本文主要是介绍推荐系统之召回,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
由于毕业后应该会从事召回的工作,而自己之前研究的并不是这个方向,所以对推荐系统中的召回进行简单的学习。
召回就是从海量的类目库中挑选出相似的类目,后续由排序算法对这些类目排序,接着将其推荐给用户,也就是说召回其实就是推荐系统的第一步,起到一个粗筛的作用。由于这部分处理的数据量较大,速度要求较快,所以需要使用相对简单的算法模型。
常见的召回方法有三种:
-
基于内容的召回
- 根据item之间的相似性原则
- 召回用户喜欢的item的相似item
-
协同过滤召回
- 根据用户或物品之间的相似性原则
- 用户A与用户B相似,其中用户A喜欢item1,但是用户B并没有说明是否喜欢该item,就可以将item1推荐给用户B
- 物品同理
-
模型召回
- 矩阵分解召回
- FM模型召回
- 图网络召回
- 其他深度学习模型召回
1、基于内容的召回
基于内容的召回就是根据用户的浏览内容,召回相关的内容,随之推荐给用户,其实也就是基于标签的召回。
该方法有如下优点:
- 适用于用户的初始阶段。此时用户的历史数据较少,可以通过内容召回来保证召回的数量
- 缓解内容的冷启动问题。主要指给与新内容曝光度
- 有利于捕获用户的兴趣
缺点:
- 内容的特征需要人工设计,所以设计人对领域的了解程度会极大的影响结果
- 缺少多样性,也就是仅能了解用户的兴趣,无法扩展用户的兴趣
2、基于协同过滤的召回
协同过滤分为基于用户的协同与基于物品的协同。
基于用户的协同就是根据相似用户的兴趣进行召回,也就是对大家的反馈、评价和意见进行协同。其实现过程有以下三步:
- 根据用户历史行为创建共现矩阵
- 根据共现矩阵查找相似用户
- 将相似用户喜欢的物品推荐给目标用户(即召回)
基于物品的协同原理相同。
NeuralCF使用深度学习对协同过滤进行了改进
论文:Neural Collaborative Filtering
链接:https://arxiv.org/pdf/1708.05031v2.pdf
源码:https://github.com/hexiangnan/neural_collaborative_filtering
其模型结构如下:

在矩阵分解中,模型仅对用户表征和物品表征求内积,在NeuralCF中模型对两者进行了改进,加上了多个线性层,进行了更加复杂的特征提取
其代码实现如下:
# neural cf model arch two. only embedding in each tower, then MLP as the interaction layers
def neural_cf_model_1(feature_inputs, item_feature_columns, user_feature_columns, hidden_units):# 物品侧特征层item_tower = tf.keras.layers.DenseFeatures(item_feature_columns)(feature_inputs)# 用户侧特征层user_tower = tf.keras.layers.DenseFeatures(user_feature_columns)(feature_inputs)# 连接层及后续多层神经网络interact_layer = tf.keras.layers.concatenate([item_tower, user_tower])for num_nodes in hidden_units:interact_layer = tf.keras.layers.Dense(num_nodes, activation='relu')(interact_layer)# sigmoid单神经元输出层output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(interact_layer)# 定义keras模型neural_cf_model = tf.keras.Model(feature_inputs, output_layer)return neural_cf_model
3、基于模型的召回
