推断专题

【python因果推断库11】工具变量回归与使用 pymc 验证工具变量4
目录 Wald 估计与简单控制回归的比较 CausalPy 和 多变量模型 感兴趣的系数 复杂化工具变量公式 Wald 估计与简单控制回归的比较 但现在我们可以将这个估计与仅包含教育作为控制变量的简单回归进行比较。 naive_reg_model, idata_reg = make_reg_model(covariate_df.assign(education=df[

CNN-LSTM模型中应用贝叶斯推断进行时间序列预测
这篇论文的标题是《在混合CNN-LSTM模型中应用贝叶斯推断进行时间序列预测》,作者是Thi-Lich Nghiem, Viet-Duc Le, Thi-Lan Le, Pierre Maréchal, Daniel Delahaye, Andrija Vidosavljevic。论文发表在2022年10月于越南富国岛举行的国际多媒体分析与模式识别会议(MAPR)上。 摘要部分提到,卷积

C++ 模板进阶知识——类型推断
目录 C++ 模板进阶知识——类型推断1. 如何查看类型推断结果使用Boost库步骤注意 2. 理解函数模板类型推断2.1 指针或引用类型2.1.1 忽略引用2.1.2 保持const属性2.1.3 处理指针类型2.1.4 结果说明 2.2 万能引用类型2.3 传值方式2.3.1 函数模板和参数推导结论 2.3.2 指针的情况在`myfunc()`中测试指针行为 2.4 传值方式的引申—s

【python因果推断库7】使用 pymc 模型的工具变量建模 (IV)2
目录 与普通最小二乘法 (OLS) 的比较 应用理论:政治制度与GDP 拟合模型:贝叶斯方法 多变量结果和相关性度量 结论 与普通最小二乘法 (OLS) 的比较 simple_ols_reg = sk_lin_reg().fit(X.reshape(-1, 1), y)print("Intercept:", simple_ols_reg.intercept_, "Bet

软件测试中错误推断法(错误猜测法或错误推测法)
在软件测试中,错误推测法(又称为错误猜测法或错误推测法)是一种基于测试人员的经验、直觉和对软件错误原因的分析来预测并设计测试用例的方法。这种方法强调测试人员对软件需求和设计实现的深入理解,以及对以往项目中发现的缺陷、故障或失效数据的积累。以下是关于错误推测法的详细解析: 一、定义与基本思想 错误推测法是通过列举出程序中可能存在的错误和容易发生错误的特殊情况,并基于这些推测来设计测试用例的方法。

【python因果推断库6】使用 pymc 模型的工具变量建模 (IV)1
目录 使用 pymc 模型的工具变量建模 (IV) 使用 pymc 模型的工具变量建模 (IV) 这份笔记展示了一个使用工具变量模型(Instrumental Variable, IV)的例子。我们将会遵循 Acemoglu, Johnson 和 Robinson (2001) 的一个案例研究,该研究尝试解开强大的政治机构对于以国内生产总值(GDP)衡量的经济生产力的影响。本示例借鉴

ML17_变分推断Variational Inference
1. KL散度 KL散度(Kullback-Leibler divergence),也称为相对熵(relative entropy),是由Solomon Kullback和Richard Leibler在1951年引入的一种衡量两个概率分布之间差异的方法。KL散度不是一种距离度量,因为它不满足距离度量的对称性和三角不等式的要求。但是,它仍然被广泛用于量化两个概率分布之间的“接近程度”。 在

平均场变分推断:以混合高斯模型为例
文章目录 一、贝叶斯推断的工作流二、一个业务例子三、变分推断四、平均场理论五、业务CASE的平均场变分推断求解六、代码实现 一、贝叶斯推断的工作流 在贝叶斯推断方法中,工作流可以总结为: 根据观察者的知识,做出合理假设,假设数据是如何被生成的将数据的生成模型转化为数学模型根据数据通过数学方法,求解模型参数对新的数据做出预测 在整个pipeline中,第1点数据的生成过程

【python因果推断库2】使用 PyMC 模型进行差分-in-差分(Difference in Differences, DID)分析
目录 使用 PyMC 模型进行差分-in-差分(Difference in Differences, DID)分析 导入数据 分析 使用 PyMC 模型建模银行业数据集 导入数据 分析 1 - 经典 2×2 差分-in-差分 (DiD) 分析 2 - 具有多个干预前后观测值的差分-in-差分 (DiD) 分析 使用 PyMC 模型进行差分-in-差分(Differe

