马尔可夫专题

卡尔曼滤波实现一阶马尔可夫形式的滤波|价格滤波|MATLAB代码|无需下载,复制后即可运行
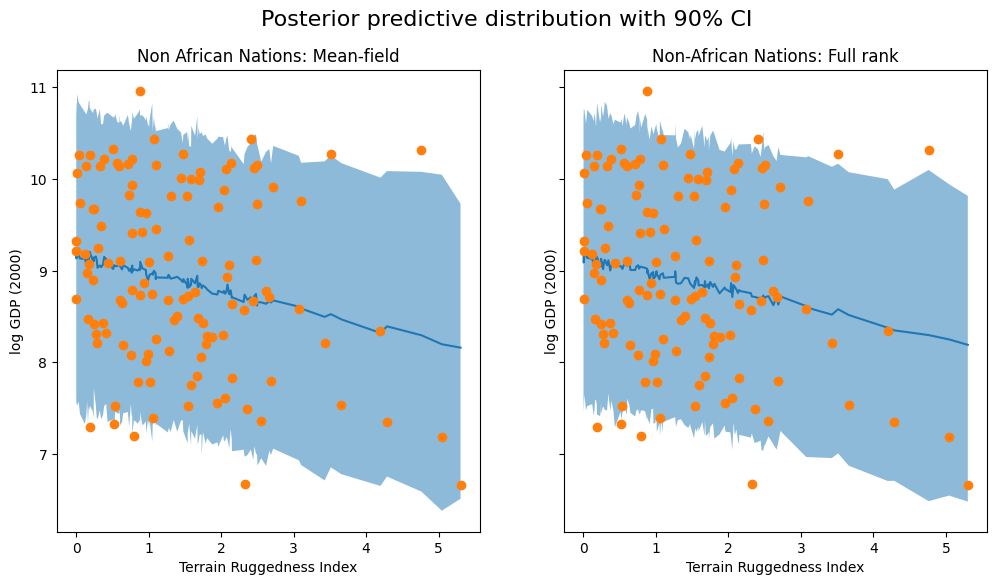
一节马尔可夫 一阶马尔可夫噪声是一种具有马尔可夫性质的随机过程。在这种噪声中,当前时刻的状态只与前一时刻的状态有关,与更早的状态无关。 一阶马尔可夫噪声可以用一个状态转移矩阵表示,矩阵的每个元素表示从一个状态转移到另一个状态的概率。 滤波模型 状态量的迭代模型如下: 观测量为X的第一维,所以观测方程也就是取X的第一维。 运行结果 应用背景为价格滤波,所以对比X真值和滤波值的第一维

马尔可夫决策过程(Markov decision process,MDP)
文章目录 马尔可夫决策过程(MDP)在机器学习中应用在机器学习中的引用示例引用: 实例场景:机器人导航MDP的定义:引用示例: 在此基础上更具体的描述,并给出每一步的推断计算过程场景描述:3x3网格中的机器人导航MDP的定义强化学习算法:Q-Learning具体实例与推断计算过程回合1( E p i s o d e 1 Episode 1 Episode1)回合2( E p i s
Pyro简介 贝叶斯神经网络bnn , 隐马尔可夫模型 人工智能python python 概率分布程序包的使用教程
Pyro简介 镜像GitCode - 全球开发者的开源社区,开源代码托管平台 gitcode.com/gh_mirrors/py/pyro/blob/dev/tutorial/source/bayesian_regression_ii.ipynb Introduction to Pyro — Pyro Tutorials 1.9.1 documentation pyro.ai/examples
机器学习课程复习——隐马尔可夫
不考计算题 Q:概率图有几种结构? 条件独立性的公式? 顺序结构发散结构汇总结构 Q:隐马尔可夫模型理解? 概念 集合:状态集合、观测集合 序列:状态序列、观测序列
什么是隐马尔可夫模型?
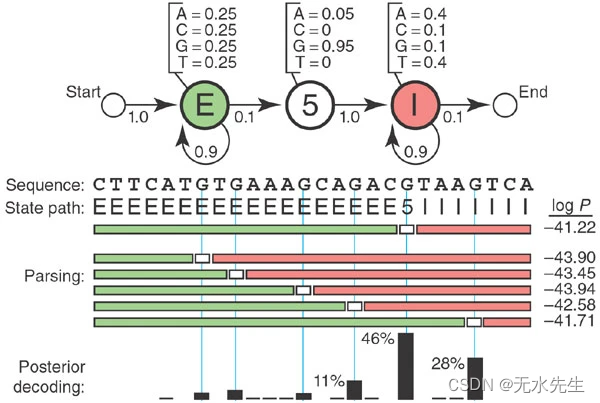
文章目录 一、说明二、玩具HMM:5′拼接位点识别三、那么,隐藏了什么?四、查找最佳状态路径五、超越最佳得分对齐六、制作更逼真的模型七、收获 关键词:hidden markov model 一、说明 被称为隐马尔可夫模型的统计模型是计算生物学中反复出现的主题。什么是隐马尔可夫模型,为什么它们对这么多不同的问题如此有用? 通常,生物序列分析只是在每个残留物上贴上正确的标签。在