3.1 矩阵分解
矩阵分解就是将(users,items)的共现矩阵( m × n m\times{n} m×n)分解为用户的隐向量矩阵( m × k m\times{k} m×k)和物品的隐向量矩阵( k × n k\times{n} k×n)。每个用户的隐向量由用户矩阵的行向量表示,每个物品的隐向量由物品矩阵的列向量表示,根据用户和物品的隐向量计算两者之间的相似度,进行召回。
可以通过模型训练的方式实现矩阵分解,其损失函数为:
m i n ( q ∗ , p ∗ ) ∑ ( u , i ) ∈ K ( r u i − q i T p u ) 2 min_{(q^*,p^*)}\sum_{(u,i)\in{K}}(r_{ui}-q^T_ip_u)^2 min(q∗,p∗)∑(u,i)∈K(rui−qiTpu)2
也就是说模型需要最小化用户矩阵和物品矩阵乘积与共现矩阵的差异,式中 r u i r_{ui} rui表示共现矩阵, q q q表示用户矩阵, p p p表示物品矩阵。得到两者的embedding表示后,后续使用常规的embedding方式召回即可。
下面是使用spark MLlib调用ASL算法实现的矩阵分解模型代码:
// 建立矩阵分解模型
val als = new ALS().setMaxIter(5).setRegParam(0.01).setUserCol("userIdInt").setItemCol("movieIdInt").setRatingCol("ratingFloat")//训练模型
val model = als.fit(training)//得到物品向量和用户向量
model.itemFactors.show(10, truncate = false)
model.userFactors.show(10, truncate = false3.2 FM模型
论文:Factorization Machines
链接:chrome-extension://bocbaocobfecmglnmeaeppambideimao/pdf/viewer.html?file=https%3A%2F%2Fciteseerx.ist.psu.edu%2Fviewdoc%2Fdownload%3Fdoi%3D10.1.1.393.8529%26rep%3Drep1%26type%3Dpdf
FM(因式分解机)在2010年由Rendle提出,核心在于通过特征组合,减少人工参与,其优点如下:
- 实现特征之间的交互
- 能处理数据高度稀疏的场景。通过对参数矩阵进行矩阵分解实现降维
- 具有线性计算复杂度
- 能够在任意的实数特征向量中生效
FM的计算公式为:
y = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n ( v i , v j ) x i x j y=w_0+\sum^n_{i=1}w_ix_i+\sum^{n}_{i=1}\sum^n_{j=i+1}(v_i,v_j)x_ix_j y=w0+∑i=1nwixi+∑i=1n∑j=i+1n(vi,vj)xixj
( v i , v j ) = ∑ f = 1 k v i , f ˙ v j , f (v_i,v_j)=\sum^k_{f=1}v_{i,f}\dot{}v_{j,f} (vi,vj)=∑f=1kvi,f˙vj,f
其中 y = w 0 + ∑ i = 1 n w i x i y=w_0+\sum^n_{i=1}w_ix_i y=w0+∑i=1nwixi为线性模型,FM在其基础上增加了后面的特征交互
其中 ∑ i = 1 n ∑ j = i + 1 n ( v i , v j ) x i x j \sum^{n}_{i=1}\sum^n_{j=i+1}(v_i,v_j)x_ix_j ∑i=1n∑j=i+1n(vi,vj)xixj的推导如下:
∑ i = 1 n ∑ j = i + 1 n ( v i , v j ) x i x j \sum^{n}_{i=1}\sum^n_{j=i+1}(v_i,v_j)x_ix_j ∑i=1n∑j=i+1n(vi,vj)xixj
