户行为序列物品作为输入,通过一些能体现时序特点的模型,输出由一个用户embedding换成多个用户兴趣embedding。把用户行为序列打到多个embedding上,实际它是个类似聚类的过程,就是把不同的Item,聚类到不同的兴趣类别里去。理论上,很多类似聚类的方法应该都是有效的,所以完全可以在这块替换成你自己的能产生聚类效果的方法来做。
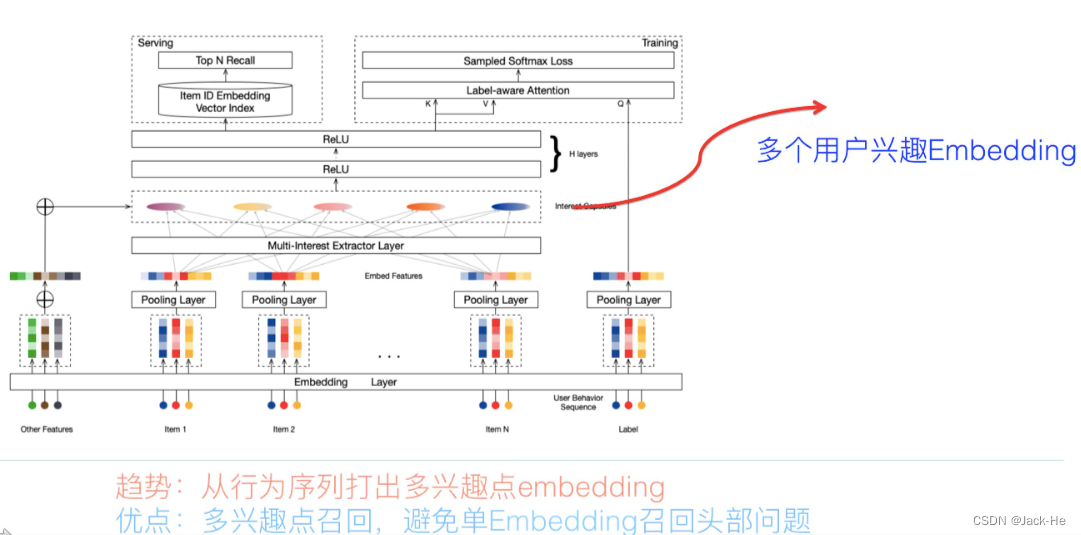
(5) 知识图谱召回
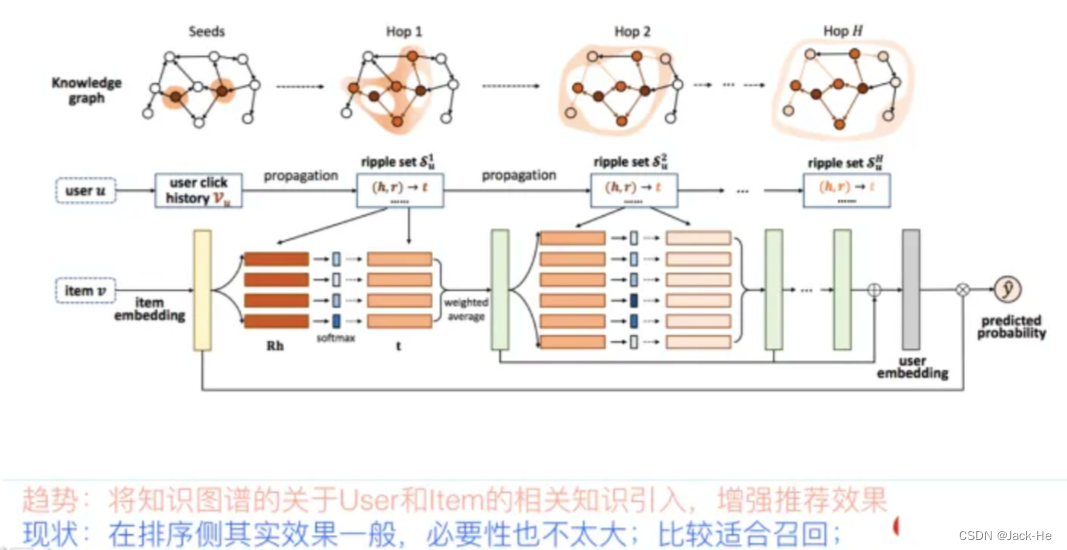
推荐系统里对用户感兴趣的实体比如某个或者某些明星,往往是个单独的召回路,而可以根据用户的兴趣实体,通过知识图谱的实体Embedding化表达后(或者直接在知识图谱节点上外扩),通过知识外扩或者可以根据Embedding相似性,拓展出相关实体。形成另外一路相关性弱,但是泛化能力强的Knowledge融合召回路。
