信息熵专题

信息熵|atttion矩阵的注意力熵
显著图可以看作是模型的注意力图,它标识了模型对输入图像某些区域的关注程度。我们使用 blob 区域(连通的显著区域)来检测模型关注的部分,然后计算这些区域的概率分布,再通过熵来衡量这些区域的“信息量”或“分散度”。 举个简单的例子: Step 1: 假设有一个 4x4 的注意力图 x: x = [[0.1, 0.2, 0.4, 0.1],[0.1, 0.5, 0.3, 0.2],[0.7,
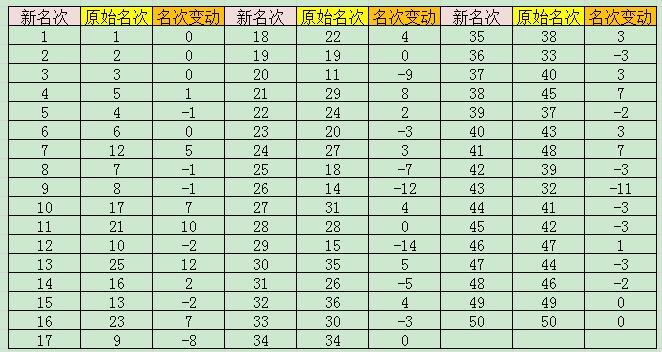
用基于信息熵的topsis方法实现学生成绩的综合排名
TOPSIS方法排序的基本思路是首先定义决策问题的正理想解(即最好的)和负理想解(即最坏的),然后把实际可行解(样本)和正理想解与负理想解作比较。通过计算实际可行解与正理想解和负理想解的加权欧氏距离,得出实际可行解与正理想解的接近程度,以此作为排序的依据。若某个可行解(样本)最靠近理想解,同时又最远离负理想解,则此解排序最靠前。 通常,当排序时有多个指标需要考虑时,常用“专家打分法”来确定各个指
熵的相关概念及相互关系(信息熵,条件熵,相对熵,交叉熵,最大似然估计)
熵:系统混乱程度的度量,系统越混乱,熵越大。 信息熵:信息量的大小的度量,用于描述随机变量的不确定度。事件的不确定性越大,则信息量越大,信息熵越大。定义如下: 条件熵:表示在已知随机变量X的条件下随机变量Y的不确定性。定义如下: 另外,,说明描述X和Y所需的信息(H(X,Y)

编程实现基于信息熵/基尼指数划分选择的决策树算法
编程实现基于信息熵/基尼指数划分选择的决策树算法 手动建立一个csv文件 #csv的内容为Idx,color,root,knocks,texture,navel,touch,density,sugar_ratio,label1,dark_green,curl_up,little_heavily,distinct,sinking,hard_smooth,0.697,0.46,12,b

信息熵,交叉熵,相对熵,KL散度
熵,信息熵在机器学习和深度学习中是十分重要的。那么,信息熵到底是什么呢? 首先,信息熵是描述的一个事情的不确定性。比如:我说,太阳从东方升起。那么这个事件发生的概率几乎为1,那么这个事情的反应的信息量就会很小。如果我说,太阳从西方升起。那么这就反应的信息量就很大了,这有可能是因为地球的自转变成了自东向西,或者地球脱离轨道去到了别的地方,那么这就可能导致白天变成黑夜,热带雨林将

信息熵与信息增益的概念
关于熵的概念: 熵是一个信息论中很抽象的概念,从熵定义的角度来看,熵表示一组信息中,所有随机变量出现的期望,他的计算公是: Entropy(S):H(x)=∑p(xi)*log1/(p(xi)) (i=1,2,..n)=-∑p(xi)*log(p(xi)) (i=1,2,..n)其中log的底数是2. 公式的理解是:p(i)表示第i个变量出现的概率,则1/p(i)表示若p(i)发生的样本容量

机器学习-利用信息熵来学习如果分辨好西瓜
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。 我们通常用Entropy(信息熵来度量划分的凌乱程度)。 Ent(D)越小,则信息熵的复杂程度越低,D的纯度(一

信息量,信息熵,纯度
如果看不懂博文,请阅读《信息论基础》一看便懂。 链接:https://pan.baidu.com/s/1T7rS4owM2nU_DP6rthqUPA 提取码:zu9s (1)消息 消息是实体,信息是抽象的。可以从消息中获取信息。消息的表现形式可以是:语言,符号,文字,图片 (2)信息 信息是抽象的,消息是信息的载体。 举例:如果把某个人说的话看成是消息的话,那他话中传递的意思就是信

熵、信息熵、交叉熵、相对熵、条件熵、互信息、条件熵的贝叶斯规则
熵 每条消息都含有信息。“信息熵”是“熵”的别名,用来衡量消息的不确定程度。 宽泛来讲,即消息所传达的信息的模糊程度,消息越模糊,其熵越高。 形象的说,熵是从 根据模糊消息—>得到精确信息 所需要花费的最小代价。 熵=信息量(的期望)=不确定性的多少。熵值是信息量的一个度量。 某种意义上说,熵就是最优策略。 《数学之美》中这样描述: 变量的不确定性越高,熵也就越大,要把它搞清楚,所

