inductive专题

【论文阅读】Model Stealing Attacks Against Inductive Graph Neural Networks(2021)
摘要 Many real-world data(真实世界的数据) come in the form of graphs(以图片的形式). Graph neural networks (GNNs 图神经网络), a new family of machine learning (ML) models, have been proposed to fully leverage graph data(

Locality-aware subgraphs for inductive link prediction in knowledge graphs
Locality-aware subgraphs for inductive link prediction in knowledge graphs a b s t r a c t 最近的知识图(KG)归纳推理方法将链接预测问题转化为图分类任务。 他们首先根据目标实体的 k 跳邻域提取每个目标链接周围的子图,使用图神经网络 (GNN) 对子图进行编码,然后学习将子图结构模式映射到链接存在的函
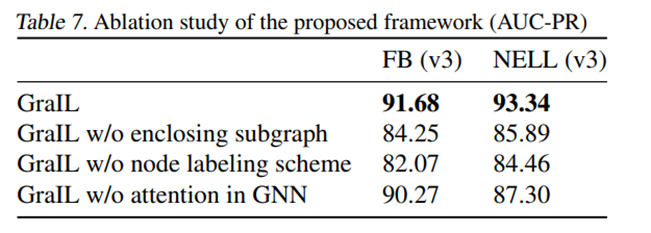
论文阅读《2020ICML:Inductive Relation Prediction by Subgraph Reasoning》
论文链接 论文工作简介 知识图谱中关系预测的主要范式涉及实体和关系的潜在表示(即嵌入)的学习和操作。 然而,这些基于嵌入的方法并没有显式地捕获知识图谱背后的组合逻辑规则,并且它们仅限于直推式设置,在直推式设置中,实体的全部集合必须在训练期间已知。 本文提出了一种基于图神经网络的关系预测框架GraIL,它在局部子图结构上进行推理,并具有很强的归纳偏差来学习实体独立的关系语义。 如右图,

【过程发现算法2】Inductive Miner-InFrequency(基于频次的归纳式挖掘算法)
Inductive Miner-Infrequency(基于频次的归纳式挖掘)是在上一节Inductive Miner的基础上进行改进的算法,由sander改进并完善,接下来,我们将详细地介绍这个算法。 1. 背景介绍 关于infrequent的解释:在大多数现实生活中的事件日志中,一些轨迹很少被采用,或者轨迹的不同之处仅在于不经常发生的活动。 如果模型中包含不常见的行为,可能会牺牲简
【过程发现算法1】-Inductive Miner(归纳式挖掘)
Inductive Miner(归纳式挖掘)是目前已有的过程发现算法中最先进的一种算法,在2013年由sander提出,他是一种基于过程树的算法,并在上面衍生了各种变体算法,比如Inductive Miner-Infrequency, Inductive Miner-Lifecycle等,接下来,我们就详细地介绍这个基本的Inductive Miner算法。 1.背景介绍 已有过程发

论文笔记11:Relational inductive biases, deep learning, and graph networks翻译笔记
关系归纳偏置、深度学习和图网络 DeepMind; Google Brain; MIT; University of Edinburgh 参考 https://zhuanlan.zhihu.com/p/40733008 摘要 人工智能近几年大火起来,在计算机视觉、自然语言处理、控制和决策等关键领域取得重大进展。这在一定程度上归因于廉价的数据和计算资源,它们符合深度学习的本质优势。然
Inductive Representation Learning on Large Graphs 论文/GraphSAGE学习笔记
1 动机 1.1 过去的方法 现存的方法大多是transductive的,也就是说,在训练图的时候需要将整个图都作为输入,为图上全部节点生成嵌入,每个节点在训练的过程中都是可知的。举个例子,上一次我学习了GCN模型,它的前向传播表达式为: H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)}=σ(\wid
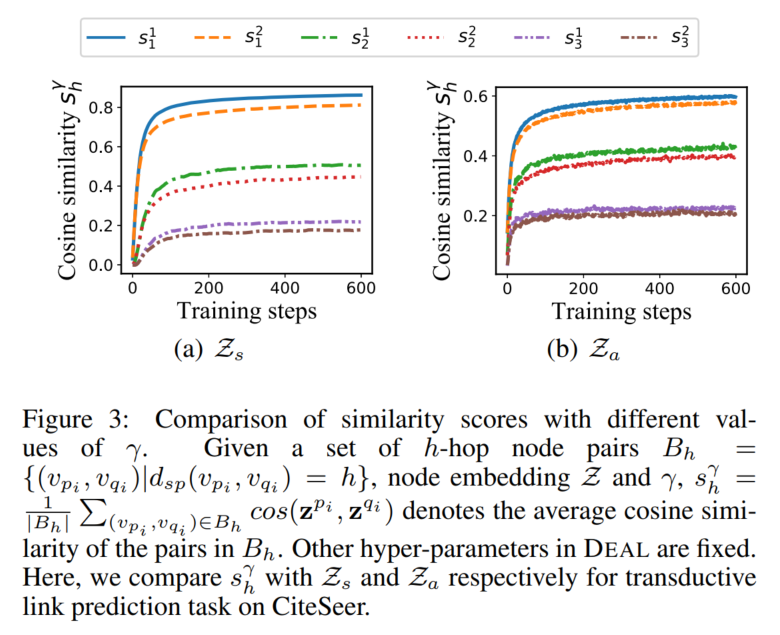
Re9:读论文 DEAL Inductive Link Prediction for Nodes Having Only Attribute Information
诸神缄默不语-个人CSDN博文目录 论文名称:Inductive Link Prediction for Nodes Having Only Attribute Information 论文ArXiv下载地址:https://arxiv.org/abs/2007.08053 论文IJCAI官方下载地址:https://www.ijcai.org/proceedings/2020/168(在该网站

