本文主要是介绍论文阅读《2020ICML:Inductive Relation Prediction by Subgraph Reasoning》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接
论文工作简介
知识图谱中关系预测的主要范式涉及实体和关系的潜在表示(即嵌入)的学习和操作。
然而,这些基于嵌入的方法并没有显式地捕获知识图谱背后的组合逻辑规则,并且它们仅限于直推式设置,在直推式设置中,实体的全部集合必须在训练期间已知。
本文提出了一种基于图神经网络的关系预测框架GraIL,它在局部子图结构上进行推理,并具有很强的归纳偏差来学习实体独立的关系语义。

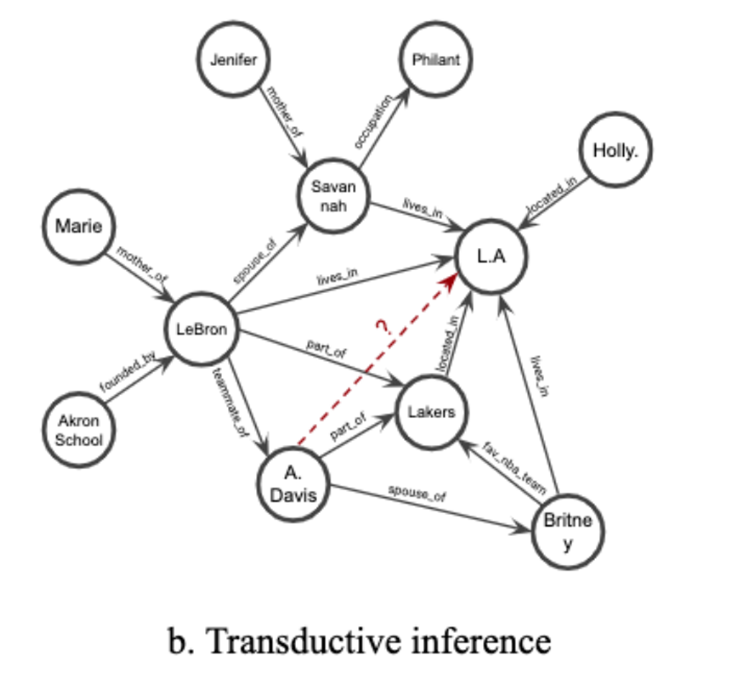
如右图,LeBron和A·Davis的嵌入将包含他们 都是湖人队的一部分的信息,稍后可以检索这些信息 来预测他们是队友。同样,任何与湖人密切相关的人都将以高概率居住在洛杉矶。
基于嵌入的方法通过利用这种局部连接模式和同质性获得了巨大的成功。

本文的关键思想是从围绕两个节点的子图结构预测两个节点之间的关系,我们的方法是围绕图神经网络(GNN) 来展开,没有使用任何节点属性,以便测试GraIL仅从结构上学习和泛化的能力。
由于它永远只接收结构信息(即子图结构和结构节点特征)作为输入,因此GraIL能够完成关系预测任务的唯一方式是学习知识图谱背后的结构语义。
整体任务是对一个三元组(u,rt,v)进行评分,即预测KG中头节点u和尾节点v之间可能存在关系rt的可能性,其中我们将节点u和v称为目标节点,将rt称为目标关系。我们对这样的三元组进行评分的方法可以大致分为三个子任务(我们将在下面详细说明):
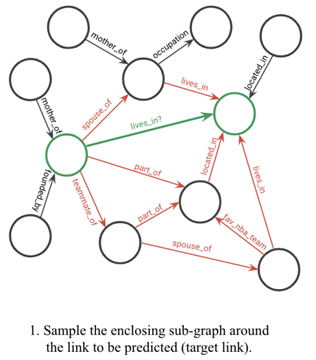
(i)提取目标节点周围的封闭子图。
(ii)标记提取的子图中的节点。
(iii)使用 GNN对标记的子图进行评分。