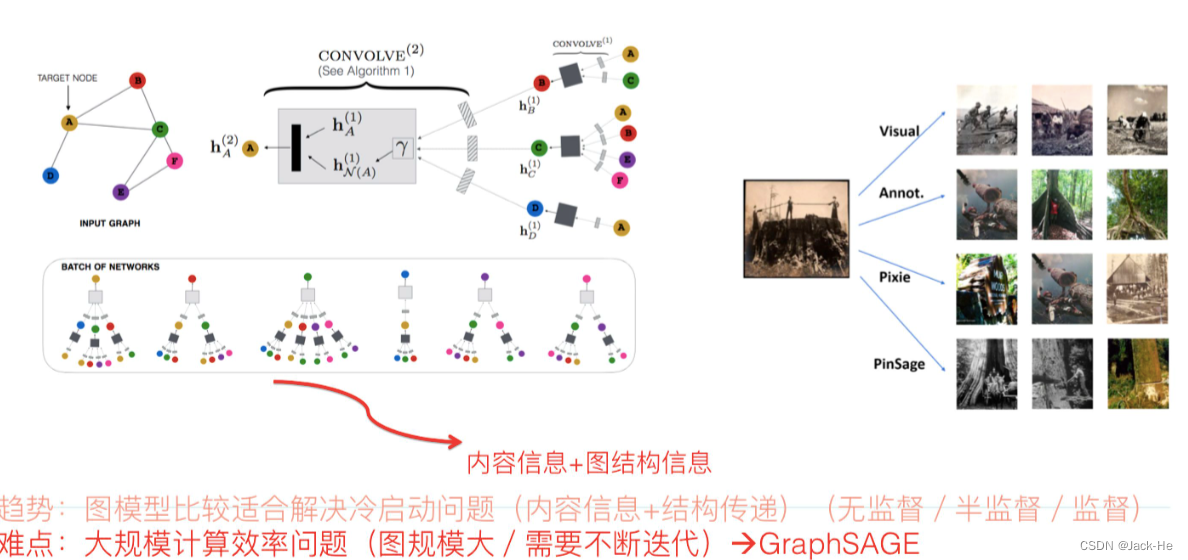
(6) 图神经网络模型召回
图神经网络,最终获得的往往是图中节点的embedding,这个embedding,就像我们上面说的,其实融合了各种异质信息。所以它是特别适合用来做召回的,比如拿到图网络中用户的embedding和物品embedding,可以直接用来做向量召回。
4、排序常用模型
用机器学习方法解决排序问题的方法称为Learning to Ranking(LTR),LTR流程三大模pointwise、pairwise、listwise。关于排序模型的发展路线具体如下:
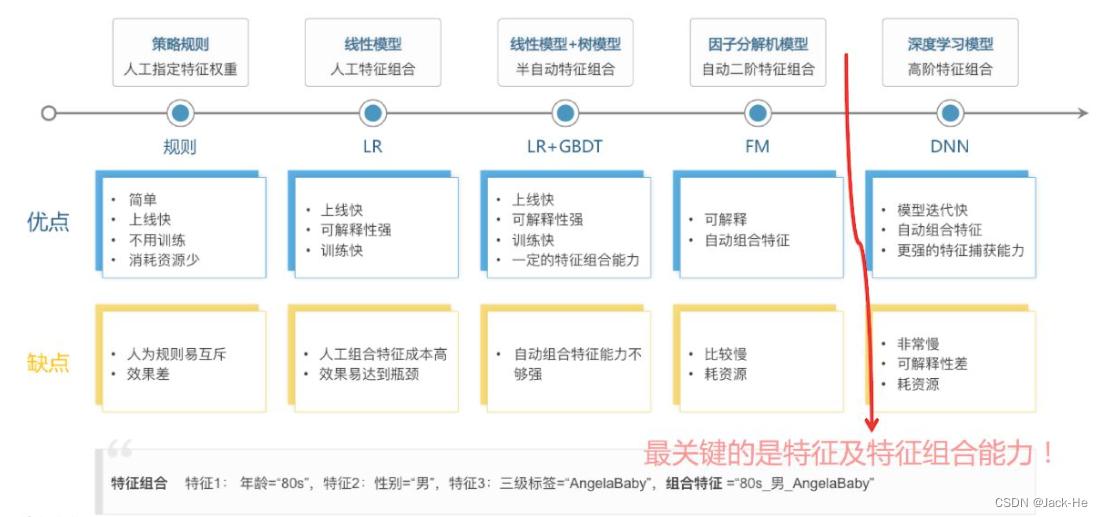
(1) 粗排层:与精排类似,但在特征和模型复杂度上会精简,此外也有将精排模型通过蒸馏得到简化版模型来做粗排。
(2) 精排层:精排解决的是从千级别item到几十这个级别的问题。
