本文主要是介绍[上海科技大学论文]相机定位增强实现视觉LiDAR点云对齐(Camera Poses Augmentation with Large-scale LiDAR Maps)论文记录【适用大规模点云重建】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
上海科技大学论文——相机定位增强实现视觉LiDAR点云对齐。
原文题目:CP+: Camera Poses Augmentation with Large-scale LiDAR Maps
原文链接:https://arxiv.org/pdf/2302.12198.pdf
摘要
大规模彩色点云在导航或者场景显示方面有许多的优点。
我们现在依靠广泛用于重建任务的相机和激光雷达就可以获得这样的彩色点云。
然而在许多现有的框架中这两种传感器的信息没有很好的融合进而导致着色效果差、相机姿态不准确、点着色结果受损。
文章为解决这一对齐问题提出了一种名为Camera Pose Augmentation (CP+) 的新框架来改进相机的姿态并将其与激光雷达的点云直接对齐。
初始的粗略相机姿态由激光雷达惯性(LiDAR-Inertial)或者激光雷达惯性视觉测距(LiDAR-Inertial-Visual)给出,具有近似的外部参数和时间同步。
改进图像对齐的关键步骤包括选择与每个相机视图中的感兴趣区域对应的点云,从该点云提取可靠的边缘特征,以及导出2D-3D线的对应关系,用这些关系来迭代最小化重投影误差(re-projection error)。
课题介绍
点云和光学图像应用于场景理解,相机、激光雷达、IMU被广泛应用于基础重建和建模任务。然而将这两种模式结合起来重建RGB彩色点云是个非常棘手的问题。
一种简单方法只需校准所有传感器的外部姿态并利用硬件同步来匹配刚性安装的传感器。但在实际应用中这种校准和硬件同步通常不可用或者误差太大。所以需要用更先进的方法来生成良好的点云着色。
点云着色的流行方法是基于perspective-n-Point(该方法基于PnP)的算法。这种算法可以很好地处理2D-3D配准问题。
然而对于大多说真实情况来说找到这些对应关系是困难的。因此有很多方法只使用相同的传感器来完成这些任务。这表明了模态差距是很难克服的。
直观的想法是通过使用Structure-from-Motion(SFM)方法构建一个包含一系列图像的小型3D地图后利用ICP类方法将生成的地图匹配到先前的激光雷达地图中。这种方法是计算密集型的。此外这种方法需要特征描述符或者强度,这在不断变化的环境下可能不一致。
由于直接配准两种不同类型的传感器信息容易出错。文章针对基于几何特征的方法进行研究。 几何结构上的特征可以在2D和3D数据中捕获并且不会受到诸如不同照明之类的动态元素的影响。
此外,由于大多数场景中边缘特征的丰富性,几何边缘的提取和匹配使得解决2D-3D配准问题成为可能。
然而直接的2D-3D几何线对应匹配也容易导致一些配准误差。去解决这些挑战,文章提出了一种新的框架,用于利用激光雷达映射结果来增强相机定位来实现点云着色。框架还包含了对输入点云和图像的一些去噪预处理。另外,根据粗略的相机姿态和固有参数可以通过选择合适的待处理点云(ROI)来加速2D-3D线匹配。文章的实验如下图所示,算法适用于不同类型的激光雷达。