深入浅出談 隐马尔可夫的概念(1/ 2)
文章目录 一、说明二、Markov Chain三、Introduction四、State Sequence五、Comment六、介绍隐藏式马可夫法则。七、隐藏马尔可夫Introduction八、结论 一、说明 在许多机器学习的章节中,常常遇见 HMM ,往往看到它的数学式子后,就当没看到似的跳过去了,其实它的基础理论并不难,尤其是 Markov Chain 在高中数学课本就已经出

【数学】【机器学习】什么是隐马尔可夫模型 (HMM)?
文章目录 隐马尔可夫模型 (HMM)背景公式示例题目详细讲解Python代码求解实际生活中的例子 什么是隐变量背景隐含变量的意义举例说明HMM的三个基本问题示例 隐马尔可夫模型 (HMM) 背景 隐马尔可夫模型(Hidden Markov Model, HMM)是一种统计模型,用于描述含有隐含变量的时间序列数据。它在自然语言处理、语音识别、生物信息学等领域有广泛应用。HMM
【TensorFlow深度学习】使用TensorFlow构建马尔可夫决策过程模型
使用TensorFlow构建马尔可夫决策过程模型 使用TensorFlow构建马尔可夫决策过程模型:决策分析的深度实践一、马尔可夫决策过程简介二、TensorFlow准备三、定义MDP模型参数四、构建状态值函数模型五、迭代更新值函数六、策略提取与决策结语 使用TensorFlow构建马尔可夫决策过程模型:决策分析的深度实践 马尔可夫决策过程(Markov Decision

马尔可夫和比奈梅-切比雪夫不等式
目录 一、说明 二、自然界的极限性 三、马尔可夫不等式 3.1 最早提出 3.2 马尔可夫不等式的证明 四、 Bienaymé–Chebyshev 不等式 4.1 简要回顾Bienaymé–Chebyshev 不等式的历史 4.2 Bienaymé — Chebyshev 不等式的证明 五、弱大数定律(及其证明) 5.1 定律陈述 5.2 弱大数定律的证明 一、说明

强化学习——马尔可夫奖励过程的理解
目录 一、马尔可夫奖励过程1.回报2.价值函数 参考文献 一、马尔可夫奖励过程 在马尔可夫过程的基础上加入奖励函数 r r r 和折扣因子 γ \gamma γ,就可以得到马尔可夫奖励过程(Markov reward process)。一个马尔可夫奖励过程由 < S , P , r , γ > <S,P,r,\gamma > <S,P,r,γ> 构成,各个组成元素的含