二元信息熵 python实现、绘图
import matplotlib.pyplot as pltfrom math import logimport numpy as np#计算二元信息熵def entropy(props, base=2):sum = 0for prop in props:sum += prop * log(prop, base)return sum * -1#构造数据x = np.arange(0.0
为什么信息熵要定义成-Σp*log(p)?
From https://www.zhihu.com/question/30828247 作者:西贝 链接:https://www.zhihu.com/question/30828247/answer/64816509 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 我从一个非常直观的角度来解释一下熵的定义为什么如题主所示。 第一,假设存在

KL散度交叉熵信息熵不确定性信息度量
0.起源 物理学中的热力学 熵:度量分子在物理空间中的混乱程度; 1.信息熵 信息熵: 度量信息量的多少; 以离散信息为例 离散符号:x1,x2,…,xn; 信息中各符号出现的概率:p1,p2,…,pn; 信息的不确定性函数: f: p—f(p); p越大,信息的不确定性越小,因此f是一个 减函数; 假设前提: 各符号的出现是相互独立的(与实际不符) 则:f(p1,p2)=f(p1)+f(p

ID3算法 信息熵计算公式
gain.py import mathdef I(s1, s2):''':param s1: 值为1的数量:param s2: 值为0的数量:return: 返回期望值'''s = s1 + s2if s1 == 0 or s2 == 0:return 0# print("s1 = {}, s2 = {}, s = {}".format(s1,s2,s))ex = - (s1 / s)
信息量与信息熵的概念
信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大,如湖南产生的地震了;越大概率的事情发生了产生的信息量越小,如太阳从东边升起来了(肯定发生嘛,没什么信息量)。 原文: https://zhuanlan.zhihu.com/p/26486223
神经网络数学基础-香浓信息量、信息熵、交叉熵、相对熵(KL散度)
香浓信息量 这里以连续随机变量的情况为例。设 为随机变量X的概率分布,即 为随机变量 在 处的概率密度函数值,随机变量 在 处的香农信息量定义为: 这时香农信息量的单位为比特,香农信息量用于刻画消除随机变量在处的不确定性所需的信息量的大小。 如果非连续型随机变量,则为某一具体随机事件的概率。 为什么是这么一个表达式呢?想具体了解的可以参考如下的讨论: 知乎-香农的信息论究
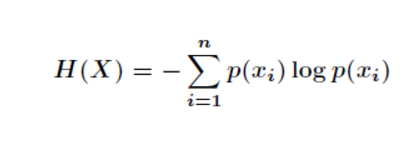
信息熵是什么 转 理论吃透的创新解释
作者:忆臻 链接:https://www.zhihu.com/question/22178202/answer/161732605 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 下面根据我的理解一步一步引出信息熵及其公式的来源: 信息熵的公式 先抛出信息熵公式如下: 其中 信息量 信息量是对信息的度量,就跟时间的度量是秒一样,当我们考虑一个离

Visual Studio 2010+C#实现信源和信息熵
1. 设计要求 以图形界面的方式设计一套程序,该程序可以实现以下功能: 从输入框输入单个或多个概率,然后使用者可以通过相关按钮的点击求解相应的对数,自信息以及信息熵程序要能够实现马尔可夫信源转移概率矩阵的输入并且可以计算该马尔可夫信源在每一个状态下每输出一个符号的平均信息量,稳态概率以及最后的信息熵。结果在在界面中直接呈现 2. 设计过程 首先进行图形界面的设计,根据要求界面中应该包括相关
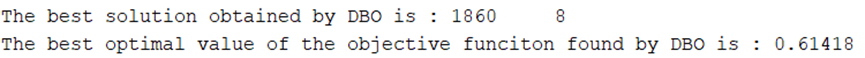
蜣螂优化算法(DBO)优化VMD参数,最小包络熵、样本熵、信息熵、排列熵(适应度函数可自行选择,一键修改)包含MATLAB源代码
蜣螂优化算法是华大学沈波教授团队,继麻雀搜索算法(Sparrow Search Algorithm,SSA)之后,于2022年11月27日又提出的一种全新的群体智能优化算法。已有很多学者将算法用于实际工程问题中,今天咱们用蜣螂优化算法优化一下VMD参数。 同样以西储大学数据集为例,选用105.mat中的X105_BA_time.mat数据中1000个数据点。没有数据的看我这篇文章。西储大学轴承数
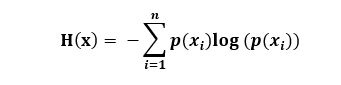
中国汉字书法的回溯感和信息熵
文章目录 一、 汉字书法的动态欣赏二、汉字书法的回溯感2.1回溯感测量--运动感测量2.2回溯感测量--顺序感测量2.3回溯感测量--过程感测量2.4测量的意义 三、信息量和信息熵3.1信息量3.2信息熵 一、 汉字书法的动态欣赏 中国的汉字书法作为五千年璀璨的文明为世人所认可。在中国博大精深的历史长河中,书画艺术以其独特的艺术形式和艺术语言再现了这一历时性的嬗变过程。 虽然

