本文主要是介绍MAP(Mean Average Precision):,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MAP(Mean Average Precision):
单个主题的平均准确率是每篇相关文档检索出后的准确率的平均值。主集合的平均准确率(MAP)是每个主题的平均准确率的平均值。MAP 是反映系统在全部相关文档上性能的单值指标。系统检索出来的相关文档越靠前(rank 越高),MAP就可能越高。如果系统没有返回相关文档,则准确率默认为0。
例如:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1, 2, 4, 7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均准确率为(1/1+2/2+3/4+4/7)/4=0.83。对于主题2,平均准确率为(1/1+2/3+3/5+0+0)/5=0.45。则MAP= (0.83+0.45)/2=0.64。”
NDCG(Normalized Discounted Cumulative Gain):
计算相对复杂。对于排在结位置n处的NDCG的计算公式如下图所示:
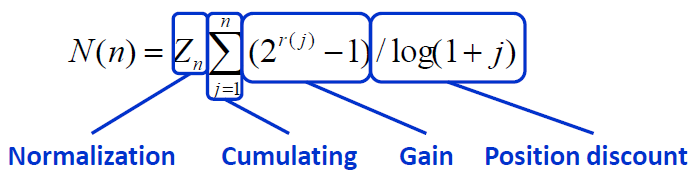
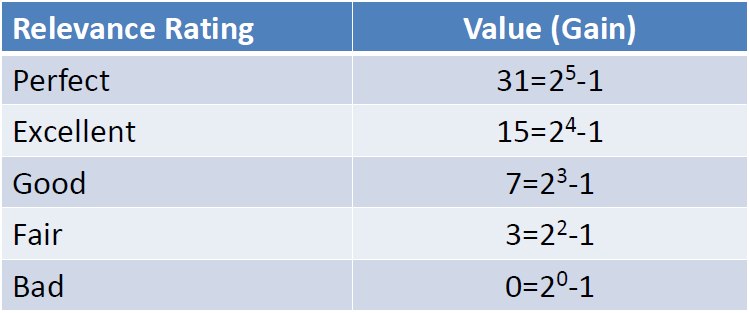
(应该还有r=1那一级,原文档有误,不过这里不影响理解)
例如现在有一个query={abc},返回下图左列的Ranked List(URL),当假设用户的选择与排序结果无关(即每一级都等概率被选中),则生成的累计增益值如下图最右列所示:
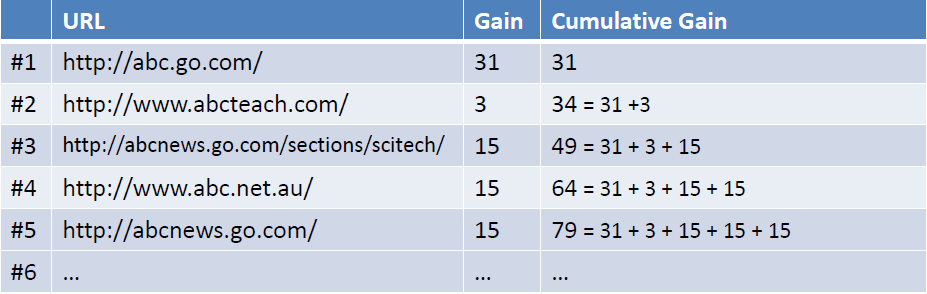
考虑到一般情况下用户会优先点选排在前面的搜索结果,所以应该引入一个折算因子(discounting factor): log(2)/log(1+rank)。这时将获得DCG值(Discounted Cumulative Gain)如下如所示:
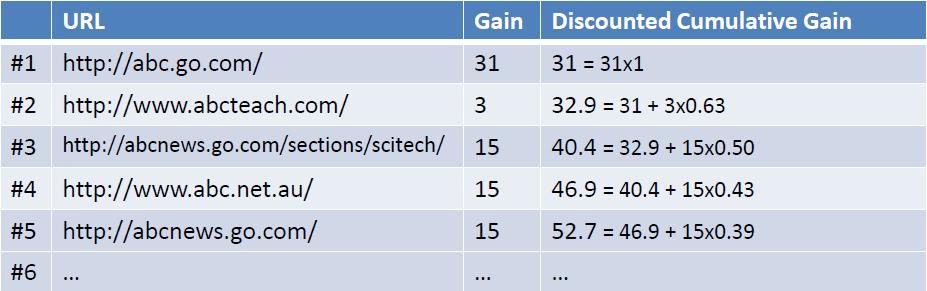
最后,为了使不同等级上的搜索结果的得分值容易比较,需要将DCG值归一化的到NDCG值。操作如下图所示,首先计算理想返回结果List的DCG值:
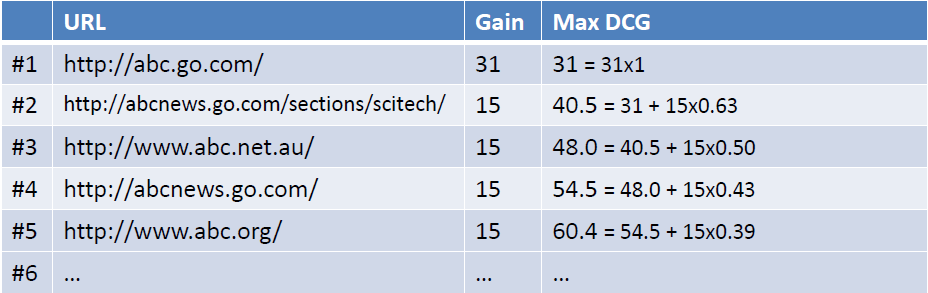
然后用DCG/MaxDCG就得到NDCG值,如下图所示:
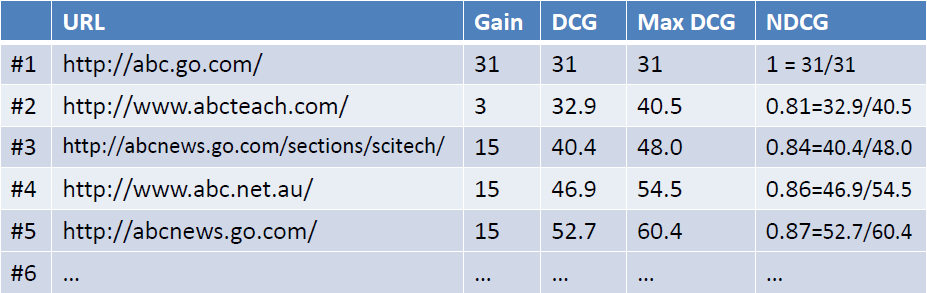
这篇关于MAP(Mean Average Precision):的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