= 1 2 ∑ i = 1 n ∑ j = 1 n ( v i , v j ) x i x j − 1 2 ∑ i = 1 n ( v i , v i ) x i x i \frac{1}{2}\sum^{n}_{i=1}\sum^n_{j=1}(v_i,v_j)x_ix_j-\frac{1}{2}\sum^n_{i=1}(v_i,v_i)x_ix_i 21∑i=1n∑j=1n(vi,vj)xixj−21∑i=1n(vi,vi)xixi
= 1 2 ( ∑ i = 1 n ∑ j = 1 n ∑ f = 1 k v i , f , v j , f x i x j − ∑ i = 1 n ∑ f = 1 k v i , f v i , f x i x i ) \frac{1}{2}(\sum^n_{i=1}\sum^n_{j=1}\sum^k_{f=1}v_{i,f},v_{j,f}x_ix_j-\sum^n_{i=1}\sum^k_{f=1}v_{i,f}v_{i,f}x_ix_i) 21(∑i=1n∑j=1n∑f=1kvi,f,vj,fxixj−∑i=1n∑f=1kvi,fvi,fxixi)
= 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f x i ) ( ∑ j = 1 n v j , f x j ) − ∑ i = 1 n v i , f 2 x i 2 ) \frac{1}{2}\sum^k_{f=1}((\sum^n_{i=1}v_{i,f}x_i)(\sum^n_{j=1}v_{j,f}x_j)-\sum^n_{i=1}v^2_{i,f}x^2_i) 21∑f=1k((∑i=1nvi,fxi)(∑j=1nvj,fxj)−∑i=1nvi,f2xi2)
= 1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f x i ) 2 − ∑ i = 1 n v i , f 2 x i 2 ) \frac{1}{2}\sum^k_{f=1}((\sum^n_{i=1}v_{i,f}x_i)^2-\sum^n_{i=1}v^2_{i,f}x^2_i) 21∑f=1k((∑i=1nvi,fxi)2−∑i=1nvi,f2xi2)
可以看到这个公式的复杂度为O(kn),属于线性级别
其模型结构如下:

3.3 图结构
3.3.1 DeepWalk
2014年,美国石溪大学研究者提出随机游走。本质上就是在图结构上进行随机游走,生成item序列,这些序列将作为训练数据输入skip-gram模型,然后得到对应的embedding表示,如下图所示:

生成的图结构是一种有向图,其流程如下:
- 以用户的行为序列,如购买物品序列、观看视频序列等,来构建物品关系图,如果后续产生多条相同的有向边则其权重被加强
- 随机确定起始点,使用随机游走的方式生成物品序列。其中,随机游走的长度、次数都属于超参数
- 将随机游走生成的序列输入模型生成embedding表示
需要主要随机游走的跳转概率,也就是在下一步遍历邻居节点的概率,其定义如下:
p ( v j ∣ v i ) = { M i j ∑ j ∈ N + ( V i ) , m i j v j ∈ N + ( v i ) 0 e i j ∉ ϵ p(v_j|v_i)=\begin{cases}\frac{M_{ij}}{\sum_{j\in{N+(V_i)}}},m_{ij}& \text{$v_j\in{N_+(v_i)}$}\\0& \text{$e_{ij}\notin\epsilon$}\end{cases} p(vj∣vi)={∑j∈N+(Vi)Mij,mij0vj∈N+(vi)eij∈/ϵ
式中 N + ( v i ) N_+(v_i) N+(vi)表示节点 v i v_i vi所有出边的集合, M i j M_{ij} Mij表示节点之间的权重,换言之,随机游走的跳转概率是跳转边权重占所有出边权重和的比例。
3.3.2 Node2vec
2016年,斯坦福大学研究员提出Node2vec。通过调整随机游走跳转概率的计算方式,让图embedding在网络的同质性和结构性中权衡。其中同质性指距离详尽的节点的embedding应该尽量近似,结构性指结构上相似的节点的embedding尽量接近。
