本文主要是介绍【Python实战因果推断】73_图因果模型8,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Adjusting for Selection Bias
Conditioning on a Mediator
Adjusting for Selection Bias
不幸的是,纠正选择偏倚绝非易事。在我们一直在讨论的例子中,即使有随机对照试验,ATE也无法识别,仅仅是因为你无法在对那些回应了调查的人进行条件化后,关闭新功能与客户满意度之间的非因果关联流。为了取得一些进展,你需要做出进一步的假设,而这正是图形模型开始发挥作用的地方。它使你能够对这些假设非常明确和透明。
例如,你需要假设结果不会导致选择。在我们的例子中,这意味着客户满意度不会导致客户更可能或更不可能回答调查。相反,你将有一些其他可观察变量(或变量集合),它们既导致选择又影响结果。例如,唯一导致客户回应调查的因素可能是他们在应用程序中花费的时间和新功能。在这种情况下,治疗组和对照组之间的非因果关联通过在应用程序中花费的时间流动:

只有专家知识才能告诉你这是一个多么强烈的假设。但如果它是正确的,一旦你控制了在应用程序中花费的时间,新功能对满意度的影响就变得可识别了。
再一次,你在这里应用了调整公式。你只是将数据分割成由X定义的组,以便在这些组内,治疗组和对照组变得可比。然后,你可以简单地计算治疗组和对照组内部比较的加权平均值,使用每个组的大小作为权重。只是现在,你这样做时,同时对选择变量进行了条件化:
总的来说,为了调整选择偏倚,你必须调整导致选择的所有因素,同时还要假设结果或治疗既不直接导致选择,也不与选择共享隐藏的共同原因。例如,在以下图中,由于对S进行条件化打开了T和Y之间的非因果关联路径,存在选择偏倚:
你可以通过调整解释选择的可测量变量X3、X4和X5来关闭其中两条路径。然而,有两条路径你无法关闭(用虚线表示):Y->S<-T和T->S<-U->Y。这是因为治疗直接导致选择,而结果与选择共享一个隐藏的共同原因。你可以通过进一步对X2和X1进行条件化来减轻这条路径带来的偏倚,因为它们解释了U的一些变化,但这不会完全消除偏倚。这个图反映了在选择偏倚问题中你更可能遇到的更现实情况,就像我们刚刚作为例子使用的选择偏差。在这些情况下,你能做的最好的事情是对解释选择的变量进行条件化。这将减少偏倚,但不会完全消除它,因为如你所见,1)有导致选择的因素是你不知道或无法测量的,2)结果或治疗可能直接导致选择。
我也并不想给你错误的印象,以为仅仅控制导致选择的一切因素是一个好主意。在以下图中,对X进行条件化会打开一条非因果路径,Y->X<-T:
Conditioning on a Mediator
目前为止所讨论的选择偏倚是由不可避免地进入某个群体的选择引起的(你被迫对响应者群体进行条件化),但你也可以不经意间造成选择偏倚。例如,假设你从事人力资源工作,你想要查明是否存在性别歧视,即同等资质的男性和女性是否薪酬不同。为了进行这项分析,你可能会考虑控制资历等级;毕竟,你想要比较的是资质相同的员工,而资历似乎是一个很好的代理指标。换句话说,你认为如果同一职位的男性和女性薪资不同,你将有证据证明公司存在性别薪酬差距。
这种分析的问题在于,因果图可能看起来像这样:

资历等级是治疗(女性)与薪资之间的路径中的中介变量。直观上,女性和男性之间的薪资差异有一个直接原因(直接路径:女性->薪资)和一个间接原因,通过资历流动(间接路径:女性->资历->薪资)。这张图告诉你,女性遭受歧视的一种方式是她们升迁至更高资历的概率较低。男性和女性之间的薪资差异部分是同一资历级别下的薪资差异,但也是资历级别的差异。简而言之,女性->资历->薪资路径也是治疗与结果之间的因果路径,你不应在分析中关闭它。如果你在控制资历的情况下比较男性和女性的薪资,你只会识别出直接歧视,即女性->薪资。
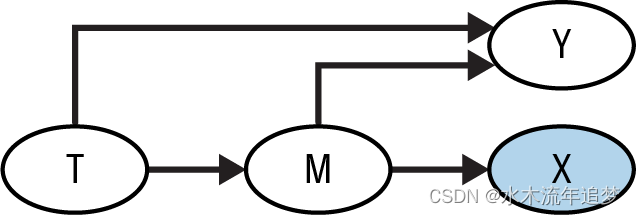
值得一提的是,对中介节点的后代进行条件化也会引起偏倚。这种选择并没有完全关闭因果路径,但部分阻塞了它:
这篇关于【Python实战因果推断】73_图因果模型8的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