(done) 什么是马尔可夫链?Markov Chain
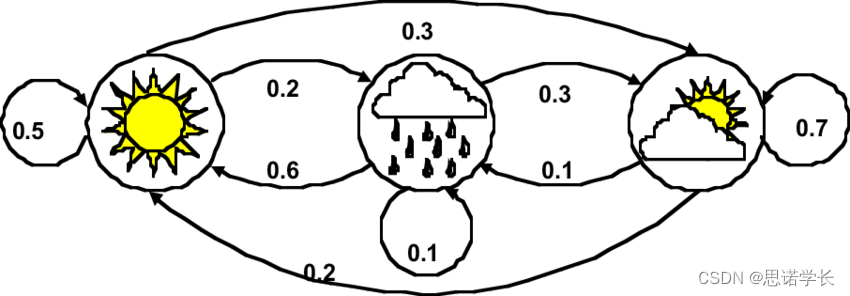
参考视频:https://www.bilibili.com/video/BV1ko4y1P7Zv/?spm_id_from=333.337.search-card.all.click&vd_source=7a1a0bc74158c6993c7355c5490fc600 如下图所示,马尔可夫链条实际上就是 “状态机”,只不过状态机里不同状态之间的边上是 “概率” 马尔可夫链有一个非常好的性质,
(undone) 什么是马尔可夫链?Markov Chain
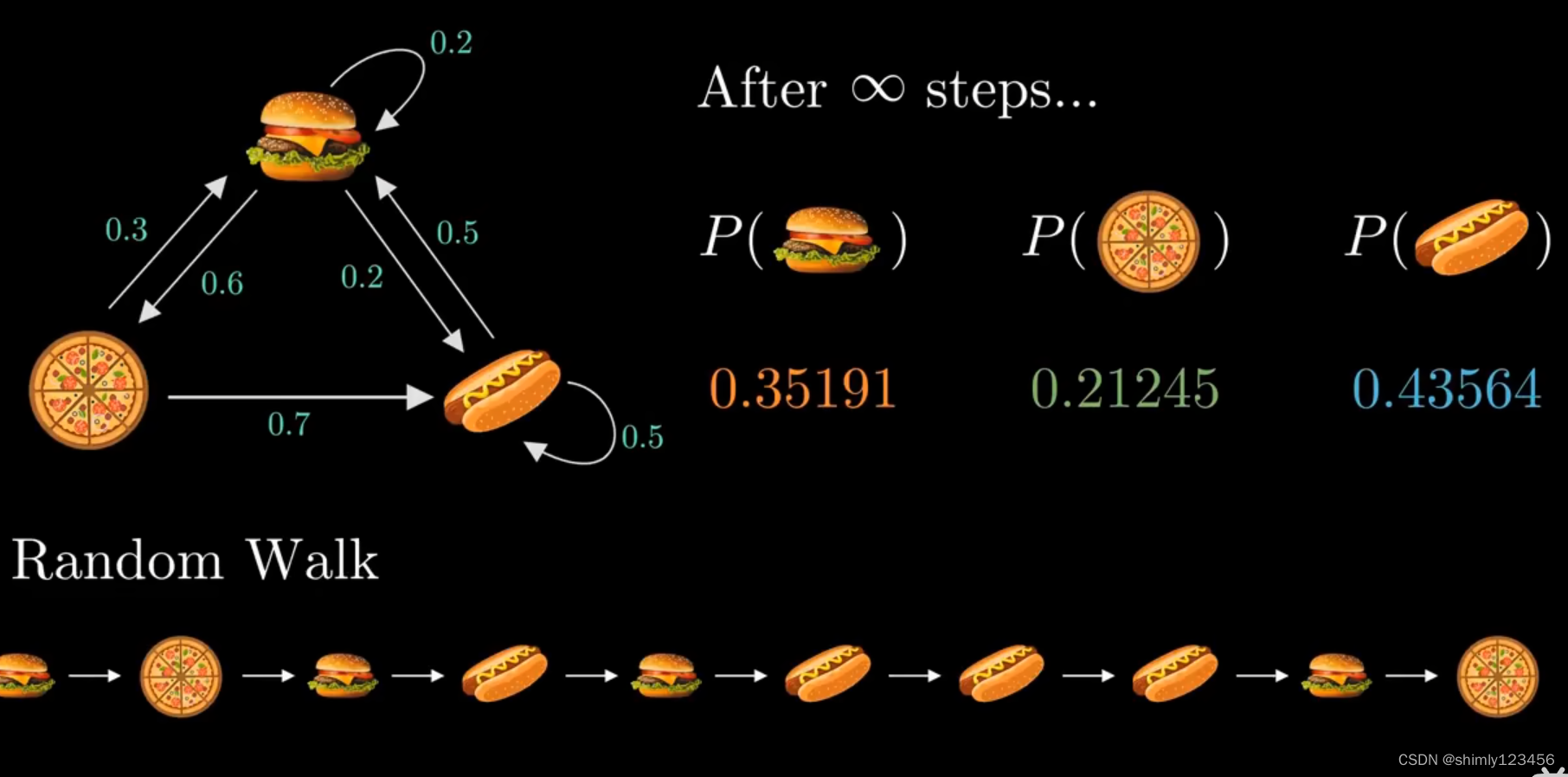
参考视频:https://www.bilibili.com/video/BV1ko4y1P7Zv/?spm_id_from=333.337.search-card.all.click&vd_source=7a1a0bc74158c6993c7355c5490fc600 如下图所示,马尔可夫链条实际上就是 “状态机”,只不过状态机里不同状态之间的边上是 “概率” 马尔可夫链有一个非常好的性质,

