precision专题

命名实体识别(NER)-模型评估:词级别评估、实体级别评估【Precision、Recall、F1】
一、概述 命名实体识别的评判标准:实体的边界是否正确;实体的类型是否标注正确。主要错误类型包括: 文本正确,类型可能错误;反之,文本边界错误,而其包含的主要实体词和词类标记可能正确。 对于二分类的模型,预测结果与实际结果分别可以取0和1。我们用N和P代替0和1,T和F表示预测正确和错误。将他们两两组合,就形成了下图所示的混淆矩阵(注意:组合结果都是针对预测结果而言的)。 由于1和0是数字

分类问题的评价指标:多分类【Precision、 micro-P、macro-P】、【Recall、micro-R、macro-R】、【F1、 micro-F1、macro-F1】
一、混淆矩阵 对于二分类的模型,预测结果与实际结果分别可以取0和1。我们用N和P代替0和1,T和F表示预测正确和错误。将他们两两组合,就形成了下图所示的混淆矩阵(注意:组合结果都是针对预测结果而言的)。 由于1和0是数字,阅读性不好,所以我们分别用P和N表示1和0两种结果。变换之后为PP,PN,NP,NN,阅读性也很差,我并不能轻易地看出来预测的正确性与否。因此,为了能够更清楚地分辨各种预测情
C++ ostream类包含的一个简单的用于控制格式的成员函数setf precision
ostream类包含一些可用于控制格式的成员函数 这里介绍一个简单的setf(),可用于避免科学计数法 std::cout.setf(std::ios_base::fixed, std::ios_base::floatfield);这设置了cout对象的一个标记,命令cout使用定点表示法 std::cout.precision(3);表示cout在使用定点表示法时,

ROC Recall Precision Accuracy FPR TPR TAR FAR
分类 混淆矩阵ROCAUCPR曲线回归 平均绝对误差平均平方误差Ref: 分类 混淆矩阵 probablity distribution True Positive(真正, TP):将正类预测为正类数.True Negative(真负 , TN):将负类预测为负类数.False Positive(假正, FP):将负类预测为正类数 →误报 (Type I error).
![Hdu 2256 Problem of Precision[矩阵快速幂 + 数学]](https://img-blog.csdn.net/20140917140816953?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMTM5NDM2Mg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
Hdu 2256 Problem of Precision[矩阵快速幂 + 数学]
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2256 题目的意思很简单粗暴。 简单思考一下,可以推出递推公式fi = fi-1 * a^2, a = sqrt(2) + sqrt(3)。 递推公式出来了,直接快速幂就好。。。但是, 我们发现10^9是很消耗精度, 可以肯定是很多的正确的做法,都是因为精度的问题而挂的。。。 思考无果后,

precision_score, recall_score, f1_score的计算
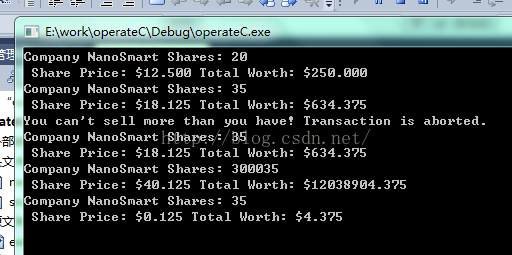
1 使用numpy计算true positives等 [python] view plain copy import numpy as np y_true = np.array([0, 1, 1, 0, 1, 0]) y_pred = np.array([1, 1, 1, 0, 0, 1]) # true positive TP = np.

variable precision SWAR算法
计算二进制形式中1的数量这种问题,在各种刷题网站上比较常见,以往都是选择最笨的遍历方法“蒙混”过关。在了解Redis的过程中接触到了variable precision SWAR算法(以下简称VP-SWAR算法),算法异常简洁,是目前已知的同类方法中最快的。但如果对于位运算不是很熟悉的话,却不一定容易理解,所以有必要记录一下。 下面先看看VP-SWAR算法的完整实现,然后
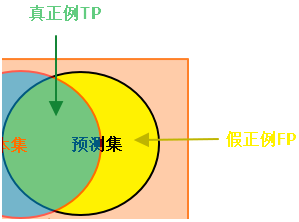
【AI】图示:精确度(查准率)Precision、召回率(查全率)Recall
对Precision、Recall的直译是“精确度”和“召回率”,第一次接触这两个词,很难从字面上知道它们的含义。而翻译成“查准率”和“查全率”就比较好理解,下面统一使用“查准率”和“查全率”。 1、真假正负例 真正例(True Positive, TP):预测值和真实值都为1 假正例(False Positive,FP):预测值为1,真实值为0 真负例(True Negative,TN)

