近邻专题

读懂《机器学习实战》代码—K-近邻算法
一,K近邻算法概念 K近邻算法即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。KNN 算法是一种 lazy-learning 算法,分类器不需要使用训练集进行训练,训练时间复杂度为0。KNN 分类的计算复杂度和训练集中的文档数目成正比,也就是说,如果训练集中文档总数为 n,

k近邻(kNN)算法的Python实现(基于欧氏距离)
k近邻算法是机器学习中原理最简单的算法之一,其思想为:给定测试样本,计算出距离其最近的k个训练样本,将这k个样本中出现类别最多的标记作为该测试样本的预测标记。 k近邻算法虽然原理简单,但是其泛华错误率却不超过贝叶斯最有分类器错误率的两倍。所以实际应用中,k近邻算法是一个“性价比”很高的分类工具。 基于欧式距离,用Python3.5实现kNN算法: 主程序: from numpy impor

统计学习与方法实战——K近邻算法
K近邻算法 K近邻算法备注k近邻模型算法距离度量 k k k值选择分类决策规则构造KDTree k k k近邻查找范围查询 代码结构总结 K近邻算法 备注 kNN是一种基本分类与回归方法. 多数表决规则等价于0-1损失函数下的经验风险最小化,支持多分类, 有别于前面的感知机算法kNN的k和KDTree的k含义不同KDTree是一种存储k维空间数据的树结构建立空间索引的方法

【机器学习】K近邻(K-Nearest Neighbors,简称KNN)的基本概念以及消极方法和积极方法的区别
引言 K近邻(K-Nearest Neighbors,简称KNN)算法是一种基础的机器学习方法,属于监督学习范畴 文章目录 引言一、K近邻(K-Nearest Neighbors,简称KNN)1.1 原理详述1.1.1 距离度量1.1.2 选择k值1.1.3 投票机制 1.2 实现步骤1.3 参数选择1.4 应用场景1.5 优缺点1.5.1 优点1.5.2 缺点 1.6 k-近邻代

4.sklearn-K近邻算法、模型选择与调优
文章目录 环境配置(必看)头文件引用1.sklearn转换器和估计器1.1 转换器 - 特征工程的父类1.2 估计器(sklearn机器学习算法的实现) 2.K-近邻算法2.1 简介:2.2 K-近邻算法API2.3 K-近邻算法代码2.4 运行结果2.5 K-近邻算法优缺点 3.模型选择与调优3.1 交叉验证(cross validation)3.2 网格搜索(Grid Search)3
机器学习实战(k-近邻算法)
给定训练数据样本和标签,对于某测试的一个样本数据,选择距离其最近的k个训练样本,这k个训练样本中所属类别最多的类即为该测试样本的预测标签。简称kNN。通常k是不大于20的整数,这里的距离一般是欧式距离。 K最近邻(k-Nearest Neighbour,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间
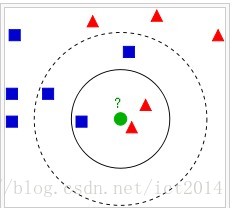
k近邻分类算法(kNN)
注明:部分内容来自维基百科 In pattern recognition, the k-Nearest Neighbors algorithm (ork-NN for short) is anon-parametric method used forclassification andregression. In both cases, the input consists of the k c
【机器学习】5. K近邻(KNN)
K近邻(KNN) 1. K-Nearest Neighbour1.1 特点:计算复杂1.2 K的设置1.3 加权近邻 Weighted nearest neighbor1.4 决策边界 Decision boundaryVoronoi region 2. KNN总结 1. K-Nearest Neighbour K: 超参数(hyperparameter) 定义一种距离,参考



