统计学专题

统计学(贾俊平)学习笔记--第三章、 数据预处理
数据预处理无论是从数据分类分析、数据信息抽取、数据挖掘、模型建立等方面都是需要的,也是数据工作者最开始招手做的,而统计学(贾俊平)中从理论的角度讲解了数据预处理的概念和方法吗,在此将主要要点列举如下,供有心人参考学些。 数据的预处理是在对数据分类或分组之前所做的必要处理,内容包括数据的审核、筛选、排序等。 审核就是检查数据中是否有错误。从完整性和准



IA的统计学基础:深入解析与实践应用
IA的统计学基础:深入解析与实践应用 在数据泛滥的信息化时代,统计学作为解读数据语言的关键工具,对于任何希望从数据中提取价值的专业人士来说都是必修课。本文将从统计学的基本概念入手,深入探讨其技术细节,并展示如何将这些技术应用于实际问题解决中。 统计学的定义与重要性 统计学是数据分析的科学,它提供了一套量化数据特征、建模数据关系和做出推断决策的方法。统计学的应用遍及科学研究、工业生产、经济管理
数据分析------统计学知识点(五)
回归算法 想象一下,你和朋友在讨论:大学生活中,每天学习的时间是否真的能影响期末成绩?这个问题看似简单,实则包含了一个潜在的关系:学习时间与成绩之间的联系。我们想要知道,增加学习时间是否会提高成绩,以及这种提高有多显著。回归分析正是用来揭示变量之间关系的工具。简单来说,它可以帮助我们理解一个变量(称为因变量,如期末成绩)如何随着其他一个或多个变量(称为自变量,如学习时间)的变化而变化。 回归算
线性回归模型:统计学中的预测利器
线性回归模型:统计学中的预测利器 线性回归模型是统计学中一种重要的预测模型,广泛应用于各个领域,如经济学、社会科学、生物学和工程学等。它基于最小二乘法原理,通过拟合线性关系来解释变量之间的关系,并预测因变量的值。本文将详细介绍线性回归模型的基本概念、建立方法、评估指标以及实际应用案例,帮助读者更好地理解和运用这一强大的统计工具。 一、线性回归模型的基本概念 线性回归模型描述了一个或多个自变量
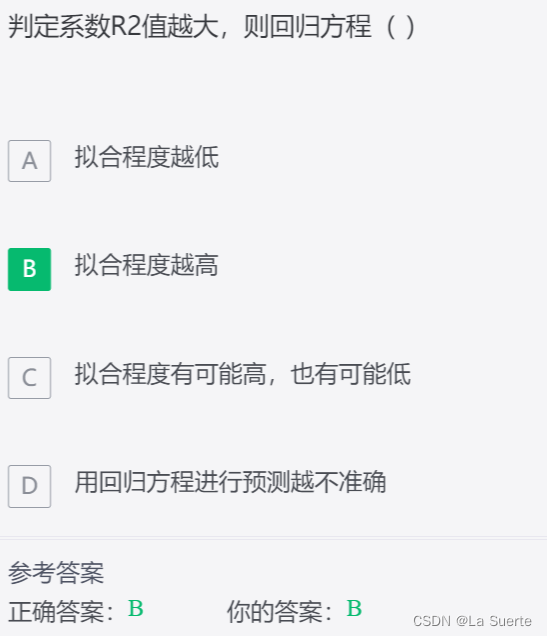
(十三)统计学基础练习题七(选择题T301-350)
本文整理了统计学基础知识相关的练习题,共50道,适用于想巩固统计学基础或备考的同学。来源:如荷学数据科学题库(技术专项-统计学二)。序号之前的题请看往期文章。 301) 302) 303) 304) 305) 306) 307) 308) 309) 310) 311) 312) 313) 314) 315)
从零开始统计学 01 | 假设检验
文章目录 一、提出假设二、选择检验方法2.1 正态分布2.2 t分布(*t-distribution*)与T检验2.3 F分布(*F-distribution*)与方差分析2.4 卡方分布 (*chi-square distribution*)与卡方检验2.4.1 检验数据是否服从某种分布2.4.1.1 使用绘图2.4.1.2 使用卡方检验2.4.1.3 使用Kolmogorov-Smirn

