accuracy专题

caffe绘制训练过程中的accuracy、loss曲线
训练模型并保存日志文件 首先建立一个训练数据的脚本文件train.sh,其内容如下,其中,2>&1 | tee examples/mnist/mnist_train_log.log 是log日志文件的保存目录。 #!/usr/bin/env sh set -e TOOLS=./build/tools $TOOLS/caffe train --solver=examp
![【Keras】keras model.compile(loss='目标函数 ', optimizer='adam', metrics=['accuracy'])](/front/images/it_default.jpg)
【Keras】keras model.compile(loss='目标函数 ', optimizer='adam', metrics=['accuracy'])
讲解了各种loss https://www.cnblogs.com/smuxiaolei/p/8662177.html

03 TensorFlow 2.0:TOPK Accuracy实战
这江山风雨 岁月山河 刀光剑影 美了多少世间传说 且看他口若悬河 衣上有风尘 却原来是一位江湖说书人 《说书人》 在分类问题中会遇到TO

ROC Recall Precision Accuracy FPR TPR TAR FAR
分类 混淆矩阵ROCAUCPR曲线回归 平均绝对误差平均平方误差Ref: 分类 混淆矩阵 probablity distribution True Positive(真正, TP):将正类预测为正类数.True Negative(真负 , TN):将负类预测为负类数.False Positive(假正, FP):将负类预测为正类数 →误报 (Type I error).
Caffe学习:使用pycaffe绘制loss、accuracy曲线
直接使用pycaffe进行网络训练与测试无法得到loss、accuracy的直观信息,用下面代码可以实现loss、accuracy曲线绘制: #!/usr/bin/env python# 导入绘图库from pylab import *import matplotlib.pyplot as plt# 导入"咖啡"import caffe# 设置为gpu模式caffe.set_devic

论文笔记:EAST: an Efficient and Accuracy Scene Text detection pipeline
EAST: an Efficient and Accuracy Scene Text detection pipeline 直接在整张图像上回归目标和它的几何轮廓,模型是全卷积神经网络,每个像素位置都输出密集的文字预测。排除了生成候选目标,生成文字区域,字母分割(candidate proposal, text region formation, word partition)等中间过程。后续过

基于 FastAI 文本迁移学习的情感分类(93%+Accuracy)
前言 系列专栏:【深度学习:算法项目实战】✨︎ 涉及医疗健康、财经金融、商业零售、食品饮料、运动健身、交通运输、环境科学、社交媒体以及文本和图像处理等诸多领域,讨论了各种复杂的深度神经网络思想,如卷积神经网络、循环神经网络、生成对抗网络、门控循环单元、长短期记忆、自然语言处理、深度强化学习、大型语言模型和迁移学习。 情感分析是指利用自然语言处理、文本分析、计算语言学和生物统计学,系统
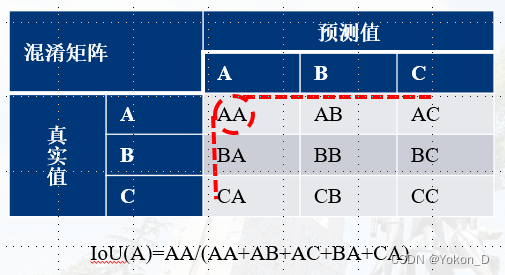
Overall Accuracy(OA)、Average Accuracy(AAcc)计算公式
四个重要的指标:True Positive(TP)、False Positive(FP)、True Negative(TN)和False Negative(FN)。TP表示分类器预测结果为正样本,实际也为正样本,即正样本被正确识别的数量;FP表示分类器预测结果为正样本,实际为负样本,即误报的负样本数量;TN表示分类器预测结果为负样本,实际也为负样本,即负样本被正确识别的数量;FN表示分类
模型准确率accuracy
以二分类问题为例: 假如:共有365个水果,只有两种类别,橙子和橘子. 准确率=分类正确数/365x100% 不足:假如365个水果当中有364个橙子,1个橘子。现有分类器,无论来什么水果都判定为橙子。准确率可达99.7%,但是显而易见这个模型根本没有判别能力。再换一组数据,准确率将直线下降。 上面这种现象称为label不平衡 以准确率判定模型是否优秀不够科学,所以引入ROC曲线。
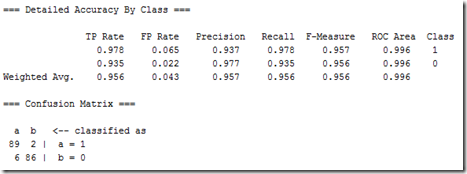
【转】weka里Detailed Accuracy By Class和 Confusion Matrix的含义
confusion matrix通常称为contingency table,我们现在讨论的case里有两个class。这个matrix可以非常大。正确分类的instances数是matrix的对角线上数字的和,其他的都是不正确分类的。斜对角线上的数字为假正和假负。 True positive(TP) rate,被正确分类为class x的比率。与recall相同。=正确分类为class