文章的主要工作如下:
- 提出并实现了一种新的方法,用于改善现有LiDAR地图中的单眼相机姿态,该方法能够处理大规模场景中的重建任务。 框架中采用了多层体素化。
- 在激光雷达处理流程的每个步骤,包括动态对象去除、ROI滤波和3D线提取,多层体素图数据结构作为一个整体用于输入和输出,而不是初始点云,这简化并加快了算法。
- 我们仔细研究和分析了大量降级优化情况和故障案例,以便重新定位。
- 已经进行了各种实验来测试我们的方法,这些实验表明了我们系统的稳健性和准确性。
相关工作
略
系统概览
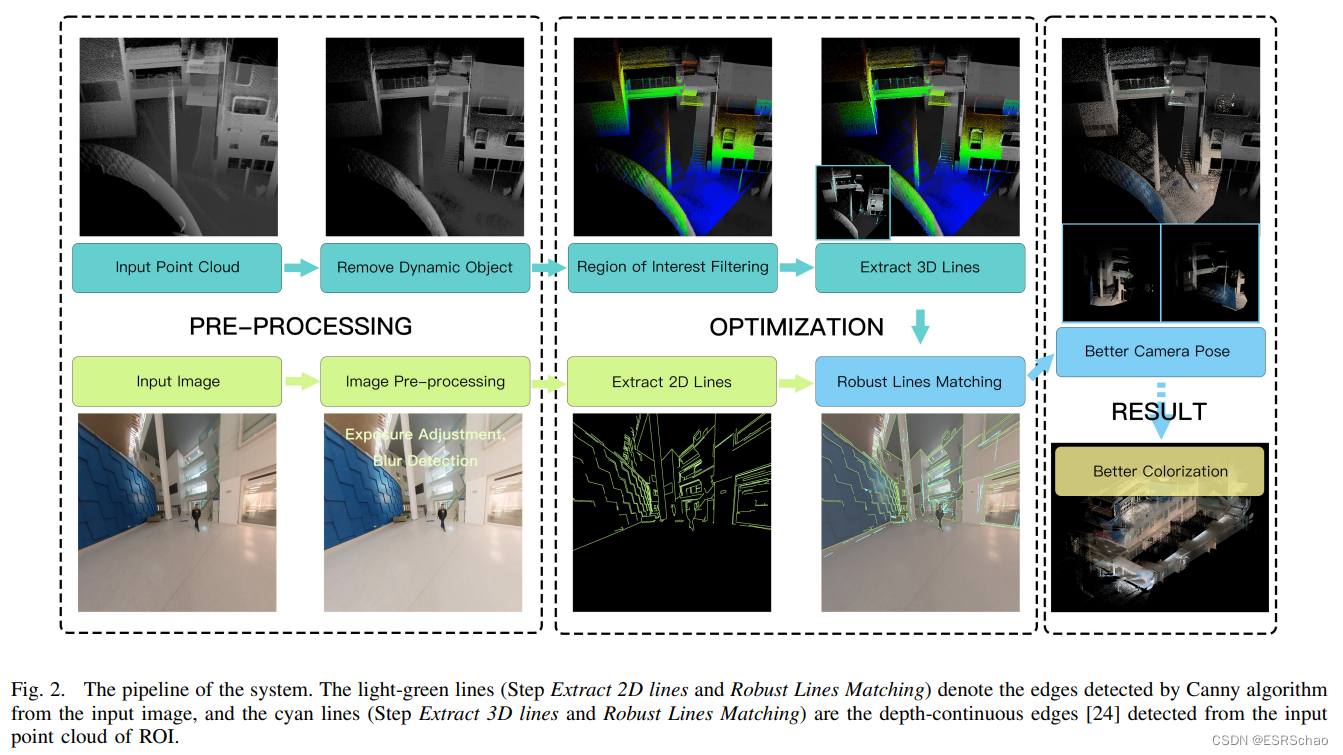
整个系统的Pipeline如图所示,图片部分的浅绿色线表示Canny算法从图片中检测到的边缘。三维部分的青色线表示从ROI的输入点云中检测到的深度连续边缘。
如图所示,框架包含图像和点云输入的两个主要处理流程。在这个流程之前实现了雷达量距(odometry)和映射算法以生成全局且正确的点云图。在这里雷达束调整也是增强点云结果的可选预处理步骤。如果使用LIP-based方法的话可以获得足够正确的激光雷达姿态,这有助于利用高频IMU数据获得平滑且几乎准确的运动轨迹。然后根据粗略的外部参数和时间同步,计算粗略的相机姿态。
对于图像输入,需要确定是否模糊,模糊图像将被直接丢弃,因为现有的图像去模糊算法并不能很好地工作。此外,为了设置统一的阈值来判断模糊情况,首先使用了一些数字图像处理方法,如直方图均衡。由于手机数据时图像参数不变,为了确保点云颜色的连续性,只使用原始图像进行着色测试而没有进行一些特殊的预处理。之后使用Canny算法检测2D边缘。
如果说想去处理的是一系列具有相应图像的相机姿势,对于全局的点云输入,首先会删除动态对象。然后根据相机视图选择点云ROI,通过相交平面检测将只提取深度连续边缘,因为点云中的深度不连续边缘对于匹配2D-3D线通常是不可靠的。
通过两个处理流程提取2D和3D线,使用匹配优化算法来获得3D点云中2D图像的最佳相机姿态参数。在这一步中作者还处理了一些退化的优化问题。ROI的光学图像纹理点云可以使用相机姿态参数来渲染。
在小规模的局部场景来使用该框架会跳过ROI的过滤部分,进而加快配准过程提供接近实时的性能。
技术细节
多层体素化
受到自适应体素化和OctoMap概念的启发。在我们的方法中,预处理过程中的动态对象去除、ROI滤波和3D线提取的工作使用类体素数据结构,因此文章中实现多层体素化过程以实现数据传输的多功能行和简单性。
文章中的体素图是由八叉树数据结构构建的。这里的root是3D点云的传统体素化的结果,这意味着首先通过默认和稍大的尺寸(例如2m)对点云进行体素化。
然后所有的root体素会被划分为八个子节点(子节点是父节点长度的一半)。直到体素达到适当的最小尺寸。只有所有叶子都存储相应的小点云数据以节省存储。体素图有助于加速点云的初步选择,也简化了初始点云数据。
移除动态对象
采用基于光线跟踪的方法来过滤动态对象。但与传统的基于射线追踪的方法不同,该算法将同时比较各种扫描,并应用一些额外的启发式方法。