模型细节-子图提取
步骤1:子图提取。我们假设KG中特定三元组的局部图邻域将包含推断目标节点之间关系所需的逻辑证据。特别是,我们假设连接两个目标节点的路径包含可能隐含目标关系的信息。因此,作为第一步,我们提取了围绕目标节点的封闭子图。
将节点u和v之间的封闭子图定义为发生在u和v之间的路径上的所有节点诱导的图,它由两个目标节点的邻居的交集和随后的剪枝过程给出。
(注意,在提取封闭子图时,我们忽略了边的方向。然而,在用图神经网络传递消息时,方向是保留的,一个后来重新访问的点。此外,在提取的子图中添加了目标元组/边(u,rt,v),以实现两个目标节点之间的消息传递。)
模型细节-节点标注
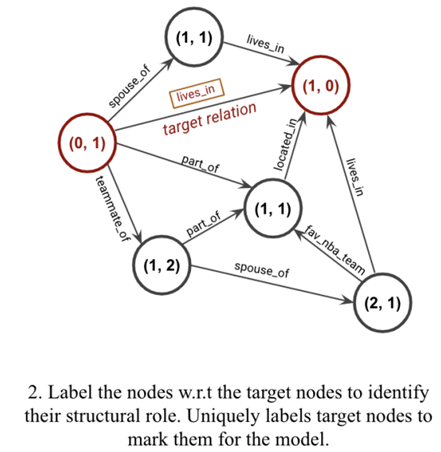
步骤2:节点标注。GNNs需要一个节点特征矩阵X∈R|V|×di作为输入,用于初始化神经消息传递算法。在节点u和v周围的子图中,每个节点i都被标记为元组(d(i, u), d(i, v)), 其中d(i, u)表示节点i和u之间的最短距离,不计算通过v的任何路径(对于d(i, v)也是如此)。这捕获了每个节点相对于目标节点的拓扑位置,并反映了它在子图中的 结构角色。两个目标节点u和v被唯一标记为(0,1)和(1,0) 以便被模型识别。
因此节点特征为[one-hot(d(i, u))⊕ one-hot(d(i, v))],其中⊕表示两个向量的拼接。
请注意,以这种方式构建的节点特征的维度受到提取封闭子图时考虑的跳数的限制。
模型细节-GNN评分
步骤3:GNN评分。我们框架中的最后一步是使用GNN对元组(u,rt,v)的可能性进行评分,给定G(u,v,rt)—提取并标记目标节点周围的子图。我们通过将节点表示与其邻居表示的聚合相结合来迭代更新节点表示。

其中akt是来自邻居的聚合消息,hkt表示第k层节点t的潜在表示,N(t)表示节点t的直接邻居集合。
任何节点i 的初始潜在节点表示h0i,初始化为根据步骤2中描述的标记方案构建的节点特征Xi。