a. CTR预估:LR,GBDT,FM及其变种(FM是一个工程团队不太强又对算法精度有一定要求时比较好的选择),Wide&Deep,DeepFm,NCF各种交叉,DIN,BERT,RNN
b. 多目标:MOE,MMOE,MTL(多任务学习)
c. 打分公式融合: 随机搜索,CEM(性价比比较高的方法),在线贝叶斯优化(高斯过程),带模型CEM,强化学习等
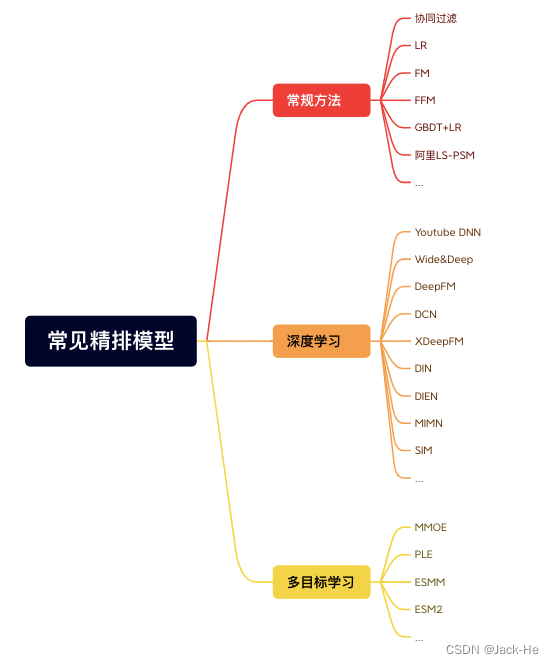
(3) 重排层:重排层解决的是展示列表总体最优,可能涉及业务调整、打散、强插、增量分等等,模型有 MMR,DPP,RNN系列(参考阿里的globalrerank系列)
最后建议:对排序模型,如果你打算推上线真用起来的话,建议是,沿着这个序列尝试:LR—>FM-->DeepFM。
日积月累,与君共进,增增小结,未完待续。
这篇关于召回与排序算法总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