为了实现结构性,随机游走时应该倾向于BFS,更多的游走周围节点。为了实现同质性,随机游走更倾向于DFS,因为DFS更可能实现多次的跳转,游走到更远的节点。

在Node2vec中,通过节点间的跳转概率来控制跳转的倾向性。如下图,其中 v v v为当前节点, t t t为上一个节点, x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3为将要跳到的候选节点
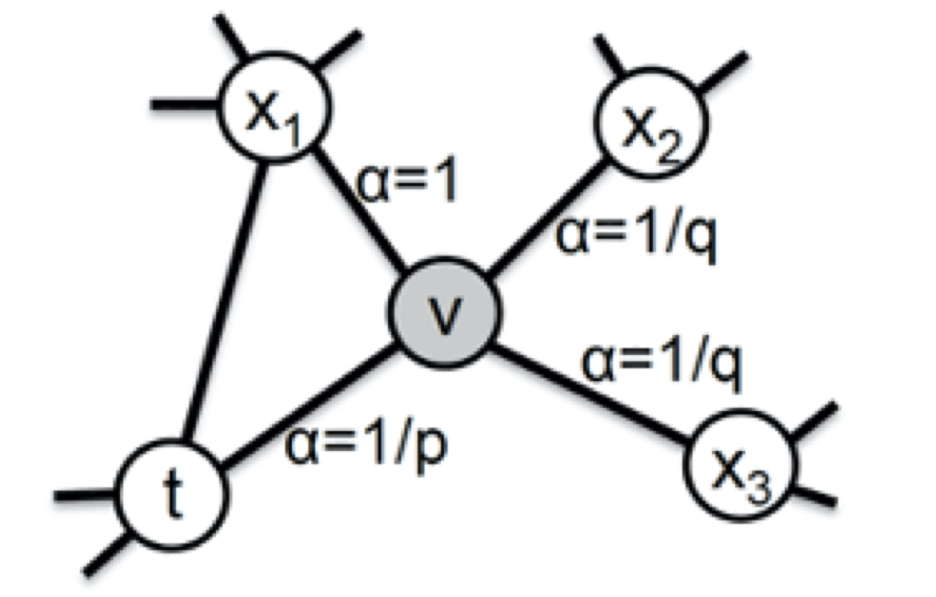
从当前节点 v v v跳到下一个节点 x x x的概率为:
p v x = α p q ( t , x ) ˙ w v x p_{vx}=\alpha_{pq}(t,x)\dot{}w_{vx} pvx=αpq(t,x)˙wvx
式中 w v x w_{vx} wvx是边 v x vx vx的原始权重, α p q ( t , x ) \alpha_{pq}(t,x) αpq(t,x)为定义的跳转权重,其计算方式为:
α p q ( t , x ) = { 1 p d t x = 0 1 d t x = 1 1 q d t x = 2 \alpha_{pq}(t,x)=\begin{cases}\frac{1}{p}& \text{$d_{tx}=0$}\\1& \text{$d_{tx}=1$}\\\frac{1}{q}& \text{$d_{tx}=2$}\end{cases} αpq(t,x)=⎩ ⎨ ⎧p11q1dtx=0dtx=1dtx=2
式中 d t x d_{tx} dtx表示节点 t t t到 x x x的距离,当两者直接相连时,距离就是1,节点到自身的距离就是0,其他不与 t t t相连的距离就是2。式中 p p p被称为返回参数,值越小随机游走回节点 t t t的可能性越大,网络更注重结构性。 q q q表示进出参数,值越大表示游走到远方的可能性越大,网络更注重同质性
3.3.3 EGES(阿里巴巴)
论文:Billion-scale Commodity Embedding for E-commerce
Recommendation in Alibaba
链接:https://arxiv.org/abs/1803.02349
2018年,阿里巴巴提出EGES。随机游走无法解决冷启动问题,EGES在随机游走中引入了item的补充信息,比如当item为衣服、电器时,补充信息可以为对应的商店、风格、颜色等。EGES通过加权平均的方式,融合物品的多个embedding。其结构如下:

其加权方式为:
H v = ∑ j = 0 n e a v j W v j ∑ j = 0 n e a v j H_v=\frac{\sum^n_{j=0}e^{a^j_v}W^j_v}{\sum^n_{j=0}e^{a^j_v}} Hv=∑j=0neavj∑j=0neavjWvj
3.3.4 图神经网络
后续就是图神经网络的应用,这一点已经在上一篇文章浅谈图神经网络
介绍了。构建图之后,使用对应的图神经求解embedding即可。
3.4 其他深度学习模型
目前召回使用的模型还是以深度学习模型为主,其中比较经典的模型有mlp、wide&deep、deepFm,以及DIN(阿里提出,引入了注意力机制)和DIEN(阿里提出,加上了三层的序列模型结构)
3.4.1 MLP
基于embedding+mlp的分类实现步骤如下:
- 离散数据转化为one-hot,并进一步转化为embedding的形式,接着封装
- 数值型数据直接封装
- 将数值型与离散型stack
- 定义模型并训练
其中,模型的定义如下:
#将数值型特征和离散特征进行stack
preprocessing_layer = tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns)model = tf.keras.Sequential([preprocessing_layer,tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dense(1, activation='sigmoid'),
])"""
完整代码见:
https://github.com/gzglss/study-notes/blob/main/%E6%8E%A8%E8%8D%90/code/%E5%8F%AC%E5%9B%9E-embedding%2Bmlp.py
"""
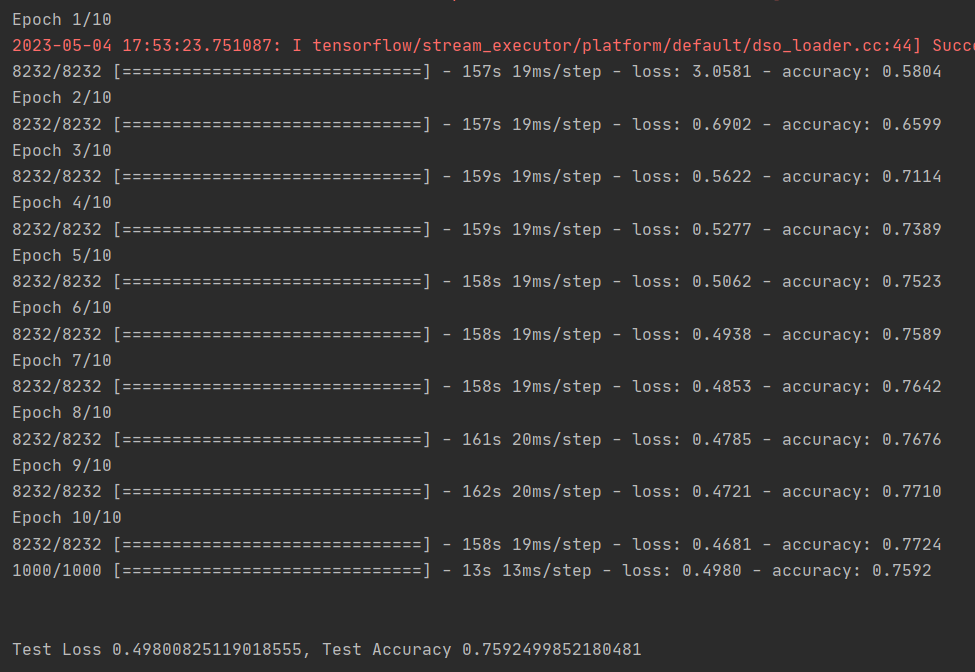
结果如下:
3.4.2 wide&deep
论文:Wide & Deep Learning for Recommender Systems
链接:https://arxiv.org/abs/1606.07792
2016年,谷歌发布。其模型结构如下图所示:
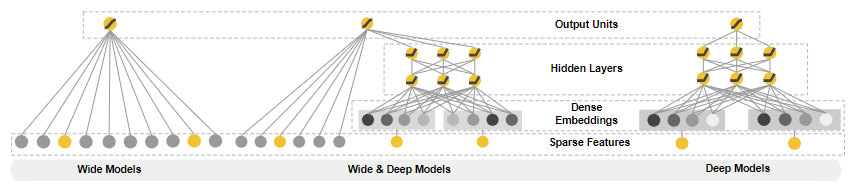
模型由左侧的wide部分和右侧的deep部分组成。wide部分就是直接将输入层连接输出层,中间无其他处理;deep部分就是添加了多个隐藏层。其特点如下:
- wide部分让模型具有较强的记忆能力
- deep部分让模型具有较强的泛化能力
- 结合两者让模型既能快速处理和记忆大量历史行为特征,又具有强大的表达能力
该模型用于google play,其应用如下图所示:

左边为deep部分,右边为wide部分。在wide部分使用的特征是用户已安装应用和曝光应用,这就是希望记住“如果用户安装了A,是否会安装B”这样的规则。
代码实现如下:
inputs = {'movieAvgRating': tf.keras.layers.Input(name='movieAvgRating', shape=(), dtype='float32'),'movieRatingStddev': tf.keras.layers.Input(name='movieRatingStddev', shape=(), dtype='float32'),'movieRatingCount': tf.keras.layers.Input(name='movieRatingCount', shape=(), dtype='int32'),'userAvgRating': tf.keras.layers.Input(name='userAvgRating', shape=(), dtype='float32'),'userRatingStddev': tf.keras.layers.Input(name='userRatingStddev', shape=(), dtype='float32'),'userRatingCount': tf.keras.layers.Input(name='userRatingCount', shape=(), dtype='int32'),'releaseYear': tf.keras.layers.Input(name='releaseYear', shape=(), dtype='int32'),'movieId': tf.keras.layers.Input(name='movieId', shape=(), dtype='int32'),'userId': tf.keras.layers.Input(name='userId', shape=(), dtype='int32'),'userRatedMovie1': tf.keras.layers.Input(name='userRatedMovie1', shape=(), dtype='int32'),'userGenre1': tf.keras.layers.Input(name='userGenre1', shape=(), dtype='string'),'userGenre2': tf.keras.layers.Input(name='userGenre2', shape=(), dtype='string'),'userGenre3': tf.keras.layers.Input(name='userGenre3', shape=(), dtype='string'),'userGenre4': tf.keras.layers.Input(name='userGenre4', shape=(), dtype='string'),'userGenre5': tf.keras.layers.Input(name='userGenre5', shape=(), dtype='string'),'movieGenre1': tf.keras.layers.Input(name='movieGenre1', shape=(), dtype='string'),'movieGenre2': tf.keras.layers.Input(name='movieGenre2', shape=(), dtype='string'),'movieGenre3': tf.keras.layers.Input(name='movieGenre3', shape=(), dtype='string'),