python计算precision@k、recall@k和f1_score@k
sklearn.metrics中的评估函数只能对同一样本的单个预测结果进行评估,如下所示: from sklearn.metrics import classification_reporty_true = [0, 5, 0, 3, 4, 2, 1, 1, 5, 4]y_pred = [0, 2, 4, 5, 2, 3, 1, 1, 4, 2]print(classification_repo
![[机器学习] 第二章 模型评估与选择 1.ROC、AUC、Precision、Recall、F1_score](https://img-blog.csdnimg.cn/20210418025501926.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1RyYW5jZTk1,size_16,color_FFFFFF,t_70)
[机器学习] 第二章 模型评估与选择 1.ROC、AUC、Precision、Recall、F1_score
准确率(Accuracy) = (TP + TN) / 总样本 =(40 + 10)/100 = 50%。 定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。 精确率(Precision) = TP / (TP + FP) = 40/60 = 66.67%。它表示:预测为正的样本中有多少是真正的正样本,它是针对我们预测结果而言的。Precision又称为查准率。 召回率
DELL工作站微型计算机维修DELL Precision Tower 5810工作站深圳捷达工控维修
戴尔 Precision Tower 5810 紧凑、创新设计,动力强劲 体验生产力的演变 轻松处理资源耗尽、图形密集型工作负载,具有: • Dell Precision Optimizer v 2.0,通过优化设置来增强应用程序性能,最多可 • 英特尔® 至强® 处理器 E5-1600 v3 产品系列,包括精选高端 E5-2600 v3 CPU,提供快速完成复杂任务所需的性能和

【YOLO学习】召回率(Recall),精确率(Precision),平均正确率(Average_precision(AP) ),交除并(Intersection-over-Union(IoU))
摘要 在训练YOLO v2的过程中,系统会显示出一些评价训练效果的值,如Recall,IoU等等。为了怕以后忘了,现在把自己对这几种度量方式的理解记录一下。 这一文章首先假设一个测试集,然后围绕这一测试集来介绍这几种度量方式的计算方法。 大雁与飞机 假设现在有这样一个测试集,测试集中的图片只由大雁和飞机两种图片组成,如下图所示: 假设你的分类系统最终的目的是:能取出测试集中所有飞机的
Accuracy准确率,Precision精确率,Recall召回率,F1 score
真正例和真反例是被正确预测的数据,假正例和假反例是被错误预测的数据。然后我们需要理解这四个值的具体含义: TP(True Positive):被正确预测的正例。即该数据的真实值为正例,预测值也为正例的情况; TN(True Negative):被正确预测的反例。即该数据的真实值为反例,预测值也为反例的情况; FP(False Positive):被错误预测的正例。即该数据的真实值为反例,但被错误预
【目标检测】计算YOLOv5/7/8/9的TP, FP, FN, Recall和Precision
1. 设定IoU和Conf阈值 2. 保存推理结果的txt文件 3. 计算TP, FP, FN import osclasses = {0: "class 1",1: "class 2"}def iou(box1, box2):box1_x1 = box1[0] - box1[2] / 2box1_y1 = box1[1] - box1[3] / 2box1_x2 = box1[0] + b
![格式化字符串%[parameter][flags][field width][.precision][length]type讲解](/front/images/it_default2.jpg)
格式化字符串%[parameter][flags][field width][.precision][length]type讲解
格式化函数 string.format用来格式化字符串(按指定的规则连接字符串或输出其他变量并返回新的字符串) 。 使用方法与C语言的printf函数相同(实际上很多编程语言中都有同样的格式化函数).str = string.format(fm,...); 第一个参数用fm表示输出的格式,每个%符号后面是一个格式化表达式,每个格式化表达式按顺序对应后面的参数。 所以用了N个格式化表达式,就必须在
评价指标_Precision(精确率)、Recall(召回率)和Accuracy(准确率)区别和联系
Precision(精确率)、Recall(召回率)和Accuracy(准确率)是机器学习和信息检索领域常用的评价指标,它们用于评估分类器或检索系统的性能,但各自关注的方面略有不同。 Precision(精确率): 精确率是指分类器在预测为正例的样本中,真正为正例的比例。公式:Precision = TP / (TP + FP)其中,TP 表示真正例(True Positives),FP 表示
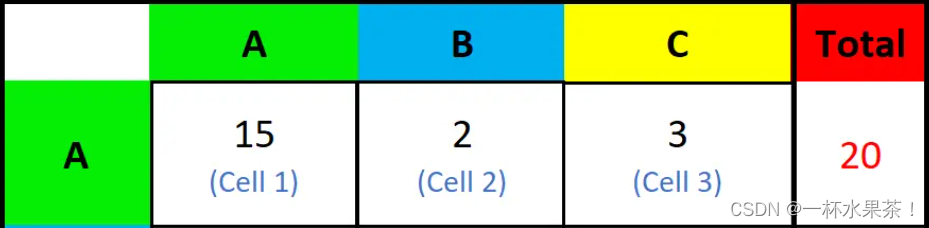
分类任务中的评估指标:Accuracy、Precision、Recall、F1
概念理解 T P TP TP、 T N TN TN、 F P FP FP、 F N FN FN精度/正确率( A c c u r a c y Accuracy Accuracy) 二分类查准率 P r e c i s i o n Precision Precision,查全率 R e c a l l Recall Recall 和 F 1 − s c o r e F1-score
增加负样本对二分类precision, recall指标的影响
背景 最近在做一个二分类模型,通过增加一半随机采样负样本(3000->6000, 负正样本比由0.74:0.25上升至0.87:0.12, 即3:1上升至7:1),精确率提高2%(89%->91),召回率降低6%(62->57%); 为什么在训练集中增加负样本能够提升精确率? 从精确率的公式上解释,precision = tp/(tp+fp), 增加负样本,实际上是增强模型对负样本的识别能力,因