【论文笔记】GraphSAGE:Inductive Representation Learning on Large Graphs(NIPS)
学习心得 GCN不能泛化到训练过程中没有出现的节点(即属于 t r a n s d u c t i v e transductive transductive 直推式学习,若加入新节点则需要重新训练模型),既然有新增的结点(一定会改变原有节点),那就没必要一定得到每个节点的固定表示。而GraphSAGE就是为了解决这种问题,利用Sample(采样)和Aggregate(聚合)两大核心步骤,通过

Inductive and Unsupervised Representation Learning on Graph Structured Objects
文章目录 1 前言2 问题定义3 SEED思路3.1 Sampling3.2 Encoding3.3 Embedding Distribution 4 方法的优势与局限性4.1 优势4.2 局限性 论文地址:https://openreview.net/pdf?id=rkem91rtDB源码:SEED-reimplementation来源:ICLR, 2020关键词:unsup
什么是Inductive learning和Transductive learning
1. Inductive learning Inductive learning (归纳式学习)。归纳是从已观测到的数据到一般数据的推理,归纳学习即我们平时所说的监督学习,使用带有标签的数据进行模型训练,然后使用训练好的模型预测测试集数据的标签,训练集数据不包含测试集数据。 2. Transductive learning Transductive learning (直推式学习)。直推是从

TGAT:INDUCTIVE REPRESENTATION LEARNING ON TEMPORAL GRAPHS 论文笔记
INDUCTIVE REPRESENTATION LEARNING ON TEMPORAL GRAPHS 摘要简介TGAT框架Time Encoding函数时序图注意力层(TGAT layer)如果边上有不同的特征 实验实验设置Loss Function 摘要 在时序图上进行推断式表示学习十分重要。作者提出节点embedding应该同时包括静态节点特征以及变化的拓扑特征。作者提

论文阅读-(HyperGAT)Be More with Less: Hypergraph Attention Networks for Inductive Text Classification
Be More with Less: Hypergraph Attention Networks for Inductive Text Classification 一、摘要 文本分类是自然语言处理中一个重要的研究课题,有着广泛的应用。最近,图神经网络(gnn)在研究界得到了越来越多的关注,并在这一规范任务中展示了有前景的结果。 GNN 在文本分类表现能力受损: 因为:(1)无法捕捉单词之
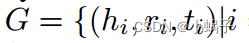
Multi-Aspect Explainable Inductive Relation Prediction by Sentence Transformer
摘要 最近关于知识图(KGs)的研究表明,通过预先训练的语言模型授权的基于路径的方法在提供归纳和可解释的关系预测方面表现良好。本文引入关系路径覆盖率和关系路径置信度的概念,在模型训练前过滤掉不可靠的路径,以提高模型的性能。此外,我们提出了知识推理句子转换器(Knowledge Reasoning Sentence Transformer, KRST)来预测KGs中的归纳关系,KRST将提取的可靠

inductive learning 与 transductive learning在图神经网络上的区别
监督学习与非监督学习 监督学习 简单解释: 监督学习就是要在一组有标签信息的数据中训练一个模型,然后将该模型应用于一组测试数据上分析模型的泛化误差。 监督学习会把数据分成训练集和测试集,监督学习方法的重要假设是数据的分布是独立同分布的。监督学习要在训练数据中归纳出一个一般规则然后应用于测试数据中。训练数据是有标签的,测试数据是没有标签的。 百度百科解释 非监督学习, 简单解释: 非监督学习

GraphSAGE-Inductive Representation Learning on Large Graphs
简介 GraphSAGE-原文在摘要中这样介绍:we learn a function that generates embeddings by sampling and aggregating features from a node’s local neighborhood.我们学习一个函数,这个函数可以从一个节点的邻居节点中进行采样和聚合特征来生成embedding。 如何理解呢?简单来说
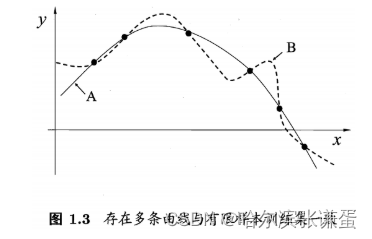
机器学习---归纳偏执(Inductive Bias)
归纳偏执(Inductive Bias) 背景与概念介绍 No-Free-Lunch (不存在免费午餐理论)提出没有先验知识进行学习是不可能的。如果我们不对特征空间有先验假设,则所有算法的平均表现是一样的。 一、概念 Inductive bias,我们来看一下这两个单词是什么意思: 归纳(Induction)是自然科学中常用的两大方法之一(归纳与演绎, induction and ded