}#wide部分交叉特征的生成movie_feature = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
rated_movie_feature = tf.feature_column.categorical_column_with_identity(key='userRatedMovie1', num_buckets=1001)
crossed_feature = tf.feature_column.crossed_column([movie_feature, rated_movie_feature], 10000)# wide and deep model architecture
# deep part for all input features
deep = tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns)(inputs)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
# wide part for cross feature
wide = tf.keras.layers.DenseFeatures(crossed_feature)(inputs)
both = tf.keras.layers.concatenate([deep, wide])
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(both)
model = tf.keras.Model(inputs, output_layer)
3.4.3 deepFM
论文:DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
链接:https://arxiv.org/abs/1703.04247
2017年,由哈尔滨工业大学和华为联合发布。其模型结构如下:
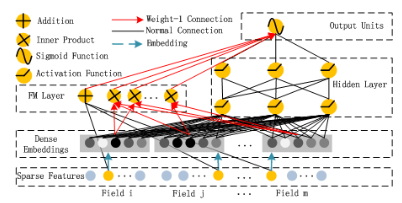
模型利用了wide&deep的思想,用FM替换了之前的wide,用以加强浅层网络的特征组合能力。更具体地,使用点积让不同特征之间两两组合,再把组合后的结果输入到输出神经元,大大加强模型的特征交叉能力。
实现代码如下:
inputs = {'movieAvgRating': tf.keras.layers.Input(name='movieAvgRating', shape=(), dtype='float32'),'movieRatingStddev': tf.keras.layers.Input(name='movieRatingStddev', shape=(), dtype='float32'),'movieRatingCount': tf.keras.layers.Input(name='movieRatingCount', shape=(), dtype='int32'),'userAvgRating': tf.keras.layers.Input(name='userAvgRating', shape=(), dtype='float32'),'userRatingStddev': tf.keras.layers.Input(name='userRatingStddev', shape=(), dtype='float32'),'userRatingCount': tf.keras.layers.Input(name='userRatingCount