【机器学习】第3章 K-近邻算法
一、概念 1.K-近邻算法:也叫KNN 分类 算法,其中的N是 邻近邻居NearestNeighbor的首字母。 (1)其中K是特征值,就是选择离某个预测的值(例如预测的是苹果,就找个苹果)最近的几个值,邻近的意思也很简单,就是距离上最近,距离测算主要分两种。 实际情况就是点的x,y这些值就是这个点的特征,一样的事物最后在坐标轴上位置离得很近,而你把预测值放进去,它离哪个近,可不就是哪个玩意

深入第一个机器学习算法: K-近邻算法(K-Nearest Neighbors)
本篇博文主要涉及到以下内容: K-近邻分类算法从文本文件中解析和导入数据使用Matplotlib创建扩散图归一化数值 K-近邻算法 功能: 非常有效且易于掌握。 学习K-近邻算法的思路: 首先,探讨k-近邻算法的基本理论,以及如何使用距离测量的方法分类物品。其次,使用Python 从文本文件中导入并解析数据。再次,讨论当存在多种数据源时,如何避免计算距离时可能碰到的一些常见的错误。最后,
机器学习算法 —— K近邻(KNN回归)
🌟欢迎来到 我的博客 —— 探索技术的无限可能! 🌟博客的简介(文章目录) 目录 实战KNN分类KNN回归模拟数据集 —— KNN回归库函数导入数据导入&分析模型训练&预测可视化模型分析 总结 实战 KNN分类 接上文:机器学习算法 —— K近邻(KNN分类) KNN回归 模拟数据集 —— KNN回归 库函数导入 import numpy as np
【机器学习300问】115、对比K近邻(KNN)分类算法与逻辑回归分类算法的差异与特性?
在学习了K近邻(KNN)和逻辑回归(Logistic Regression)这两种分类算法后,对它们进行总结和对比很有必要。尽管两者都能有效地执行分类任务,但它们在原理、应用场景和性能特点上存在着显著的差异。本文就是想详细阐述这两种算法之间的主要区别和特性,以帮助大家在面临不同数据集时能够更准确地选择适合的算法进行分类。 一、K邻近分类算法的特点和机制 (1)直观简单

推荐系统三十六式学习笔记:原理篇.近邻推荐09|协同过滤中的相似度计算方法有哪些?
目录 相似度的本质相似度的计算方法:1、欧式距离2、余弦相似度3、皮尔逊相关度4 、杰卡德(Jaccard)相似度 总结 相似度的本质 推荐系统中,推荐算法分为两个门派,一个是机器学习派,一个是相似度门派。机器学习派是后起之秀,而相似度门派则是泰山北斗。 近邻推荐,近邻并不一定只是在三维空间下的地理位置的近邻,也可以是高维空间的近邻。 近邻推荐的核心就是相似度计算方法的选择,由

机器学习--从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
引言 最近在面试中,除了基础 & 算法 & 项目之外,经常被问到或被要求介绍和描述下自己所知道的几种分类或聚类算法(当然,这完全不代表你将来的面试中会遇到此类问题,只是因为我的简历上写了句:熟悉常见的聚类 & 分类算法而已),而我向来恨对一个东西只知其皮毛而不得深入,故写一个有关数据挖掘十大算法的系列文章以作为自己备试之用,甚至以备将来常常回顾思考。行文杂乱,但侥幸若能对读者起到一

基于JavaScript 实现近邻算法以及优化方案
前言 近邻算法(K-Nearest Neighbors,简称 KNN)是一种简单的、广泛使用的分类和回归算法。它的基本思想是:给定一个待分类的样本,找到这个样本在特征空间中距离最近的 k 个样本,这 k 个样本的多数类别作为待分类样本的类别。 本教程文章将详细讲解如何使用 JavaScript 实现一个简单的 KNN 算法,我们会从理论出发,逐步从零开始编写代码。 理论基础 距离度量 K
C++的近邻算法详解及应用
近邻算法,也被称为最近邻算法或k-近邻算法(k-NN),是一种基本的分类和回归方法。它基于实例进行学习,无需进行模型训练,而是直接通过计算待分类样本与已知类别样本之间的距离来确定其所属类别。在C++中,我们可以通过编写特定的函数或利用现有的库来实现近邻算法。 一、近邻算法基本原理 近邻算法的基本思想是:存在一个样本数据集合,也称作训练样本集,并且