keras训练模型时绘出每个epoch的accuracy和loss
keras训练模型时绘出每个epoch的accuracy和loss 一、绘制模型训练过程中的accuracy和loss二、绘制训练好的模型测试过程中的accuracy和loss1.交叉熵损失函数2.评估accuracy_score 一、绘制模型训练过程中的accuracy和loss # 绘制图形以确保准确性# 训练集准确率plt.plot(history.history['
Accuracy准确率,Precision精确率,Recall召回率,F1 score
真正例和真反例是被正确预测的数据,假正例和假反例是被错误预测的数据。然后我们需要理解这四个值的具体含义: TP(True Positive):被正确预测的正例。即该数据的真实值为正例,预测值也为正例的情况; TN(True Negative):被正确预测的反例。即该数据的真实值为反例,预测值也为反例的情况; FP(False Positive):被错误预测的正例。即该数据的真实值为反例,但被错误预
tensorflow笔记 tf.metrics.accuracy
tf.metrics.accuracy用于计算模型输出的准确率 tf.metrics.accuracy(labels,predictions,weights=None,metrics_collections=None,updates_collections=None,name=None)return accuracy, update_op 参数: labels 标签的真实值 predict
评价指标_Precision(精确率)、Recall(召回率)和Accuracy(准确率)区别和联系
Precision(精确率)、Recall(召回率)和Accuracy(准确率)是机器学习和信息检索领域常用的评价指标,它们用于评估分类器或检索系统的性能,但各自关注的方面略有不同。 Precision(精确率): 精确率是指分类器在预测为正例的样本中,真正为正例的比例。公式:Precision = TP / (TP + FP)其中,TP 表示真正例(True Positives),FP 表示
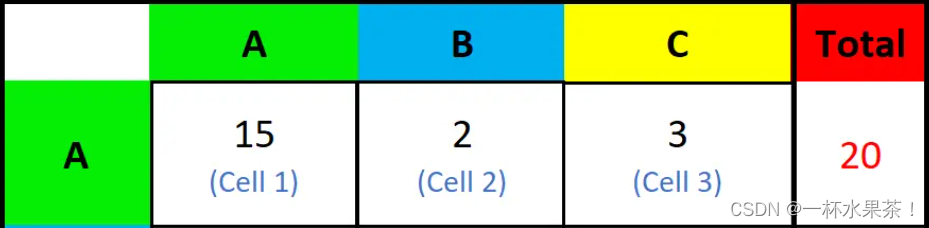
分类任务中的评估指标:Accuracy、Precision、Recall、F1
概念理解 T P TP TP、 T N TN TN、 F P FP FP、 F N FN FN精度/正确率( A c c u r a c y Accuracy Accuracy) 二分类查准率 P r e c i s i o n Precision Precision,查全率 R e c a l l Recall Recall 和 F 1 − s c o r e F1-score