', shape=(), dtype='int32'),'releaseYear': tf.keras.layers.Input(name='releaseYear', shape=(), dtype='int32'),'movieId': tf.keras.layers.Input(name='movieId', shape=(), dtype='int32'),'userId': tf.keras.layers.Input(name='userId', shape=(), dtype='int32'),'userRatedMovie1': tf.keras.layers.Input(name='userRatedMovie1', shape=(), dtype='int32'),'userGenre1': tf.keras.layers.Input(name='userGenre1', shape=(), dtype='string'),'userGenre2': tf.keras.layers.Input(name='userGenre2', shape=(), dtype='string'),'userGenre3': tf.keras.layers.Input(name='userGenre3', shape=(), dtype='string'),'userGenre4': tf.keras.layers.Input(name='userGenre4', shape=(), dtype='string'),'userGenre5': tf.keras.layers.Input(name='userGenre5', shape=(), dtype='string'),'movieGenre1': tf.keras.layers.Input(name='movieGenre1', shape=(), dtype='string'),'movieGenre2': tf.keras.layers.Input(name='movieGenre2', shape=(), dtype='string'),'movieGenre3': tf.keras.layers.Input(name='movieGenre3', shape=(), dtype='string'),
}item_emb_layer = tf.keras.layers.DenseFeatures([movie_emb_col])(inputs)
user_emb_layer = tf.keras.layers.DenseFeatures([user_emb_col])(inputs)
item_genre_emb_layer = tf.keras.layers.DenseFeatures([item_genre_emb_col])(inputs)
user_genre_emb_layer = tf.keras.layers.DenseFeatures([user_genre_emb_col])(inputs)# FM part, cross different categorical feature embeddings
product_layer_item_user = tf.keras.layers.Dot(axes=1)([item_emb_layer, user_emb_layer])
product_layer_item_genre_user_genre = tf.keras.layers.Dot(axes=1)([item_genre_emb_layer, user_genre_emb_layer])
product_layer_item_genre_user = tf.keras.layers.Dot(axes=1)([item_genre_emb_layer, user_emb_layer])
product_layer_user_genre_item = tf.keras.layers.Dot(axes=1)([item_emb_layer, user_genre_emb_layer])# deep part, MLP to generalize all input features