PR曲线,ROC曲线,AUC指标等,Accuracy vs Precision
混淆矩阵(Confusion Matrix): PR Precision-Recall曲线,这个东西应该是来源于信息检索中对相关性的评价吧,precision就是你检索出来的结果中,相关的比率;recall就是你检索出来的结果中,相关的结果占数据库中所有相关结果的比率;所以PR曲线要是绘制的话,可以先对decision进行排序,就可以当作一个rank值来用了,然后把分类

Python3写精确率(precision)、召回率(recall)以及F1分数(F1_Score)
1. 四个概念定义:TP、FP、TN、FN 先看四个概念定义: - TP,True Positive - FP,False Positive - TN,True Negative - FN,False Negative 如何理解记忆这四个概念定义呢? 举个简单的二元分类问题 例子: 假设,我们要对某一封邮件做出一个判定,判定这封邮件是垃圾邮件、还是这封邮件不是垃圾邮件? 如果判定
UndefinedMetricWarning: Precision and F-score are ill-defined and being set to 0.0 in labels
预测的标签中缺少实际的标签。 避免警告的方法如下: import warningswarnings.filterwarnings("ignore")
Hibernate 配置文件precision与scale的作用
Oracle使用标准、可变长度的内部格式来存储数字。这个内部格式精度可以高达38位。 NUMBER数据类型可以有两个限定符,如: column NUMBER ( precision, scale) precision表示数字中的有效位。如果没有指定precision的话,Oracle将使用38作为精度。 scale表示数字小数点右边的位数,scale默认设置为0.
评价指标对比:准确率(accuracy)、精确率(Precision)、召回率(Recall)、IOU、Kappa系数
https://blog.csdn.net/zsc201825/article/details/93487506
关于机器学习中准确率(Accuracy) | 查准率(Precision) | 查全率(Recall)
准确率(Accuracy) | 查准率(Precision) | 查全率(Recall) 在机器学习中,对于一个模型的性能评估是必不可少的。准确率(Accuracy)、查准率(Precision)、查全率(Recall)是常见的基本指标。 为了方便说明,假设有以下问题场景: 一个班有50人,在某场考试中有40人及格,10人不及格。 现在需要根据一些特征预测出所有及格的学生。 在某一
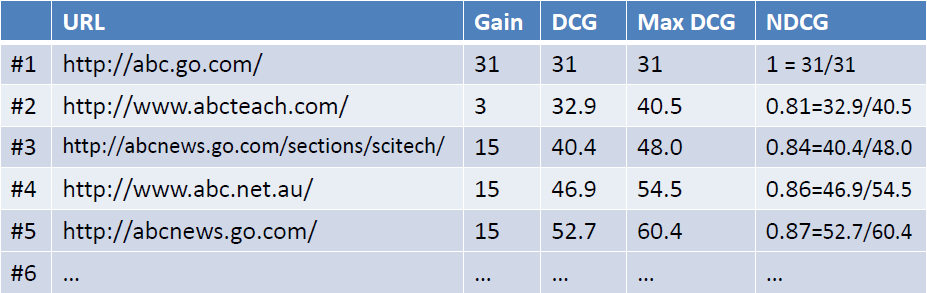
MAP(Mean Average Precision):
MAP(Mean Average Precision): 单个主题的平均准确率是每篇相关文档检索出后的准确率的平均值。主集合的平均准确率(MAP)是每个主题的平均准确率的平均值。MAP 是反映系统在全部相关文档上性能的单值指标。系统检索出来的相关文档越靠前(rank 越高),MAP就可能越高。如果系统没有返回相关文档,则准确率默认为0。 例如:假设有两个主题,主题1有4个
理解查全率(precision)与查准率(recall)
理解查全率与查准率 1. 概念解读2. F 1 F_1 F1度量3. F β F_\beta Fβ度量 1. 概念解读 在一个二分类问题中,非对既是错 真实情况\预测情况positivenegativeTrueTPTNFalseFPFN Notice: 上面的图表是个反例,错误的原因是T\F的使用,T代表着预测正确,F代表着预测错误。 真实情况\预测情况positi