客流预测 | 基于Transformer下车站点客流推断研究(Matlab)
目录 效果一览基本介绍程序设计参考资料 效果一览 基本介绍 基于Transformer的车站客流推断研究是指利用Transformer模型来预测车站的客流情况。Transformer是一种强大的深度学习模型,特别擅长处理序列数据。研究可以为城市交通管理提供重要决策支持,帮助优化公共交通资源配置、减少拥堵、提高服务效率等。随着技术的不断进步,基于先进技术
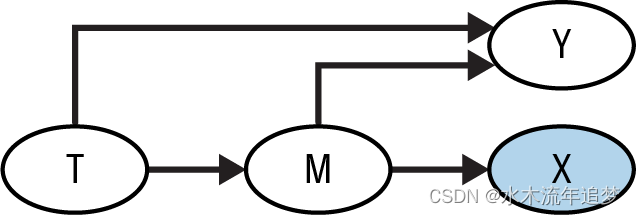
【Python实战因果推断】73_图因果模型8
目录 Adjusting for Selection Bias Conditioning on a Mediator Adjusting for Selection Bias 不幸的是,纠正选择偏倚绝非易事。在我们一直在讨论的例子中,即使有随机对照试验,ATE也无法识别,仅仅是因为你无法在对那些回应了调查的人进行条件化后,关闭新功能与客户满意度之间的非因果关联流。为了取得一些

