本文主要是介绍手势识别2020(一)Weakly-supervised Domain Adaptation via GAN and Mesh Model for Estimating 3D Hand Poses,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《Weakly-supervised Domain Adaptation via GAN and Mesh Model for Estimating 3D Hand Poses Interacting Objects》论文解读
- Abstract
- 1. Introduction
- 2. Domain Adaptation Framework
- 2.1. Training
- 2.1.1. 2D heatmap supervision L~Heat~
- 2.1.2. Image-level supervision L~Img~&&L~d~
- 2.1.3. 3D skeleton supervision L~Pos~
- 2.2. Testing

原文:Weakly-supervised Domain Adaptation via GAN and Mesh Model for Estimating 3D Hand Poses Interacting Objects
收录:CVPR2020
代码:Will be available soon.
Abstract
尽管最近在手部姿态估计方面取得成功,但是 基于RGB图像的3D手部姿态估计(HPE)方法 在 手-物交互(HOI) 场景中仍然存在挑战,因为存在严重自遮挡以及背景杂乱等问题。最近这段时间,不论是在真实领域还是在合成领域,基于RGB的HOI数据都一直在被收集,但是数据集的大小还远远不够我们去处理人手交互问题,而且也缺乏真实样本的3D姿态标注,尤其是在遮挡情况下。
该论文提出了一个端到端可训练的网络,在手物交互领域能够适应单手的手物交互,同时学习HPE。
※论文核心思想:
- 通过 生成对抗网络(GAN)的2D像素级引导 和 网格渲染器(MR)的3D网格引导,图像空间发生域自适应(Domain Adaptation);
- GAN能准确地对齐双手,MR能有效地填充被遮挡的像素点;
1. Introduction
- 一个优秀的手部姿态估计方法具备以下属性:
- 有一个能够学习2D-3D高度非线性映射的深度学习方法;
- 有一个能够充分训练卷积神经网络(CNNs)的可用大型数据集。
- 对于手物交互也存在挑战,即:
- 严重的自遮挡
- 复杂的背景;
- 3D数据集标注以及大小。
- 现阶段,一个完整的、并且能自动去标注有着严重遮挡问题3D关节点位置的网络不存在。因此对于数据集3D标注,有以下方法:
- 需要大量的人力来不断检查和改进标签;
- 使用磁性传感器或者数据手套;
- 使用合成数据。
由于数据集包含 纯手部 以及 HOI ,在一些工作中对这两种数据集来进行测试,对比两者的手姿态估计器的准确性。分别使用 HOI 以及 hand-only 来训练的手部姿态估计模型,最后发现在纯手部测试图像上使用 HOI 数据集训练的模型表现并不好,但在 HOI 测试图像上的精度提高。
工作主要目标就是 在手物交互(HOI)域实现单手交互。
主要贡献:
- 提出了一种新的端到端学习框架:用于同时进行域自适应和HPE。利用2D目标分割掩模和hand-only数据的3D位姿标签,在弱监督下训练域自适应网络。没有使用带3D注释的HOI数据,但提高了HOI下的手姿态估计的精度;
- 域自适应在图像空间中通过两种导向实现。首先研究两种图像生成的方法:①GAN; ②使用估计好的3D网格(Mesh) 和纹理(Texture) 的网格渲染器。最后实现将输入的HOI图像转换为分割和去遮挡的hand-only图像,有效地提高了HPE的精度;
2. Domain Adaptation Framework
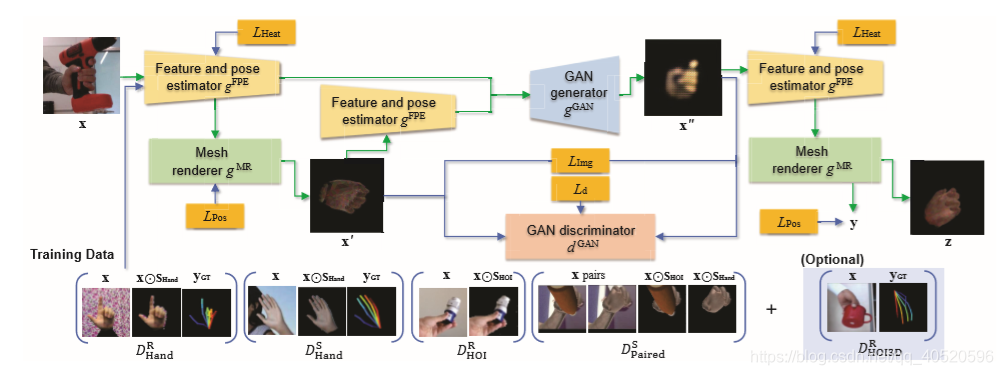
上图是3D手部姿态估计框架示意图。域自适应网络输入一个 HOI 的RGB图像 x,并提取该图像的2D特征图 f 和关节点热图 h (通过2D特征和姿态估计器 gFPE 来实现)。在此基础上,网格渲染器 gMR 来重构相应的3D网格 m 和纹理 t,然后得到一个初始的 hand-only 图像 x’ 。然后分别从 x 和 x’ 中提取2D map {f,h} 、 {f’,h’} ,然后都输入到GAN的生成器 gGAN,生成一个更精细的hand-only图像 x’’。最后,对 x’’ 应用 gFPE 和 gMR 生成网格 m’’,然后分为两路:1) 生成对应的 hand-only 图像 z ; 2) 生成骨关节姿态 y,绿色和蓝色箭头分别表示数据处理和监督。