转自MIT牛人林达华的 “图˙谱˙马尔可夫过程˙聚类结构 ”————经典、透彻
题目中所说到的四个词语,都是MachineLearning以及相关领域中热门的研究课题。表面看属于不同的topic,实际上则是看待同一个问题的不同角度。不少文章论述了它们之间的一些联系,让大家看到了这个世界的奇妙。 从图说起 这里面,最简单的一个概念就是“图”(Graph),它用于表示事物之间的相互联系。每个图有一批节点(Node),每个节点表示一个对象,通过一些边(Edge)把这些点连在
马尔可夫链 学习笔记
马尔可夫链是一种数学模型,用于描述具有马尔可夫性质的随机过程——当前状态的概率只依赖于前一个状态。下面是一个简单的例子,使用三个数据(状态)来描述一个简单的马尔可夫链: 假设有三个状态:晴天(Sunny)、阴天(Cloudy)、雨天(Rainy)。每天的天气状态只依赖于前一天的天气状态。 这里是可能的状态转换概率: 从晴天到阴天的概率是0.4,到雨天的概率是0.1,保持晴天的概率是0.5

马尔可夫聚类算法(MCL)
1.基础 1.1Random Walks 在图中,通过Random Walks处理,可以找到数据在哪里聚集,或者聚簇在哪。 图中的Random Walks是使用马尔可夫链计算求出。 1.2马尔可夫链(Markov Chain) 先看一个简单的例子: 第一步,结点1的Random Walker有33%的概率到达结点2、3和4,且有0%的概率到达结点5、6和7。 对于结点2,

隐马尔可夫模型(HMM),了解一下?
隐马尔可夫模型(HMM) 隐马尔可夫模型(HMM) 1. 隐马尔可夫模型基本概念 1.1 定义1.2 观测序列生成过程1.3 3个基本问题 2. 概率计算方法 2.1 直接计算法2.2 前向算法2.3 后向算法 3. 学习算法 3.1 监督学习方法3.2 非监督学习方法 EM算法 Baum-Welch算法 4. 预测算法 4.1 近似算法4.2 维特比算法 1. 隐马尔可

马尔可夫模型(Markov models)
Markov假设有一系列的事件、状态或其他事物,后一事件的发生取决于前一事件。 这样我们可以构造一个Markov链,并画图。 我们还可以将每一个状态之间的转换可能性数值列出成为transition matrix 所以马尔可夫链经过n步之后的状态可以由transition matrix和一个初始状态的列向量表示 如 Markov链式序列分析的理想工具,可以在不同的层次上应用。 例如
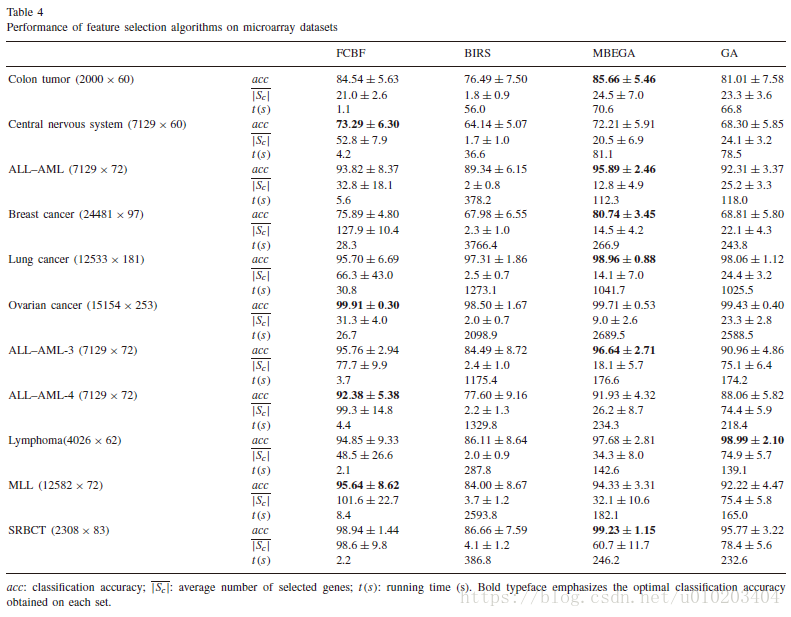
马尔可夫毯式遗传算法在基因选择中的应用
#引用 ##LaTex @article{ZHU20073236, title = “Markov blanket-embedded genetic algorithm for gene selection”, journal = “Pattern Recognition”, volume = “40”, number = “11”, pages = “3236 - 3248”, year =