Java 10 新特性解密,引入类型推断机制,将于 2018 年 3 月 20 日发布
JDK 10 何时发布? JDK 10 是 Java 10 标准版的部分实现,将于 2018 年 3 月 20 日发布,改进的关键点包括一个本地类型推断、一个垃圾回收的“干净”接口。 Oracle 已经为 Java 设定了六个月的发行计划。之前本打算根据发行的年份和月份命名升级版和后续版,这样的话第一个版本就会被称为 Java 18.3, 但这个计划后来被中止了。 如何下载 JDK 10? 用户
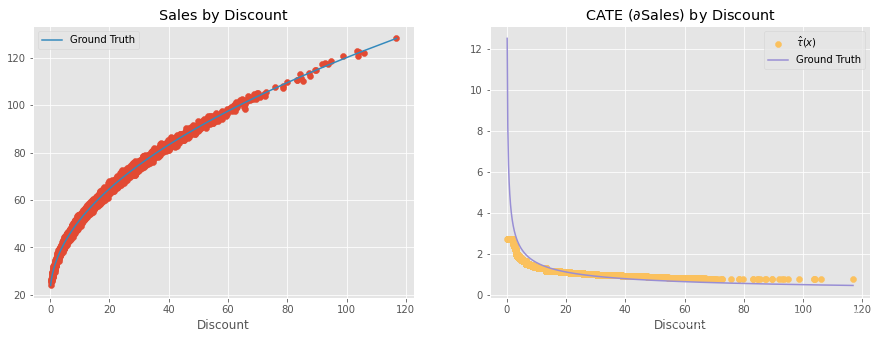
【因果推断python】51_去偏/正交机器学习3
目录 What is Non-Parametric About? What is Non-Parametric About? 在我们继续之前,我只想强调一个常见的误解。当我们考虑使用非参数 Double-ML 模型来估计 CATE 时,我们似乎会得到一个非线性治疗效果。例如,让我们假设一个非常简单的数据生成过程(DGP),其中 discont 对销售额的影响是非线性的,但却是通过
14、Spring之Bean生命周期~推断构造方法
14、Spring之Bean生命周期~推断构造方法 推断构造方法determineConstructorsFromBeanPostProcessors()方法autowireConstructor()方法instantiateBean()方法instantiateUsingFactoryMethod()方法 推断构造方法 spring在创建Bean对象的会调用createB
【因果推断python】45_估计量1
目录 问题设置 目标转换 到目前为止,我们已经了解了如何在干预不是随机分配的情况下对我们的数据进行纠偏,这会导致混淆偏差。这有助于我们解决因果推理中的识别问题。换句话说,一旦单位是可交换的,或者 ,就可以学习干预效果。但我们还远远没有完成。 识别意味着我们可以找到平均的干预效果。换句话说,我们知道一种干预的平均效果。当然,这很有用,因为它可以帮助我们决定是否应该真正实施干预。但
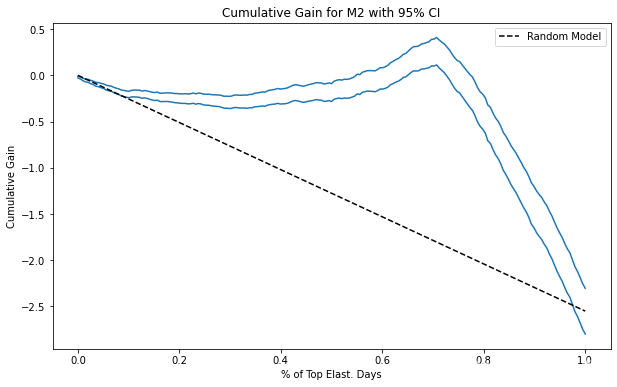
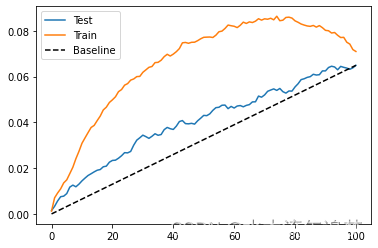
【因果推断python】44_评估因果模型2
目录 累积弹性曲线 累积增益曲线 考虑差异 关键思想 累积弹性曲线 再次考虑将价格转换为二元处理的说明性示例。我们会从我们离开的地方拿走它,所以我们有弹性处理带。我们接下来可以做的是根据乐队的敏感程度对乐队进行排序。也就是说,我们把最敏感的组放在第一位,第二个最敏感的组放在第二位,依此类推。对于模型 1 和 3,无需重新订购,因为它们已经订购。对于模型 2,我们必须颠倒排序
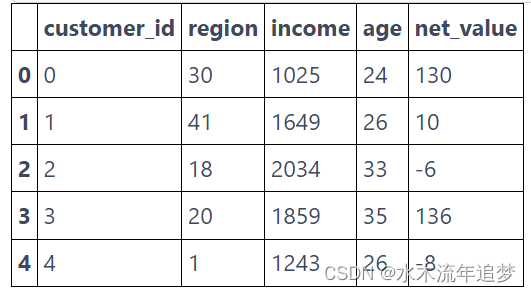
【因果推断python】38_预测模型1
目录 工业界中的机器学习 之前的部分涵盖了因果推理的核心。那里的技术是众所周知和成熟的。他们经受住了时间的考验。第一部分建立了我们可以依赖的坚实基础。用更专业的术语来说,第一部分侧重于定义什么是因果推理,哪些偏差会阻止相关性成为因果关系,调整这些偏差的多种方法(回归、匹配和倾向得分)和规范识别策略(工具变量、双重差分 和 断点回归)。总之,第一部分重点介绍了我们用来确定平均干预效果
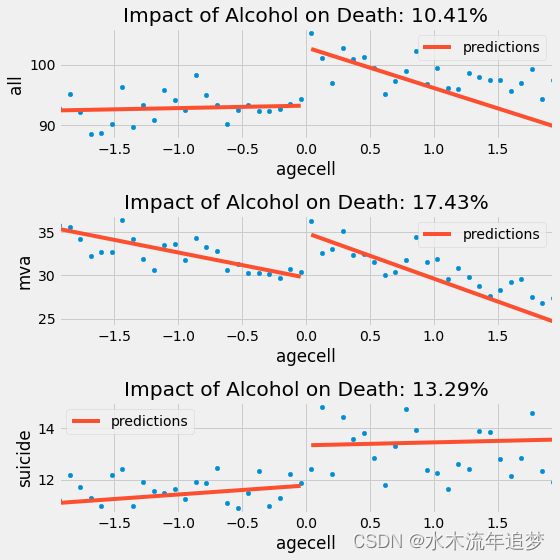
【因果推断python】36_断点回归2
目录 RDD 估计 内核加权 RDD 估计 RDD 依赖的关键假设是阈值处潜在结果的平滑性。用比较正式地表述来说,当运行变量从右侧和左侧接近阈值时,潜在结果的极限应该是相同的。 如果这是真的,我们可以在阈值处找到因果关系 从其本身意义来说,这是一种局部平均干预效果(LATE),因为我们只能在阈值处知道它。在这种情况下,我们可以将 RDD 视为局部随机试验。对于那些处

测试基础13:测试用例设计方法-错误推断、因果图判定表
课程大纲 1、错误推测法 靠主观经验和直觉来推测可能容易出现问题的功能或场景,设计相关测试用例进行验证。 2、因果图&判定表 2.1定义 因果图和判定表是分析和表达多逻辑条件下,执行不同操作的情况的工具。 (因果图和判定表配合使用,熟练后可直接写判定表。) 2.2应用场景 满足以下几个条件,适合使用因果图&判定表方法进行用例
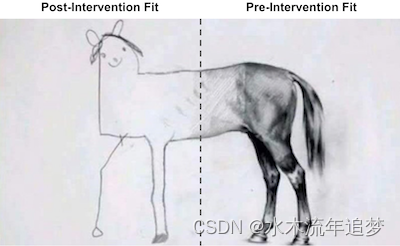
【因果推断python】32_合成控制2
目录 合成控制作为线性回归的一种实现编辑 合成控制作为线性回归的一种实现 为了估计综合控制的治疗效果,我们将尝试构建一个类似于干预期之前的治疗单元的“假单元”。然后,我们将看到这个“假单位”在干预后的表现。合成控制和它所模仿的单位之间的区别在于治疗效果。 要使用线性回归做到这一点,我们将使用 OLS 找到权重。我们将最小化干预前期间供体池中单位的加权平均值与治疗单位之间的平方