带你系统学习平滑样条、局部回归、广义可加性模型-豆瓣9.6分统计学神作ISL之第七章读书笔记(下)
目录 1.原文内容概要2.算法知识总结2.1 平滑样条(Smoothing Splines)2.1.1 平滑样条简介(An Overview of Smoothing Splines )2.1.2 选择调优参数λ(Choosing the Smoothing Parameter λ) 2.2 局部回归(Local Regression)2.3 广义可加性模型(Generalized Addi

豆瓣9.6分统计学神作ISL之第七章读书笔记(上),带你系统学习多项式回归、阶梯函数、基函数和回归样条
目录 1.原文内容概要2.算法知识总结2.1 多项式回归(Polynomial Regression)2.2 阶梯函数(Step Functions)2.3 基函数(Basis Functions)2.4 回归样条(Regression Splines)2.4.1 分段多项式回归(Piecewise Polynomials)2.4.2 约束条件与样条函数(Constraints and Sp

(十)统计学基础练习题四(50道选择题)
本文整理了统计学基础知识相关的练习题,共50道,适用于想巩固统计学基础或备考的同学。来源:如荷学数据科学题库(技术专项-统计学一)。序号之前的题请看往期文章。 151) 152) 153) 154) 155) 156) 157) 158) 159) 160) 161)

统计学方法的比较与评估
分析不同统计学方法的优缺点以及它们在特定情境下的适用性是一个复杂而有趣的课题。下面我将简要讨论一些常见的统计学方法,并比较它们的特点: 1. **参数统计与非参数统计:** - 参数统计:假设总体分布的形态,并基于样本数据对总体参数进行估计和假设检验。优点是通常效率高,但缺点是对总体分布的假设可能不成立。 - 非参数统计:不对总体分布形态做出假设,通常基于样本数据的秩或排名进行推断。

【R语言与统计】SEM结构方程、生物群落、多元统计分析、回归及混合效应模型、贝叶斯、极值统计学、meta分析、copula、分位数回归、文献计量学
统计模型的七大类:一:多元回归 在研究变量之间的相互影响关系模型时候,用到这类方法,具体地说:其可以定量地描述某一现象和某些因素之间的函数关系,将各变量的已知值带入回归方程可以求出因变量的估计值,从而可以进行预测等相关研究。 二、聚类分析 聚类分析指将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。 三、分类 分类是一种典型的有监督的机器学习方法,其目的是从一
数据分析师 spss,医学数据分析 ,统计学和概率论,T检验
T检验(Student's t-test)是一种统计检验方法,用于检验两个样本的平均值是否存在显著差异,或者一个样本的平均值与一个已知的总体平均值是否存在显著差异。T检验基于t分布,适用于小样本量(样本量小于30)且总体分布为正态或近似正态的情况。 T检验可以分为以下几类: 单样本T检验(One-sample t-test):用于检验一个样本的平均值是否与已知的某个总体平均值存在显著差异。
异常检测——基于统计学的方法(学习blog))
异常检测——基于统计学方法 感谢DataWhale 概述 统计学方法对数据的正常性做出假定。**它们假定正常的数据对象由一个统计模型产生,而不遵守该模型的数据是异常点。**统计学方法的有效性高度依赖于对给定数据所做的统计模型假定是否成立。 异常检测的统计学方法的一般思想是:学习一个拟合给定数据集的生成模型,然后识别该模型低概率区域中的对象,把它们作为异常点。 即利用统计学方法建立一个模型