deep = tf.keras.layers.DenseFeatures(deep_feature_columns)(inputs)
deep = tf.keras.layers.Dense(64, activation='relu')(deep)
deep = tf.keras.layers.Dense(64, activation='relu')(deep)# concatenate fm part and deep part
concat_layer = tf.keras.layers.concatenate([product_layer_item_user, product_layer_item_genre_user_genre,product_layer_item_genre_user, product_layer_user_genre_item, deep], axis=1)
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(concat_layer)model = tf.keras.Model(inputs, output_lay)3.4.4 DIN
论文:Deep Interest Network for Click-Through Rate Prediction
链接:https://arxiv.org/abs/1706.06978
源码:https://github.com/zhougr1993/DeepInterestNetwork
2018年,阿里巴巴提出。其模型结构如下:
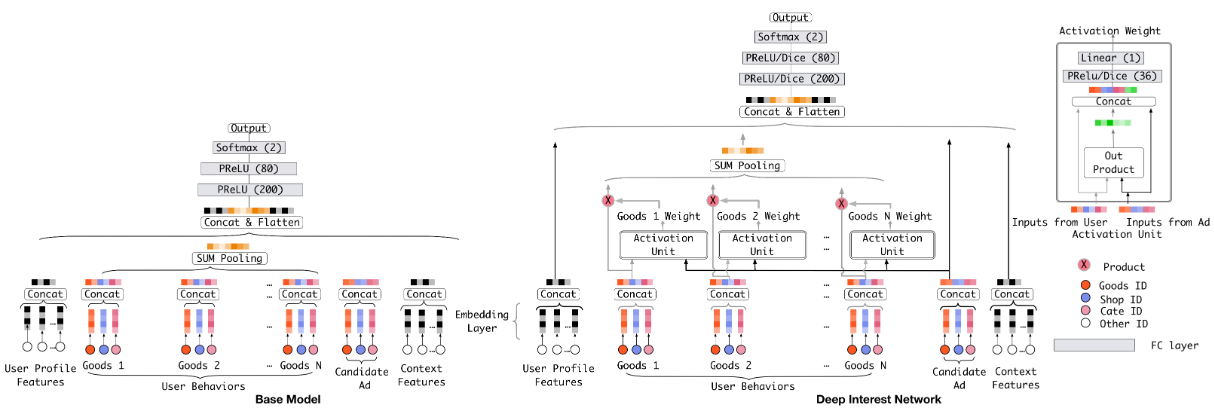
DIN的本质是一个点击率预估模型,其base model如上图左边所示。base model为一个典型的MLP结构。DIN就是在base模型的基础上,将注意力机制用于了用户的历史行为序列。(关于注意力机制,可以看之前的文章attention原理及实现和多头自注意力详解)
从图中可以看到DIN为每个用户的历史购买加了一个激活单元,该单元会生成一个权重,这个权重就是用户对这个商品的注意力得分。激活单元的结构如上图右上角所示,其输入为当前历史行为商品的embedding和候选广告商品的embedding,将这两个向量和它们的外积进行cancat,合并为一个向量,再输入给MLP层。
3.4.5 DIEN
论文:Deep Interest Evolution Network for Click-Through Rate Prediction
链接:https://arxiv.org/abs/1809.03672
源码:https://github.com/mouna99/dien
阿里巴巴对DIN的改进,考虑到了用户存在兴趣改变的特点。其模型结构如下图所示:
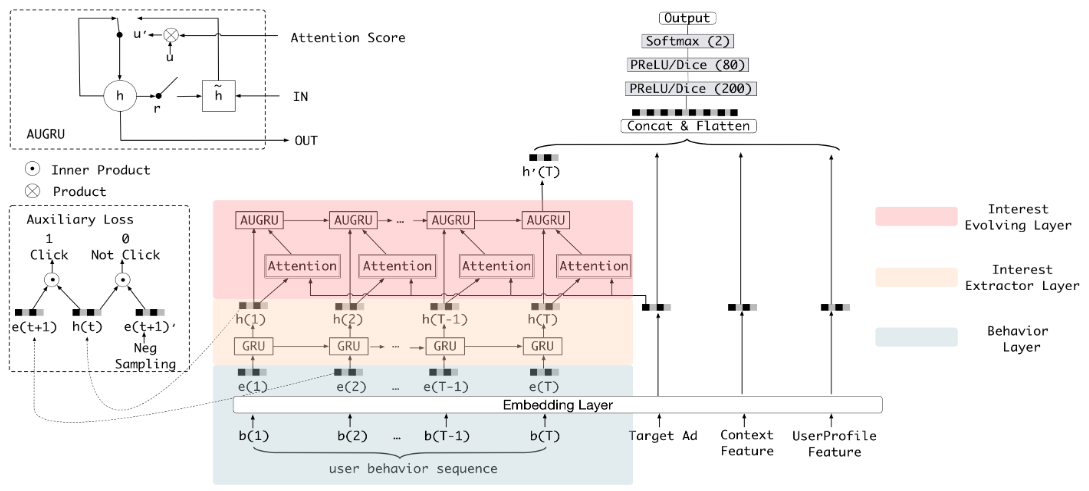
如上图所示,DIEN使用图中的彩色部分替换了DIN中的激活单元。该部分分为三层:
- 第一层为行为序列层。将ID类行为序列转化为embedding表示
- 第二层为兴趣抽取层。使用GRU模型进行特征提取
- 第三层为兴趣进化层。使用AUGRU(GRU with Attention Update Gate),在兴趣抽取层的基础上加入注意力机制
本文从三个大方向(基于内容的召回、基于协同过滤的召回和基于深度学习的召回)对推荐系统中的召回方法进行了介绍。对于协同过滤,介绍了其结合深度学习改进的产物NeuralCF;对于深度学习方法,介绍了矩阵分解模型、FM模型、基于图结构的模型以及比较出名的用于推荐系统的深度学习模型。
本文依旧存在很多不足,对于深度学习方法并没有进行详细介绍,对Faiss没做介绍,对统一召回与多路召回没做介绍,希望后续进一步学习后再做补充。
【参考文章】
深入浅出推荐系统(二):召回:内容为王
推荐召回–基于内容的召回:Content Based
深入理解推荐系统:召回
推荐系统召回中台技术实践
深度学习推荐系统实战
(读论文)推荐系统之ctr预估-FM算法解析
【总结】推荐系统——召回篇【3】
这篇关于推荐系统之召回的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