基于光线跟踪的动态对象填充方法的主要思想是构建一个全局占据栅格(global occupancy grid),存储为点云的体素数据结构,并确定每个网格/体素是否会被击中或穿透。如果体素首先被激光雷达扫描击中但是之后被其他激光雷达扫描的光路看到,那么这个体素里面的点云会被移除。以前的大多数算法都采用了将命中数目或透视数存储到每个体素中的想法。因此会产生一些误判,静态体素会被错误地标记为动态体素。这是由同一扫描中具有接近角度的激光雷达点一起的(自相交情况)。为了处理这种情况,每个体素存储一组激光雷达扫描标识符。对于每个体素将遍历从激光雷达原点到它的光路上的所有体素(光线跟踪),如果这些体素中的一个包含相同的扫描标识符,则该体素将不被视为动态体素。
除了上述对体素占用情况的间接处理外,仍然存在大量的误判情况,主要包括由于激光雷达表面采样不均匀导致的两种情况。
一种是当入射角相对较大时,激光雷达扫描将穿过入射角较小的激光雷达点所在的体素。
另一种是在遮挡的情况下前景物体边缘的激光雷达将很容易被其他扫描通过。
因此,为每个激光雷达点设置安全的最大搜索距离可以避免这些误报。低于最大搜索距离的体素不会被过滤。
在这部分中首先建立体素图并设置合适的体素最小尺寸。然后使用体素图的最高层进行动态对象去除,这将修剪该图中的分支。
点云ROI
这部分主要概念就是从视点找到点云的可见部分,这是广义隐点去除(GHPR)算子(2015年较老论文)的应用。它主要包括两个步骤:点变换和凸包构造。
将应用一个原始镜像内核来加快点云可见性检测的处理。该内核可以写成:
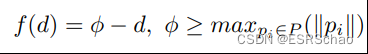
这里的 p i p_{i} pi是从连续曲面采样得到,而且 d = ∥ p i ∥ d={\|p_{i}\|} d=∥pi∥。
该方程表示在半径为 R = 1 2 ϕ R = \frac{1}2\phi R=21ϕ的球面镜像翻转。 C C C是球体的中心。半径变换可以表示为:
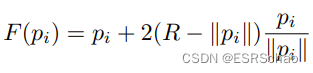
新的点集 P ^ ⊂ R \hat{P}\sub\mathbb{R} P^⊂R这些点位于 P ^ ∪ C \hat{P}\cup{C} P^∪C的凸包上同时确定了哪些点是可到达的或不可到达的,表示 P ^ ∗ ⊂ P ^ \hat{P}^{*}\sub\hat{P} P^∗⊂P^。然后找到相关的可达点子集 P ∗ ⊂ P P^{*}\sub{P} P∗⊂P,根据相机的内参最终确定可见点。
为了简化和加快工作流程,文章中在体素图中选择一些具有预设最大搜索距离(例如20m)的根节点,即要处理的点云的一部分。除了预选点之外,并没有考虑待处理点云中的每个点来过滤ROI,而是将体素图中更高层的节点/体素作为一个整体来考虑。在不失一般性的情况下,将所选根节点中的所有叶节点都考虑在内,之后将每个叶节点体素视为一个点来对点云进行下采样。这加速了凸包计算的过程,一些原本会被过滤掉的点也会被保留,但是由于相机姿势不准确,这些点应该被保留以供后续处理。正是因为这个原因,一些关于点云扩展的操作需要在实践中实现。首先,在过滤之前适当地加宽视点的视场(FOV)。然后每个可见体素会被遍历并且其相邻体素也被标记为可见,从而进一步扩展ROI过滤结果。
由于3D线特征的遮挡检测是困难的,因此3D线图不能直接使用3D线的ROI,一些方法会在不丢弃遮挡线的情况下收集所有的可见3D线,并且仅仅依赖于相机的固有参数和姿态信息。因此在使用大型点云时会有许多被遮挡的线。

