本文主要是介绍关于机器学习中准确率(Accuracy) | 查准率(Precision) | 查全率(Recall),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
准确率(Accuracy) | 查准率(Precision) | 查全率(Recall)
在机器学习中,对于一个模型的性能评估是必不可少的。准确率(Accuracy)、查准率(Precision)、查全率(Recall)是常见的基本指标。
为了方便说明,假设有以下问题场景:
一个班有50人,在某场考试中有40人及格,10人不及格。 现在需要根据一些特征预测出所有及格的学生。
在某一模型执行下来,给出了39人,其中37人确实及格了,剩下2人实际上不及格。
样本
要了解这些指标的含义,首先需要了解两种样本
正样本:即属于某一类(一般是所求的那一类)的样本。在本例中是[及格的学生][2]。
负样本:即不属于这一类的样本。在本例中是[不及格的学生][2]。
识别结果
于是我们可以得到下面一张表:
| 正类 | 负类 | |
|---|---|---|
| 被检索 | True Positive | False Negative |
| 被检索 | False Positive | True Negative |
TP:被检索到正样本,实际也是正样本(正确识别)
在本例表现为:预测及格,实际也及格。
FP:被检索到正样本,实际是负样本(一类错误识别)
在本例表现为:预测及格,实际不及格。
FN:未被检索到正样本,实际是正样本。(二类错误识别)
在本例表现为:预测不及格,实际及格了。
TN:未被检索到正样本,实际也是负样本。(正确识别)
在本例表现为:预测不及格,实际也不及格。
指标计算
有了上述知识,就可以计算各种指标了。
Accuracy(准确率)
分类正确的样本数 与 样本总数之比。即:(TP + TN) / ( ALL ).
在本例中,正确分类了45人(及格37 + 不及格8),所以 Accuracy = 45 / 50 = 90%.
Precision(精确率、查准率)
被正确检索的样本数 与 被检索到样本总数之比。即:TP / (TP + FP).
在本例中,正确检索到了37人,总共检索到39人,所以 Precision = 37 / 39 = 94.9%.
Recall (召回率、查全率)
被正确检索的样本数 与 应当被检索到的样本数之比。即:TP / (TP + FN).
在本例中,正确检索到了37人,应当检索到40人,所以 Recall = 37 / 40 = 92.5%.
为什么要不同的指标
根据上边公式的不同,可以借此理解不同指标的意义。
准确率是最常用的指标,可以总体上衡量一个预测的性能。但是某些情况下,我们也许会更偏向于其他两种情况。
「宁愿漏掉,不可错杀」
在识别垃圾邮件的场景中可能偏向这一种思路,因为我们不希望很多的正常邮件被误杀,这样会造成严重的困扰。
因此,Precision 将是一个被侧重关心的指标。
「宁愿错杀,不可漏掉」
在金融风控领域大多偏向这种思路,我们希望系统能够筛选出所有有风险的行为或用户,然后交给人工鉴别,漏掉一个可能造成灾难性后果。
因此,Recall 将是一个被侧重关心的指标。
综合评价 (F-Score)
更多时候,我们希望能够同时参考 Precision 与 Recall,但又不是像 Accuracy 那样只是泛泛地计算准确率,此时便引入一个新指标 F-Score,用来综合考虑 Precision 与 Recall.
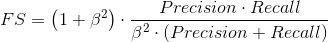
其中 β 用于调整权重,当 β=1 时两者权重相同,简称为 F1-Score.
若认为 Precision 更重要,则减小 β,若认为 Recall 更重要,则增大 β.
本文转载链接:https://www.jianshu.com/p/8b7324b0f307
这篇关于关于机器学习中准确率(Accuracy) | 查准率(Precision) | 查全率(Recall)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









