本文主要是介绍谣言检测论文精读——9.ACM2017-Multimodal Fusion with Recurrent Neural Networks for Rumor Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
我们观察到,除了文本之外,越来越多的用户正在使用图像和视频来发布新闻。 推文或微博通常由文本、图像和社交环境组成。 在本文中,我们提出了一种新颖的具有注意机制(att-RNN)的递归神经网络,以融合多模态特征以进行有效的谣言检测。 在这个端到端网络中,图像特征被结合到文本和社会背景的联合特征中,这些特征是通过 LSTM(长短期记忆)网络获得的,以产生可靠的融合分类。
Introduction
作者介绍了谣言检测相关工作,但是这些作品中使用的视觉特征也是手动制作的,它们基本上通过特征连接(早期融合)或平均结果(晚期融合)与现有特征融合。 一方面,现有作品中的手工制作特征仅限于学习复杂且可扩展的文本或视觉特征。 另一方面,现有的融合方法还很初步,可能无法有效地结合不同模式的好处。
基于这些不足之处,作者使用 RNN 来学习文本和社交上下文的联合表示。 然后将用预训练的深度 CNN 表示的图像视觉特征与它们融合。 我们在模型中使用注意力机制来捕捉视觉特征和联合文本/社会特征之间的关系。
论问主要贡献如下:
- 作者提出的是在社交网络上结合多模态的神经网络来检测
- 作业提出了一种具有注意力机制的创新RNN,用于有效的多模态融合,并利用注意力机制进行特征对齐。
RELATED WORK
作者介绍了基于文本的,基于上下文的,基于视觉的谣言检测,并且在这些工作中,卷积神经网络 (CNN) 在图像表示方面表现出了强大的能力 ,而循环神经网络 (RNN) 最近在句子表示中得到广泛应用,受到这些成功的启发,最近很多基于多模态的检测任务,作者考虑到多模态和神经网络融合,提出了该模型。
Model

模型概述:
我们将推文实例 I = {T, S', V} 定义为表示三种不同内容模式的元组:文本内容 T、社交上下文 S 和视觉内容 V。所提出的模型从这些模式中获取特征( Rt、Rs 和 Rv),旨在学习一个可靠的表示 Ri 作为给定推文 I 的 T、S 和 V 的聚合。首先,我们将文本和社交上下文用 RNN 融合,并为这两个模式生成一个联合表示 Rts 。 对于视觉特征 Rv,它是通过深度 CNN 获得的。 我们在每个时间步使用来自 RNN 输出的注意力来进一步细化 Rv。 在最后一步中,将 Rts 和注意力聚合的 R'v 连接起来作为最终的多模态表示 Rj,然后按照二元分类器来区分推文实例是真还是假。
LSTM
这一部分就不再这里解释了
文本和社会背景的联合表示
文本内容是它包含的单词的顺序列表:T = {T1.T2, ...,Tn }(n 是文本中的单词数)。 文本中的每个词 Ti ∈T 都表示为一个词嵌入向量。 每个单词的嵌入向量是通过在给定数据集上进行无监督预训练的深度网络获得的。
微博上生成的上下文,如标签主题、提及和转发,以及一些文本语义特征,如情感极性,被用来形成初始社交上下文表示 Rs 。 社交上下文特征 Rs 通过全连接层(图 3 中的“soc-fc”)转换为具有与词嵌入向量相同维度的表示 Rs1
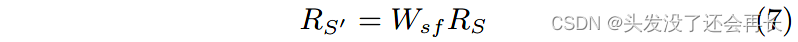
其中 W s f 是全连接层中用于维度变换的权重。
在每个时间步,LSTM将RTiS = [ RTi ; RS′′] 作为输入,即第i个单词的嵌入RTi 和转换后的社交上下文特征RS′′ 的拼接。对LSTM输出的每个单词的表示取平均,就得到文本和社交上下文的联合表示RTS。
图像的视觉表示