信息熵与经验熵:详解弱典型集
目录 一. 弱典型集 1.1 基本介绍 1.2 补充弱大数定律 1.3 渐进等分性(AEP) 二. 联合弱典型集 2.1 基本介绍 2.2 联合渐近等分性 2.3互信息相关 三. 与物理层安全的关系 结论 一. 弱典型集 1.1 基本介绍 我们说一个序列很“典型”,通常指的是这个序列能反映总体分布的一些性质。如果一个序列的经验熵(empirical entropy
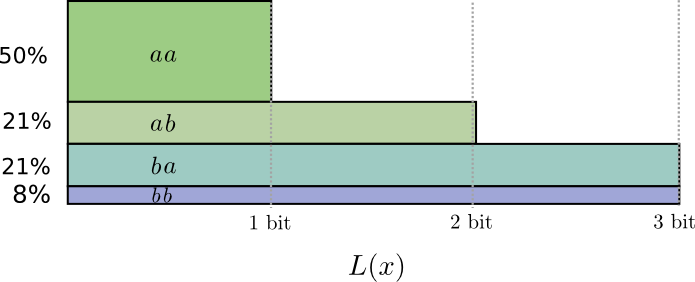
信息、信息熵、条件熵、信息增益、信息增益率、GINI指数、交叉熵、相对熵
在信息论与概率统计学中,熵(entropy)是一个很重要的概念。在机器学习与特征工程中,熵的概念也常常是随处可见。自己在学习的过程中也会常常搞混,于是决定将所有与熵有关的概念整理总结,方便查看和学习。 1. 信息 它是熵和信息增益的基础概念。引用香农的话,信息是用来消除随机不确定性的东西。如果一个带分类的事物集合可以划分为多个类别,则其中某个类(xi)的信息定义:
机器学习基础-22:信息论和信息熵
信息论和信息熵 机器学习原理与实践(开源图书)-总目录,建议收藏,告别碎片阅读! 熵的概念最早起源于物理学,用于度量一个热力学系统的无序程度。在信息论里则叫信息量,即熵是对不确定性的度量。从控制论的角度来看,应叫不确定性。信息论的创始人香农在其著作《通信的数学理论》中提出了建立在概率统计模型上的信息度量。他把信息定义为“用来消除不确定性的东西”。在信息世界,熵越高,则能传输越多的信息,熵

决策树-信息熵、ID3、C4.5算法介绍
决策树 例子 熵 ID3算法 信息增益:表示得知特征X的信息而使得类Y的信息的不确定性减少的程度 选择根节点(数字最大的那个,这里是age) 连续变量处理 可以对数据进行分割,然后计算分割点信息增益 C4.5算法
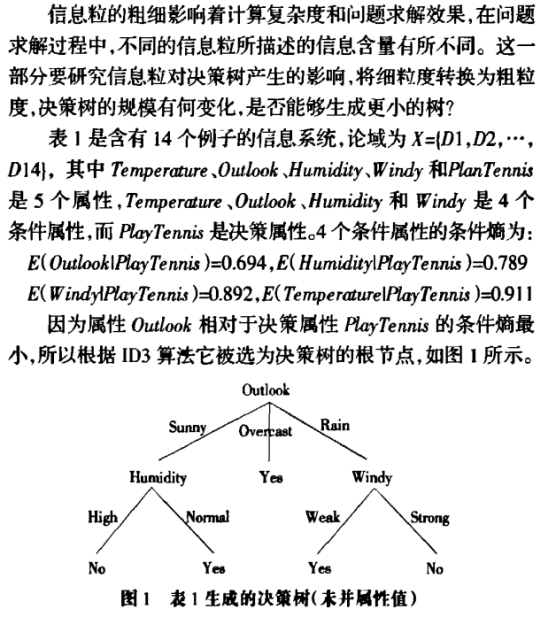
P02114200祁琪,P02114213杨佳儒,P02114193魏子昂,P02114105江琦,P02114208辜子豪——信息熵可加性和递增性的证明研究与拓展
目录 1.预备知识 2.证明过程 2.1.对于信息熵可加性的证明 2.2.对于信息熵递增性的证明 3.拓展 3.1可加性的拓展 3.2递增性的扩展 3.3信息粒和决策树 3.3.1.信息粒 3.3.2.信息熵与信息粒 3.3.3.决策树 3.3. 4.信息粒与决策树 3.3.5.结论 4.总结 1.预备知识 信息熵(information entropy