马尔可夫模型及隐马尔可夫模型(HMM)
马尔可夫模型 马尔可夫模型是由Andrei A. Markov于1913年提出的 ∙ ∙ 设 S S是一个由有限个状态组成的集合 S={1,2,3,…,n−1,n} S={1,2,3,…,n−1,n} 随机序列 X X 在 t t时刻所处的状态为 qt qt,其中 qt∈S qt∈S,若有: P(qt=j|qt−1=i,qt−2=k,⋯)=P(qt=j|qt

概率图模型--贝叶斯网络与马尔可夫随机场
概率图模型在机器学习中扮演着重要的角色,特别是贝叶斯网络和马尔可夫随机场。让我简要介绍它们在机器学习中的应用: 贝叶斯网络: 概述:贝叶斯网络是一种用图形表示随机变量之间条件依赖关系的概率图模型。应用:在机器学习中,贝叶斯网络常用于建模不同变量之间的依赖关系,并进行推理和预测。案例:在医学诊断中,贝叶斯网络可以用来建立疾病和症状之间的关系,帮助医生进行诊断和治疗决策。在自然语言处理中,它可以用

概率图模型在机器学习中的应用:贝叶斯网络与马尔可夫随机场
🧑 作者简介:阿里巴巴嵌入式技术专家,深耕嵌入式+人工智能领域,具备多年的嵌入式硬件产品研发管理经验。 📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟,欢迎关注。提供嵌入式方向的学习指导、简历面试辅导、技术架构设计优化、开发外包等服务,有需要可私信联系。 文章目录 1. 概述2. 概率图模型的基础3. 贝叶斯网络的深度解析3.1 贝叶斯网络的核心概念3.2

隐马尔可夫模型(HMM)硬啃西瓜书
隐马尔可夫模型(HMM) 好吧隐马尔可夫模型出现的次数实在有点多;今天来讲讲吧 先来四个概念: 可见状态链 观测结果隐含状态链 产生结果的实体类型转换概率 相邻实体之间转换的概率输出概率 实体输出结果的概率 两个基本假设: 1) 齐次马尔科夫链假设。即任意时刻的隐藏状态只依赖于它前一个隐藏状态。 2) 观测独立性假设;实体输出结果的概率完全独立 本来说的是参考几篇文章来写,t
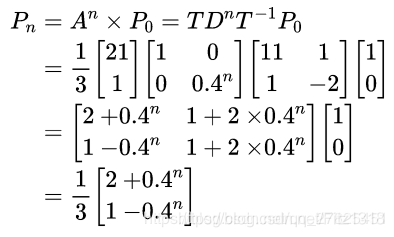
算法——马尔可夫与隐马尔可夫模型
HMM(Hidden Markov Model)是一种统计模型,用来描述一个隐含未知量的马尔可夫过程(马尔可夫过程是一类随机过程,它的原始模型是马尔科夫链),它是结构最简单的动态贝叶斯网,是一种著名的有向图模型,主要用于时序数据建模。在语音识别、自然语言处理等领域有广泛应用 Background requirements: 1、基础的概率学知识 2、动态规划是加分项 3、有实际运用Ma
隐马尔可夫简介(转)
同前面一样,因为编辑器不支持latex方式的数学公式输入,所以我就试图用文字的方式来简要描述一下隐Markov模型(Hidden Markov Model,HMM)。所有这类模型都有一个前提假设,就是下一个时刻的状态只与当前时刻相关。满足这种特性的过程就是Markov过程。可能有人会立刻联想到物理学中的绝对论,Laplace当年豪迈地宣称,只要给定某个时刻宇宙的全部状态,那么理论上我们可以计