跟我一起学scikit-learn15:K-近邻算法
KNN(K-Nearest Neighbor,K-近邻算法)算法是一种有监督的机器学习算法,可以解决分类问题,也可以解决回归问题。 1.KNN算法原理 K-近邻算法的核心思想是未标记样本的类别,由距离其最近的K个邻居投票来决定。 假设,我们有一个已经标记的数据集,即已经知道了数据集中每个样本所属的类别。此时,有一个未标记的数据样本,我们的任务是预测出这个数据样本所属的类别。K-近邻算法的原理

鸢尾花分类和手写数字识别(K近邻)
鸢尾花分类 from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitimport pandas as pdimport mglearn# 加载鸢尾花数据集iris = load_iris()X_train, X_test, y_train, y_test = tr

【机器学习】k-近邻算法应用之手写数字识别
上篇文章简要介绍了k-近邻算法的算法原理以及一个简单的例子,今天再向大家介绍一个简单的应用,因为使用的原理大体差不多,就没有没有过多的解释。 为了具有说明性,把手写数字的图像转换为txt文件,如下图所示(三个图分别为5、6、8): 要使用k-近邻算法,需要有足够的样本数据和测试数据,我放到了两个文件夹里(trainingDigits和testDigits),可以在这里(http://pan.b
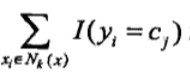
统计学习方法笔记-K近邻法
k近邻法是一种基本分类与回归方法,这儿只讨论分类问题中的k近邻法。k近邻法输入为实例的特征向量,输出为实例的类别,可以取多类。 K近邻算法 简介: 给定一个训练数据集,对新输入的实例,在训练数据集中找到与其最近邻的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类。 算法: 1、根据给定的距离度量,在训练集中找出实例x最邻近的k个实例,涵盖这k个实例的

数据挖掘十大算法--K近邻算法
k-近邻算法是基于实例的学习方法中最基本的,先介绍基于实例学习的相关概念。 一、基于实例的学习。 1、已知一系列的训练样例,很多学习方法为目标函数建立起明确的一般化描述;但与此不同,基于实例的学习方法只是简单地把训练样例存储起来。 从这些实例中泛化的工作被推迟到必须分类新的实例时。每当学习器遇到一个新的查询实例,它分析这个新实例与以前存储的实例的关系,并据此把一个目标函数值赋给新实例。 2
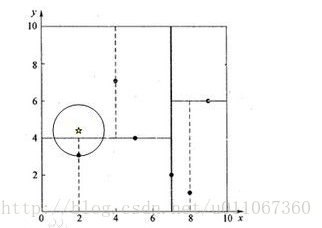
K近邻算法基础:KD树的操作
Kd-树概念 Kd-树 其实是K-dimension tree的缩写,是对数据点在k维空间中划分的一种数据结构。其实,Kd-树是一种平衡二叉树。 举一示例: 假设有六个二维数据点 = {(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)},数据点位于二维空间中。为了能有效的找到最近邻,Kd-树采用分而治之的思想,即将整个空间划分为几个小部分。六个二维数据点生成的Kd-树的
机器学习笔记——K近邻算法、手写数字识别
KNN算法 “物以类聚,人以群分”相似的数据往往拥有相同的类别 其大概原理就是一个样本归到哪一类,当前样本需要归到频次最高的哪个类去 也就是说有一个待分类的样本,然后跟他周围的k个样本来看,k中哪一个类最多,待分类的样本就是哪一个。 那就以手写数字识别为例吧 import matplotlib.pyplot as pltimport numpy as npimport os#%%# 读