本文主要是介绍TCGA相关分析之数据筛选 | python从TCGA-GBM的RNA-seq表达数据count中筛选出各genes对应的案例cases的表达量count矩阵,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
接上一篇文章,现在开始筛选数据组成count矩阵。
上一篇:TCGA下载GBM患者的RNA-seq数据
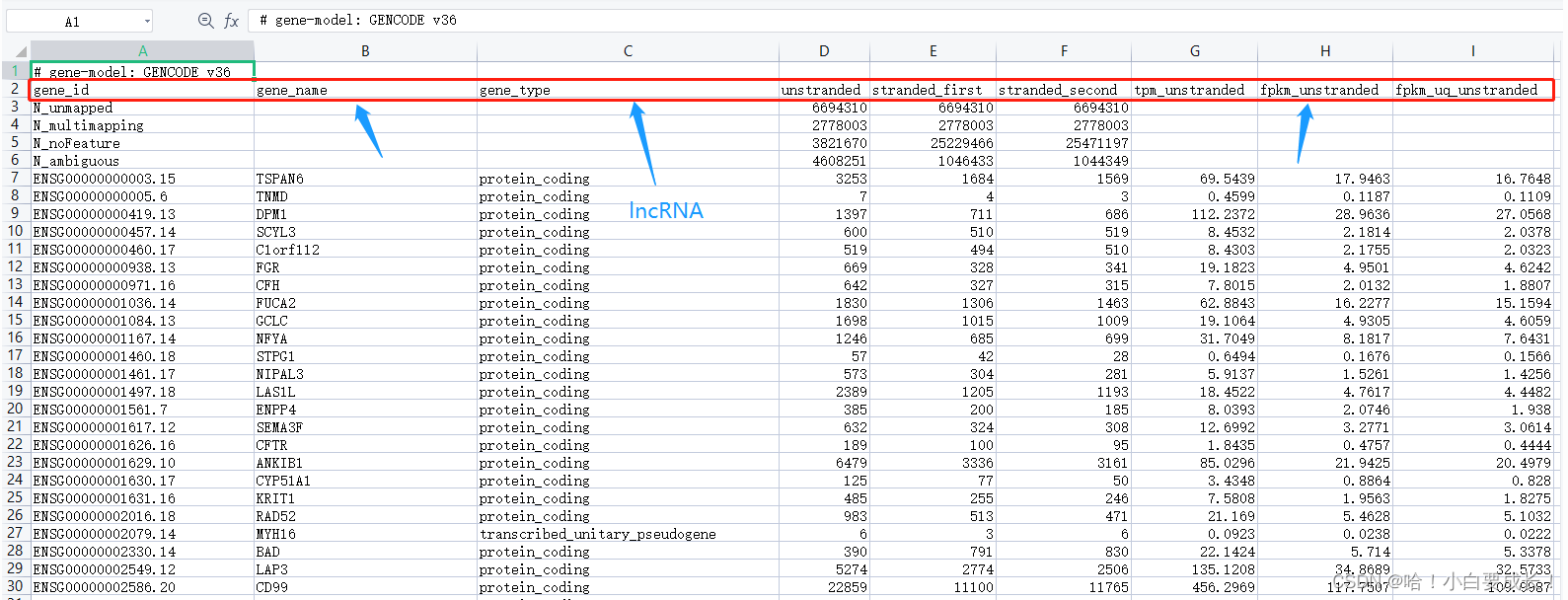
上一篇结束,下载到初始数据(图一图二是下载之后的文件夹以及每一个文件夹中的count数据文件)

需要从每一个count数据文件中筛选出gene_name、gene_type为lncRNA、FPKM表达量,效果图如下:


由于不会R语言,就用python来实现
步骤:
- 从每一个文件夹中提取出来count数据文件,整理到一个新文件夹中
- 将所有count数据文件中需要的列提取出来,整合到一个文件中
- 在整合文件中手动复制粘贴添加 gene_id、gene_name、gene_type 列数据即可(手动更快,因为这些都是一样的,不需要筛选)
1、从每一个文件夹中提取出来count数据文件,整理到一个新文件夹中
参照:python | 从指定文件夹中筛选出xml文件,复制到新的指定路径
2、将所有count数据文件中需要的列提取出来,整合到一个文件中
由于不方便对 tsv 文件操作行列,所以 tsv 转成 xls 来操作,这里就比较繁琐,需要来回转换。
2.1 tsv 转成 xls
最初由于 xlrd 模块不好用,比如更新带来的报错等,所以采用了 xlsx 格式。但是后面提取列的时候,openpyxl 模块又不支持行列操作,只能针对单元格,不得已又从 xlsx 转成 xls,绕了一圈,工作量加倍 (ˉ▽ˉ;)…
这里给出转 xls 和 xlsx 都能用的代码:
参照:python | 批量将 tsv 文件转成 xls 文件,保存到新路径
不过需要注意,不久pandas将不再支持xls,也就是说不能使用 pandas 保存为 xls 格式了,但是 xlsx 依旧能用。之后可能需要寻找其他方法,或者 tsv-xlsx-xls 间接转换。
2.2 提取出每一个 xls 文件中的所需列
这里说一下,因为使用 xlrd 模块,可直接通过 sheet.row[i] 和 sheet.col[i] 获取行和列的内容,所以使用 xls 格式。由于 openpyxl 模块只能对单元格操作,不合适,所以不用 xlsx 格式。
参照:python | 批量提取出每一个 xls 文件中的所需列,并重命名列名,保存到同一个新的 xls 文件中
这一篇就写到这里,下一篇继续前文工作,实现Person相关分析,后续实现共表达网络构建
这篇关于TCGA相关分析之数据筛选 | python从TCGA-GBM的RNA-seq表达数据count中筛选出各genes对应的案例cases的表达量count矩阵的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