如图所示,会提取出(c)这样的3D线,这大大增加了2D-3D对应匹配的难度。所以文章在提取3D特征线之前还会进行一次过滤。
提取3D线

如图所示,通常存在两种类型的特征边——深度连续边和深度不连续边。深度不连续边缘容易出现平面膨胀和点溢出,进而导致零值或多值投影问题。因此,直观的是深度不连续边缘对于图像信息的匹配是不可靠的。因此,为了获得深度连续的平面,我们将预先检测两个相交平面。
这个过程将遍历ROI范围内的所有根节点。对于包含在节点内的每个点 q i ∈ Q ( i = 1 , … , m ) q_{i}\in{Q}(i=1,\dots,m) qi∈Q(i=1,…,m),三维向量 q i q_i qi的协方差矩阵为:
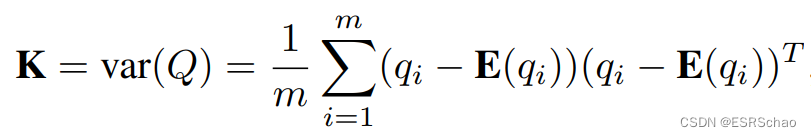
其中
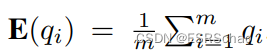
K K K的三个特征向量表示点云的主要正交方向,并且相应的三个特征值与这些方向上的散布成比例。如果最小特征值接近0,则节点/体素将被视为平面节点。
计算和比较协方差矩阵在这些点上的比率特征是确定体素情况的更合理的方法。
如果节点/体素不包含平面,则将搜索其子节点直到子节点是平面上的或者遍历了所有的叶节点。该方法比通过RANSAC拟合直接提取默认大小体素中的平面要好。因为RANSAC可能导致错误的提取。
对于每个平面节点,要扫描所有相邻的体素,如果相邻的体素也是平面上的,并且两个平面的法向量之间的角度在一个范围内,就可以构造相交边缘,该相交边缘是深度连续边缘。
线匹配
首先,对于之前提取的每个3D边缘,我们采样几个全局帧点 x i ∈ X ⊂ R 3 x_{i}\in{X}\sub{\mathbb{R^{3}}} xi∈X⊂R3.对于粗略的相机姿态 T c ∈ S E ( 3 ) T_c\in{SE(3)} Tc∈SE(3),3D-2D投影可以写成
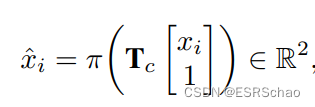
其中 π ( ⋅ ) \pi(\cdot) π(⋅)是实现相机模型并应用已知相机固有参数的函数。然后我们将在输入图像中提取的2D线中找到 x ^ i \hat{x}_i x^i的最近邻 y i ∈ Y y_{i}\in{Y} yi∈Y。
此外,该边的法向量n被认为是为了去除一些常见的误差匹配。(例如非平行但是闭合的线)。
通过提取2D和3D线,我们将2D-3D对应关系的 问题公式化为:
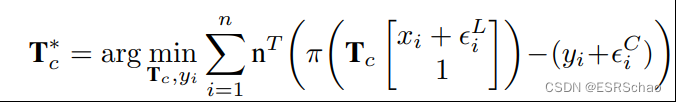
其中 ϵ i L \epsilon_{i}^{L} ϵiL和 ϵ i C \epsilon_{i}^{C} ϵiC是激光雷达和相机的噪声模型。通过最小化2D-3D对应的重投影距离即可获得更为精确的相机姿态。
这篇关于[上海科技大学论文]相机定位增强实现视觉LiDAR点云对齐(Camera Poses Augmentation with Large-scale LiDAR Maps)论文记录【适用大规模点云重建】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