服务运营 | 精选:用药难?用药贵?运筹学与统计学视角下的药物研发与管理
作者设计了一个多阶段博弈论模型来针对罕见病的不同补贴方案,分析政府、联盟、制药商和患者之间的相互作用。 制药商补贴为 α C \alpha C αC,其中 C C C是研发成本, α ∈ [ 0 , 1 ) \alpha \in [0,1) α∈[0,1)是政府总成本的比例。患者补贴为 β p i \beta p_i βpi,其中 p i p_i pi是药品每单位售价, β \beta β是
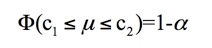
做好A/B测试,需要了解的6个统计学概念
做好A/B测试,需要了解的6个统计学概念 A/B测试是一项用来验证产品新功能效果的科学在线测试方法,它能够通过对实际实验数据进行统计分析从而帮助用户做出对产品的不同功能版本进行取舍的决策。为了使A/B测试得到的结论更严谨更科学,我们在AB测试中借助了强大的统计学做理论支持。 我们整理了以下几个基本概念,帮助大家更好地理解A/B测试中的统计学知识: 均值 平均数是反映数据集中趋势的一项指标,
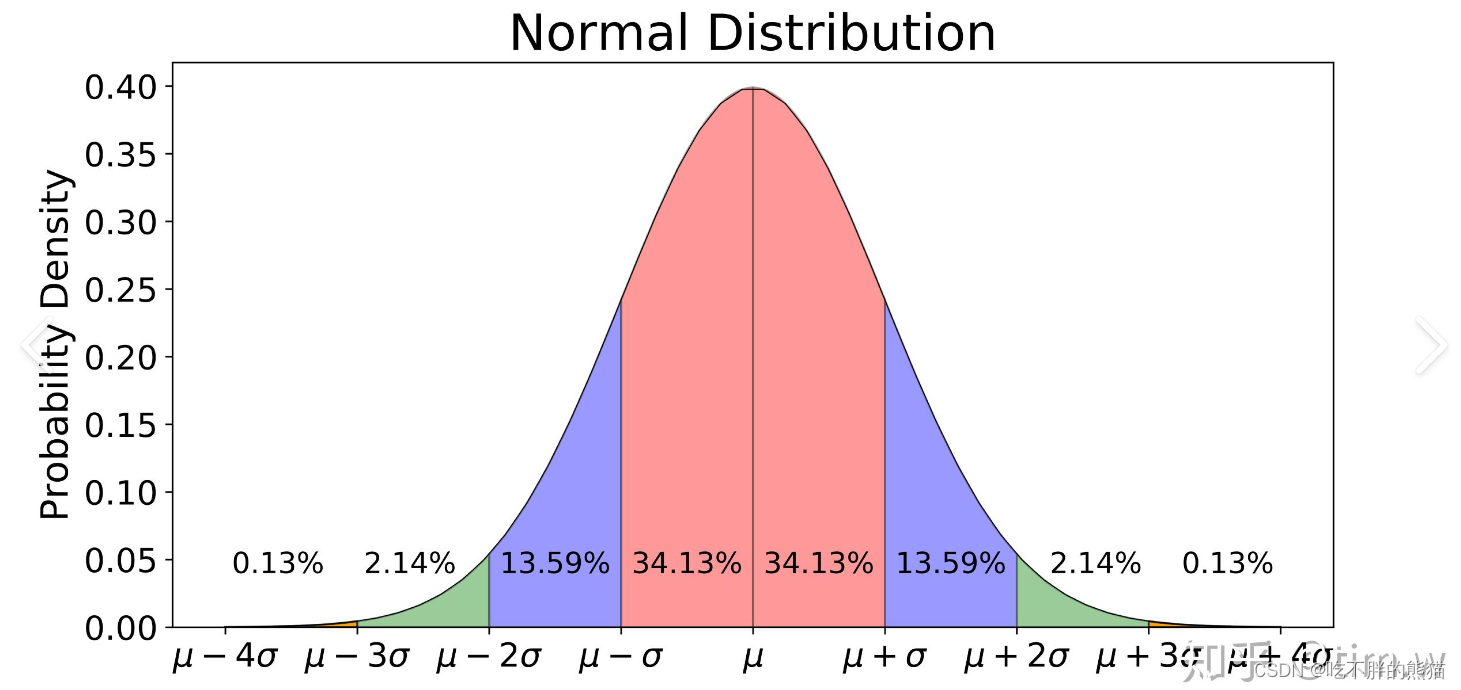
【AI相关】数学和统计学知识
数学和统计学的知识可以分为两部分: 一部分是线性代数中的基础概念,比如标量、向量和张量。 另一部分是概率统计中常见的分布类型,比如正态分布和伯努利分布。 线性代数 什么是标量? 标量是一个单独的数,可以是整数、实数或复数。 它就像是一个单独的点,没有方向,只有大小。 什么是向量? 向量是一组有序的标量,它们按照一定的顺序排列。 你可以把向量想象成一条有方向的线段,线段上的
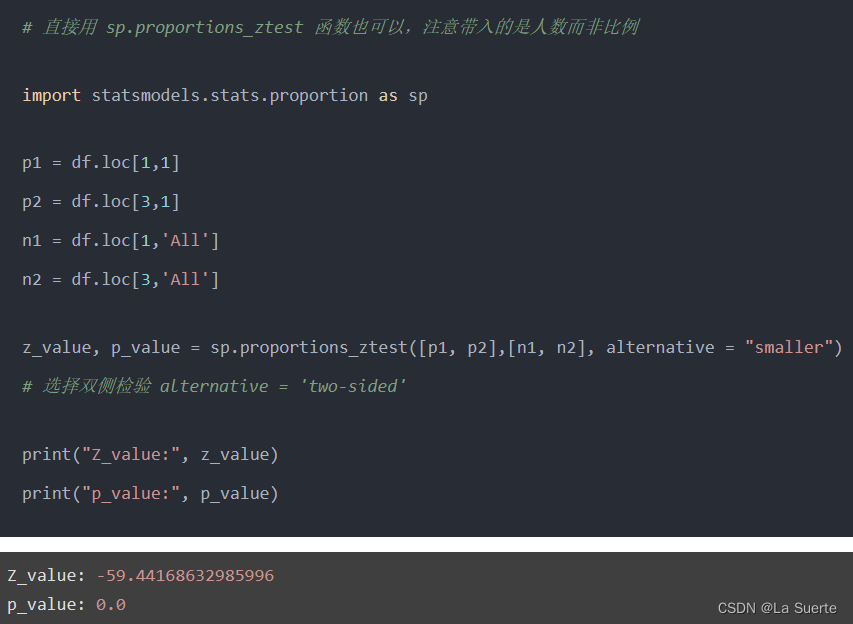
(五)AB测试及两个案例 学习简要笔记 #统计学 #CDA学习打卡
目录 一. AB测试简介 1)假设检验的一般步骤 2)基于假设检验的AB测试步骤 二. 案例1:使用基于均值的假设检验进行AB测试 1)原始数据 2)提出原假设H0和备择假设H1 3)使用均值之差的t检验,计算出t统计量的值和P值 4)进行假设检验 5)AA测试(简单随机抽样) 6)AA测试(分层抽样) 7)AA测试(系统抽样) 8)AB测试 三. 案例2:基于假设检
统计学-什么是单因素方差分析?
单因素方差分析(One-Way Analysis of Variance,简称ANOVA)是一种统计方法,用于比较三个或更多个组(或处理)之间的平均数是否存在显著差异。它适用于一个自变量(也称为因素)有多个水平的情况。 在单因素方差分析中,研究者将观察值按照一个特定的因素进行分类,并比较不同类别之间的平均数是否存在显著差异。这个因素可以是任何可以将观察值分成两个或更多组的变量,例如不同的治疗方法