受多关系R-GCN (Schlichtkrull et al.,2017)和边缘注意力的启发,我们将聚合函数定义为:
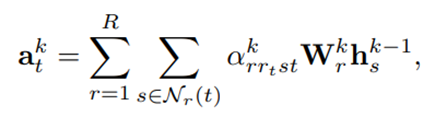
Nr (t) 表示节点t在关系r下的直接外出邻居
Wrk 是关系r上用于传播第k层消息的变换矩阵
Αrrtst 是边在第k层对应于通过关系r连接节点s和t的边注意力权重
这个注意力权重,是源节点t、邻居节点s、边类型r和要预测的目标关系rt的函数
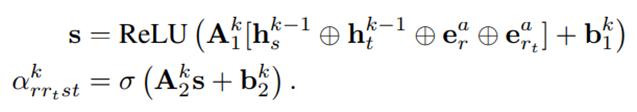
hks和hkt表示GNN第k层各自节点的潜在节点表示, ear和eart表示各自关系的学习到的注意力嵌入。
产生最佳结果的COMBINE函数也来自R-GCN架构:
![]()
使用上面描述的GNN架构,我们在L层消息传递之后获 得节点表示。通过对所有潜在节点表示进行平均池化, 得到G(u,v,rt )的子图表示:
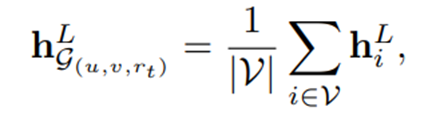
最后,为了获得三元组(u,rt,v)的可能性得分,我们连接四个向量—子图表示(hLG(u,v,rt)),目标节点的潜在表示(hLu和hLv),以及学习到的目标关系嵌入(ert),并将这些连接的表示通过线性层传递:
![]()
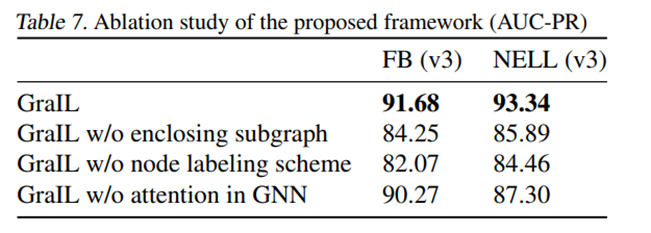
实验结果
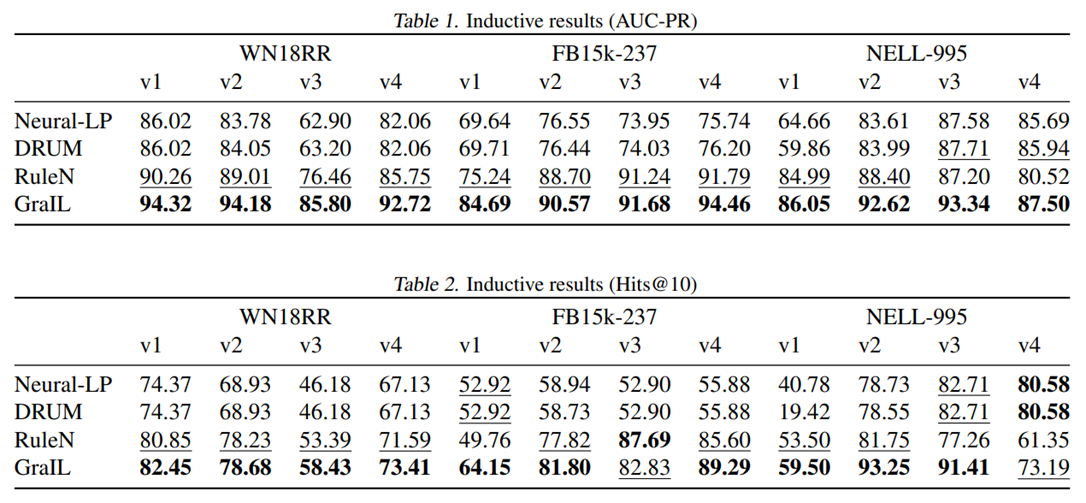
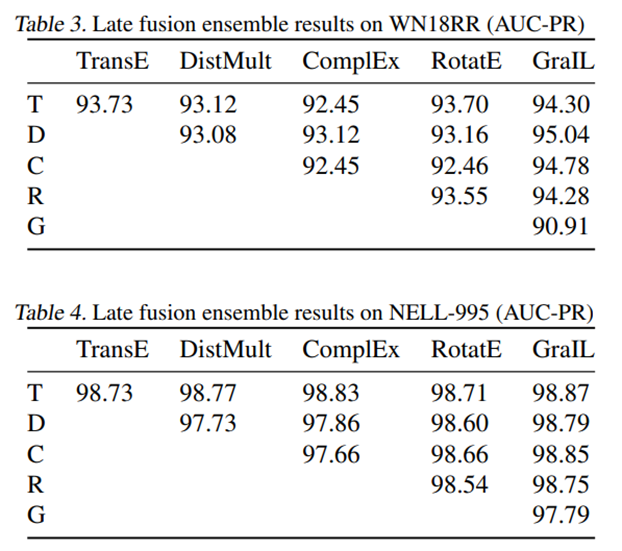
这篇关于论文阅读《2020ICML:Inductive Relation Prediction by Subgraph Reasoning》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