| notation | size | meaning |
|---|---|---|
| X | 256×256×3 | RGB图像 ( x、x’、x’’、z) |
| Y | 21×3 | 3D骨关节空间姿态 ( x、x’、x’’、z) |
| F | 128×32×32 | 2D特征空间 |
| H | 21×32×32 | 2D热图空间 |
| M | 778×1538 | 3D网格空间(778个顶点×1538个面) |
| T | 1538×3 | 网格纹理(3×1538个面) |
| gFPE | X → F×H | 2D特征和位姿估计器 |
| gHME | F×H → M | 手网格估计 |
| gTex | F×H → T | 纹理估计 |
| gNR | M×T → X | Neural renderer |
| gReg | M → Y | 手关节回归 |
| gMR | F×H →X×Y | 网格渲染器 |
| gGAN | F×H×F×H → X | GAN 生成器 |
| d1GAN、d2GAN | X → R | GAN 判别器 |
| fDAN | X → X×Y | 域自适应网络 |
- fDAN 由 gMR 和 gFPE 组成;
- gMR 由 gHME、gTex、gNR、gReg 组成。
2.1. Training
采取弱监督的学习方式的,因为它没有使用3D骨骼关节的GT值或HOI图像的hand-only 分割掩码。当然,若为HOI图像提供3D关节标注,算法也可以选择性地利用它们。
使用的数据集如下:

2.1.1. 2D heatmap supervision LHeat

- hGT :hand-only 图像的2D热图GT值;
- gFPE :该结构初始权重采用 Zimmermann and Brox 的网络权值。
2.1.2. Image-level supervision LImg&&Ld
训练数据集D中的每个输入图像 x 都有相应的2D分割掩模 s,其用于提取手部区域 x ⊙ s x\odot s x⊙s,其中 ⊙ \odot ⊙ 代表两个大小相同矩阵对应的元素相乘。

其中后面两个式子在使用数据集 D H O I R = ( x , s H O I ) D_{HOI}^{R}={(x,s_{HOI})} DHOIR=(x,sHOI) 时等于0,因为该数据集没有 sHand。

- D H O I S D_{HOI}^{S} DHOIS:含 sHand、sHOI,而 D H O I R 、 D H a n d R 、 D H a n d S D_{HOI}^{R}、D_{Hand}^{R}、D_{Hand}^{S} DHOIR、DHandR、DHandS只含其中之一。
2.1.3. 3D skeleton supervision LPos

- yGT :hand-only 图像的3D骨架GT值。
2.2. Testing
将训练好的DAN网络应用到测试图像 x 上,测试时除了不提供监督外,其流程与训练过程相同,参数向量用 p 来表示,那么其更新规则如何?

- [y]XY :参数为p(t)时输出的3D关节空间位置 y 在图像上的投影;
- j :通过x’'上估计的2D热图h”获得的2D骨关节。
这篇关于手势识别2020(一)Weakly-supervised Domain Adaptation via GAN and Mesh Model for Estimating 3D Hand Poses的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