视觉子网络(图 2 中的底部分支)将推文图像作为输入,并生成视觉神经元作为图像的特征。 它的前层具有与 VGG-19 网络 [27] 相同的结构。 我们在第二层之上添加了两个 512 神经元全连接层(图 2 中的“vis-fcl”和“vis-fc2”),到 VGG-19 网络的最后一层,为每张图像生成一个 512 个神经元的视觉表示 Ry,[v1 ,v2 ,…,v512 ] T。
视觉子网络可以首先使用辅助数据集进行微调。 然而,在与 LSTM 子网络的联合训练期间,仅更新最后两个全连接层的参数以进行更有效的训练。
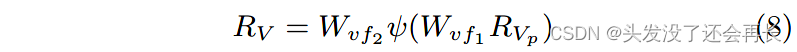
直接利用模型中的视觉和联合社交文本表示的一大挑战是,一种表示可能会压倒另一种表示,这导致对这种模式的表现有偏差。 为了最大化多模态特征的好处,我们应该共同学习不同模态的对齐。 在接下来的部分中,我们将介绍一种注意力机制来根据每个时间步的 RNN 输出调整视觉表示,并同时产生聚合的视觉神经元。
Attention for Visual Representation
在谣言检测的设置下,我们假设文本内容中的单词可能与图像中的一些语义概念相关联 . 我们的目标是自动找到这种连接。 特别是,与单词具有相似语义含义的视觉神经元应该被分配更多的权重。
我们提出的视觉神经元注意机制对不同神经元对不同单词的贡献进行加权。 为了实现这个目标,我们以 LSTM 在每个时间步的输出隐藏状态 hm 作为指导。 hm 连接成具有非线性 ReLU 函数的全连接层和具有 softmax 函数的全连接层,得到注意力向量 Am∈R^512 ,其维度与视觉神经元 Ry 相同。
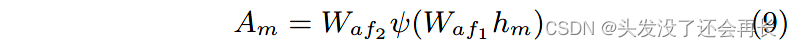
其中 A m (i) 是第 i 个视觉神经元的注意力值。 遵循这种注意力机制。
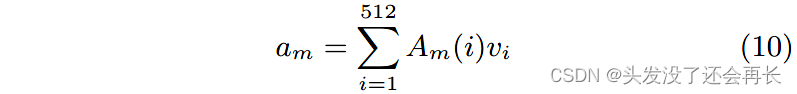
LSTM 在文本和社会上下文的联合特征学习中生成的注意力向量 Am 可以决定应该更加重视哪些视觉神经元。 最终的视觉表示是每个单词的一组相似度值:Rv' = [a1, a2, ..., a n ](n 是给定文本中的单词数)。
模型学习
到目前为止,我们已经获得了文本和社交上下文的联合表示 Rts 和注意力聚合的视觉表示 Rv' , 这两个特征连接起来形成给定推文的多模态表示 RI =[RTS; RV′ ],即 在计算谣言检测目标的损失之前,输入到 softmax 层。 我们使用交叉熵来定义第 m 条推文的损失如下:
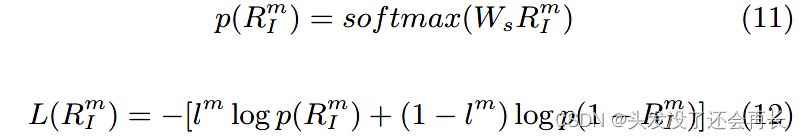
其中 RIm 是第 m 个推文实例的多模态表示,Ws 是线性模型的 softmax 层中的参数,lm 表示第 m 个实例的真实标签,1 代表虚假谣言推文,0 代表真实的。
总之,我们提出的多模态 att-RNN 输入训练数据 I = {T, S, V},其内容来自三种不同的模态:文本、社会背景和图像。 它为每个实例输出预测标签,以将其指示为谣言或非谣言。 整个模型使用批量随机梯度下降进行端到端训练,以最小化损失函数:
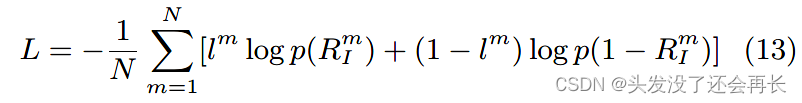
Datasets

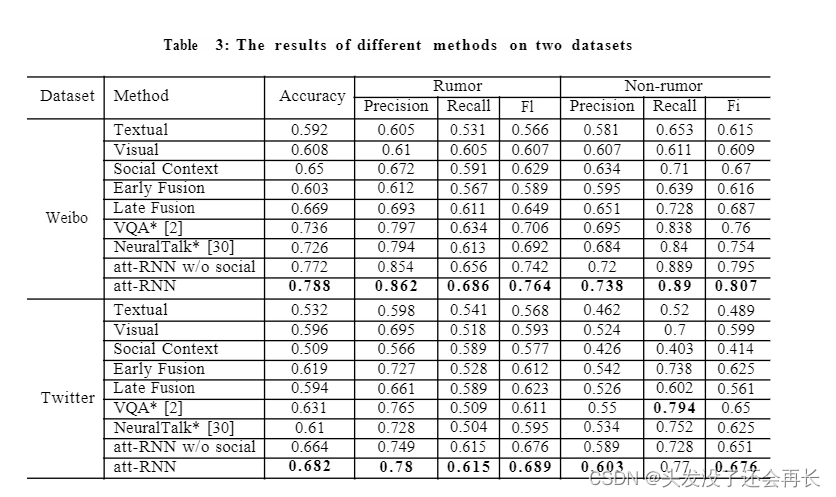
Results
Conclusion
作者提出了一种新的多模态模型,结合了文本,视觉和上下文,并且在融合的时候为了最大化多模态特征的好处,共同学习不同模态的对齐,采用了注意力机制。
其中文本和上下文是采用基于LSTM的RNN,视觉是采用加了两个全连接层的CNN,然后将两种特征表示融合,在融合过程中,利用LSTM在每个时间步的输出作为neuron-level注意力,以调节视觉特征。
这篇关于谣言检测论文精读——9.ACM2017-Multimodal Fusion with Recurrent Neural Networks for Rumor Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!