PR曲线,ROC曲线,AUC指标等,Accuracy vs Precision
混淆矩阵(Confusion Matrix): PR Precision-Recall曲线,这个东西应该是来源于信息检索中对相关性的评价吧,precision就是你检索出来的结果中,相关的比率;recall就是你检索出来的结果中,相关的结果占数据库中所有相关结果的比率;所以PR曲线要是绘制的话,可以先对decision进行排序,就可以当作一个rank值来用了,然后把分类
Training LeNet on MNIST with Caffe|保存log绘制accuracy loss曲线
1、准备数据:下载mnist数据 cd $CAFFE_ROOT./data/mnist/get_mnist.sh 2、将格式转为lmdb格式 ./examples/mnist/create_mnist.sh lmdb数据在examples/mnist路径下 3、分类模型:LeNet 模型结构:$CAFFE_ROOT/examples/mnist/lenet
评价指标对比:准确率(accuracy)、精确率(Precision)、召回率(Recall)、IOU、Kappa系数
https://blog.csdn.net/zsc201825/article/details/93487506
TI毫米波雷达开发——High Accuracy Demo 串口数据接收及TLV协议解析 matlab 源码
TI毫米波雷达开发——串口数据接收及TLV协议解析 matlab 源码 前置基础源代码功能说明功能演示视频文件结构01.bin / 02.binParseData.mread_file_and_plot_object_location.mread_serial_port_and_plot_object_location.m 函数解析configureSport(comportSnum)rea
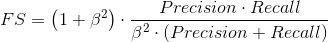
关于机器学习中准确率(Accuracy) | 查准率(Precision) | 查全率(Recall)
准确率(Accuracy) | 查准率(Precision) | 查全率(Recall) 在机器学习中,对于一个模型的性能评估是必不可少的。准确率(Accuracy)、查准率(Precision)、查全率(Recall)是常见的基本指标。 为了方便说明,假设有以下问题场景: 一个班有50人,在某场考试中有40人及格,10人不及格。 现在需要根据一些特征预测出所有及格的学生。 在某一
YOLOv4阅读笔记(附思维导图)!YOLOv4: Optimal Speed and Accuracy of Object Detection
今天刷看到了YOLOv4之时,有点激动和兴奋,等了很久的YOLOv4,你终究还是出现了 论文地址:https://arxiv.org/pdf/2004.10934.pdf GitHub地址:https://github.com/AlexeyAB/darknet 觉得作者很地道,论文附上开源,没有比这更开心的事情了吧! 首先附上对论文总结的思维导图,帮助大家更好的理解! (思维

机器学习性能评估指标---准确率(Accuracy), 精确率(Precision), 召回率(Recall)
分类 混淆矩阵1 True Positive(真正, TP):将正类预测为正类数.True Negative(真负 , TN):将负类预测为负类数.False Positive(假正, FP):将负类预测为正类数 → → 误报 (Type I error).False Negative(假负 , FN):将正类预测为负类数 → → 漏报 (Type II error).


在分类任务中准确率(accuracy)、精确率(precision)、召回率(recall)和 F1 分数是常用的性能指标,如何在python中使用呢?
在机器学习和数据科学中,准确率(accuracy)、精确率(precision)、召回率(recall)和 F1 分数是常用的性能指标,用于评估分类模型的性能。 1. 准确率(Accuracy): 准确率是模型预测正确的样本数占总样本数的比例。 from sklearn.metrics import accuracy_score y_true = [0, 1, 1, 0, 1, 1]
深度学习常用评价指标(Accuracy、Recall、Precision、HR、F1 score、MAP、MRR、NDCG)——推荐系统
混淆矩阵 混淆矩阵P(Positives)N(Negatives)T(Ture)TP:正样本,预测结果为正TN:负样本,预测结果为正F(False)FP:正样本,预测结果为负FN:负样本,预测结果为负 总结 AccuracyRecallPrecisionHits RatioF1 scoreMean Average PrecisionMean Reciprocal RankNormalized

深度学习分类问题中accuracy等评价指标的理解
在处理深度学习分类问题时,会用到一些评价指标,如accuracy(准确率)等。刚开始接触时会感觉有点多有点绕,不太好理解。本文写出我的理解,同时以语音唤醒(唤醒词识别)来举例,希望能加深理解这些指标。 1,TP / FP / TN / FN 下表表示为一个二分类的混淆矩阵(多分类同理,把不属于当前类的都认为是负例),表中的四个参数均用两个字母表示,第一个字母表示判断结果正确与否(正确用T(