inferCNV:scRNA-seq数据推断染色体拷贝数变化
inferCNV分析简介 inferCNV用于探索肿瘤单细胞RNA-Seq 数据,以确定体细胞大规模染色体拷贝数改变的证据,例如整个染色体或大片段染色体的增益或缺失。这是通过与一组参考“正常”细胞(这里的正常细胞可自行定义)进行比较,探索肿瘤基因组各部位基因的表达强度来完成的。热图展示每个染色体的相对表达强度,并且与“正常”细胞相比,肿瘤基因组的哪些区域过表达或降低(异常)。 同时我们需要了解

【论文速读】| 通过大语言模型从协议实现中推断状态机
本次分享论文:Inferring State Machine from the Protocol Implementation via Large Language Model 基本信息 原文作者:Haiyang Wei, Zhengjie Du, Haohui Huang, Yue Liu, Guang Cheng, Linzhang Wang, Bing Mao 作者单位:
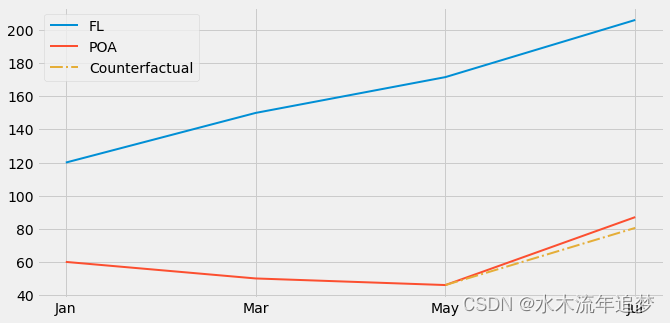
【因果推断python】30_双重差分1
目录 巴西南部的三个广告牌 DID 估计器 非平行趋势 关键思想 巴西南部的三个广告牌 从事营销工作时,互联网广告是一个很棒的途径。不是因为它非常有效(尽管确实如此),而是因为很容易知道它是否有效。通过在线营销,您可以了解哪些客户看到了广告,并且您可以使用 cookie 跟踪他们,看看他们是否最终出现在您的目标网页上或点击了某个下载按钮。您还可以使用机器学习来寻找与您的客户
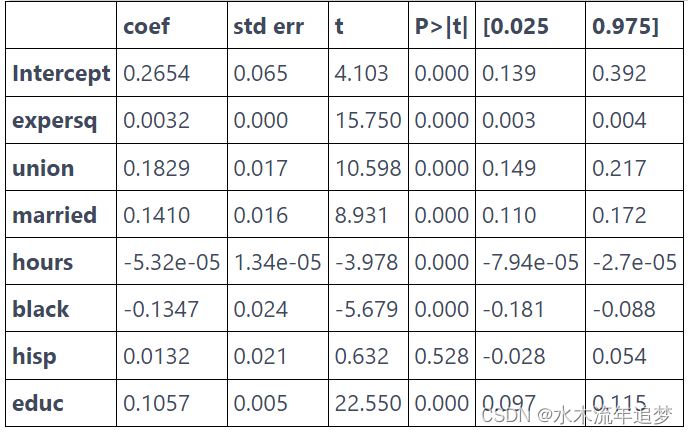
【因果推断python】28_面板数据和固定效应2
目录 固定效应 固定效应 为了方面后面更正式地讲述,让我们首先看一下我们拥有的数据。按照我们的例子,我们将尝试估计婚姻对收入的影响。我们的数据包含多年以来多个个体 (nr) 的这两个变量,married 和lwage。请注意,工资采用对数形式。除此之外,我们还有其他控制措施,例如当年的工作小时数、受教育年限等。 from linearmodels.datasets import
【因果推断python】26_双重稳健估计1
目录 不要把所有的鸡蛋放在一个篮子里 双重稳健估计 关键思想 不要把所有的鸡蛋放在一个篮子里 我们已经学会了如何使用线性回归和倾向得分加权来估计 。但是我们应该在什么时候使用哪一个呢?在不明确的情况下,请同时使用两者!双重稳健估计是一种将倾向得分和线性回归相结合的方法,您不必依赖它们中的任何一种。 为了了解这是如何工作的,让我们考虑一下心态实验。这是一项在美国公立高中进行的