时间序列数据挖掘--机器学习+统计学方法+kdd论文(三)----Tripoles: A New Class of Relationships in Time Series Data
时间序列数据挖掘(二) 机器学习+统计学+kdd1718论文机器学习下的时间序列统计学下的时间序列KDD2017论文 Tripoles: A New Class of Relationships in Time Series DataAbstract 摘要Keywords 关键词Introduction 介绍Definitions 定义Proposed approach 提出的方法naive

时间序列数据挖掘--机器学习+统计学方法+kdd论文(二)
时间序列数据挖掘(二) 机器学习+统计学+kdd1718论文机器学习下的时间序列RNNRNN使用领域 LSTM 统计学下的时间序列ARIMAARIMA的含义模型前提:平稳ARIMA的数学形式ARIMA模型建立步骤一些细节 机器学习+统计学+kdd1718论文 第二篇博客,接着上面的笔记写。 上一篇因为操作失误没有保存简直太失败了,这次要注意点。 这一篇主要记录我从统计学模型

时间序列数据挖掘--机器学习+统计学方法+kdd论文(一)
时间序列数据挖掘(一) 机器学习+统计学+kdd1718论文机器学习下的时间序列RNNRNN使用领域 LSTM 统计学下的时间序列kdd论文 机器学习+统计学+kdd1718论文 这是我第一次写博客,想记录下我上博士期间的学习记录和论文阅读感想。 距离我去读博还有一年,我想在这一年里多了解了解数据挖掘不同的方向,最终选择感兴趣的方向并一致研究下去。 我大致看了kdd2017和k
统计学-什么是 T 检验和 Z 检验?
t检验和z检验都是常用的统计推断方法,用于检验两个样本均值之间是否存在显著差异。它们各自基于不同的原理和假设,并在不同的情境下使用。 t检验,也称为student t检验,主要用于样本含量较小(例如n < 30),总体标准差未知,且数据服从正态分布的情境。它通过计算样本均值之间的差异以及这种差异相对于样本误差的大小来判断差异是否显著。t检验的原理在于利用t分布理论来推断两个样本均值之间是否存在显