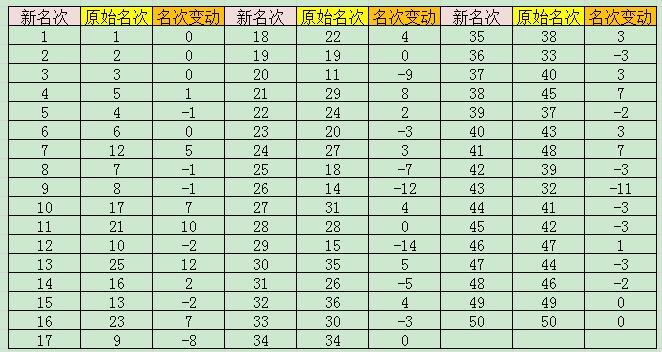
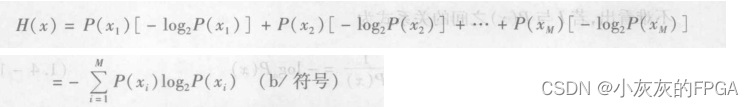本文主要是介绍信息量,信息熵,纯度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果看不懂博文,请阅读《信息论基础》一看便懂。
链接:https://pan.baidu.com/s/1T7rS4owM2nU_DP6rthqUPA
提取码:zu9s 
(1)消息
消息是实体,信息是抽象的。可以从消息中获取信息。消息的表现形式可以是:语言,符号,文字,图片
(2)信息
信息是抽象的,消息是信息的载体。
举例:如果把某个人说的话看成是消息的话,那他话中传递的意思就是信息。
(3)信号
消息经过编码之后就变成信号。比如光信号,电信号。
(4)信息量
例如一句话:“马云是男人”,这句话,大家都知道,毫无价值,信息量为零。
另一句话:“阿里巴巴股票明天要下跌”,那么这句话就有一定的价值,包含有一定的信息量。
那么接下来的问题就是如何把信息量给量化,说白了如何用数学的方式来描绘它。




说一千道一万,就是为了让信息量和不确定性划上等号,然后借用数学中的随机变量来描绘信源的消息。



(5)信息熵

注:这个某一特定符号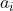 怎么理解呢?就是指数据集的某一字段(特征)。
怎么理解呢?就是指数据集的某一字段(特征)。




(6)信息熵与纯度
信息熵越小,就说明不确定性越低,确定性越高,纯度越高。
什么时候确定性高呢?
仍然以上面红白球为例,如果全是红球,那么信息熵为零,不确定性为零,确定性为百分之百,这是我们称样本集合纯度高。
这篇关于信息量,信息熵,纯度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!