本文主要是介绍Inductive and Unsupervised Representation Learning on Graph Structured Objects,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 前言
- 2 问题定义
- 3 SEED思路
- 3.1 Sampling
- 3.2 Encoding
- 3.3 Embedding Distribution
- 4 方法的优势与局限性
- 4.1 优势
- 4.2 局限性
- 论文地址:https://openreview.net/pdf?id=rkem91rtDB
- 源码:SEED-reimplementation
- 来源:ICLR, 2020
- 关键词:unsupervised learning, graph representation,
1 前言
该论文主要解决的是图结构数据的无监督的、inductive形式的表征问题。通常在无监督的图表征问题中,主要以重建损失为主导进行训练,但是在计算重建损失时通常要涉及到图的相似性计算,而图的相似性计算是一个十分复杂、耗时的过程,论文提出了一个通用的框架SEED(Sampling, Encoding and Embedding Distribution)用于无监督的学习图结构对象的表征。
2 问题定义
目标很简单,给定一个graph,学习它的表征。
3 SEED思路
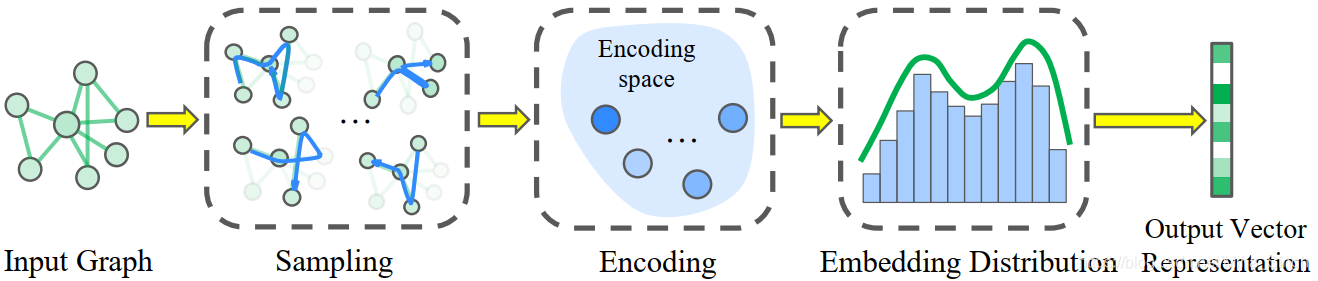
如上图所示所示,SEED主要分为三个部分:
3.1 Sampling
从输入的图中采样出多个子图。为了使得采样到的子图更具代表性,论文中提出了一种新的采样方法 — WEAVE(random Walk with EArliest Visit timE)。该方法与通常的随机游走不一样,WEAVE是带结点访问时间戳的。

如上图所示,WEAVE的区分能力比平凡的搜集游走更强。每一个WEAVE都代表一个采样到的子图,可以用一个矩阵表示: X = [ x ( 0 ) , x ( 1 ) , ⋯ , x ( k ) ] X=\left[\mathbf{x}^{(0)}, \mathbf{x}^{(1)}, \cdots, \mathbf{x}^{(k)}\right] X=[x(0),x(1),⋯,x(k)],其中 x ( p ) = [ x a ( p ) , x t ( p ) ] \mathbf{x}^{(p)} = [\mathbf{x}_a^{(p)}, \mathbf{x}_t^{(p)}] x(p)=[xa(p),xt(p)], x a ( p ) \mathbf{x}_a^{(p)} xa(p)表示在时间 p p p时访问到的结点的特征, x t ( p ) \mathbf{x}_t^{(p)} xt(p)表示访问到该结点时的时间向量。注意,如果访问到了已经访问过的结点则 x t ( p ) \mathbf{x}_t^{(p)} xt(p)为最早访问时的时间。在论文中, x t ( p ) \mathbf{x}_t^{(p)} xt(p)采用one-hot编码。
3.2 Encoding
将每一个采样到的子图编码为向量。直觉上,如果子图的表征质量好,那么就能在子图表征地基础上较好地重建子图。论文中作者采样自编码器学习子图的表征,以重建损失作为损失函数。至此, s s s个子图 { X 1 , . . . , X s } \{X_1, ..., X_s\} {X1,...,Xs}被表示为 s s s个向量 { z 1 , . . . , z s } \{\mathbf{z}_1, ..., \mathbf{z}_s\} {z1,...,zs}。
3.3 Embedding Distribution
将上一阶段获得的多个子图的表征汇集作为输入图的表征。对于两个图,它们在表征空间中的距离应该与它们的子图向量分布距离类似,因此需要找到一个好的聚集函数来保留原先的子图表征分布距离,论文中采用的是 M M D MMD MMD。
给定连个图 G , H \mathcal{G}, \mathcal{H} G,H,子图表征分别为: { z 1 , . . . , z s } \{\mathbf{z}_1, ..., \mathbf{z}_s\} {z1,...,zs}和 { h 1 , . . . , h s } \{\mathbf{h}_1, ..., \mathbf{h}_s\} {h1,...,hs},则两者间的 M M D MMD MMD为:
M M D ^ ( P G , P H ) = 1 s ( s − 1 ) ∑ i = 1 s ∑ j ≠ i s k ( z i , z j ) + 1 s ( s − 1 ) ∑ i = 1 s ∑ j ≠ i s k ( h i , h j ) − 2 s 2 ∑ i = 1 s ∑ j = 1 s k ( z i , h j ) = ∥ μ ^ G − μ ^ H ∥ 2 2 \begin{aligned} \widehat{M M D}\left(P_{\mathcal{G}}, P_{\mathcal{H}}\right)=& \frac{1}{s(s-1)} \sum_{i=1}^{s} \sum_{j \neq i}^{s} k\left(\mathbf{z}_{i}, \mathbf{z}_{j}\right)+\frac{1}{s(s-1)} \sum_{i=1}^{s} \sum_{j \neq i}^{s} k\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right) \\ &-\frac{2}{s^{2}} \sum_{i=1}^{s} \sum_{j=1}^{s} k\left(\mathbf{z}_{i}, \mathbf{h}_{j}\right) \\ =&\left\|\hat{\mu}_{\mathcal{G}}-\hat{\mu}_{\mathcal{H}}\right\|_{2}^{2} \end{aligned} MMD (PG,PH)==s(s−1)1i=1∑sj=i∑sk(zi,zj)+s(s−1)1i=1∑sj=i∑sk(hi,hj)−s22i=1∑sj=1∑sk(zi,hj)∥μ^G−μ^H∥22
μ ^ G , μ ^ H \hat{\mu}_{\mathcal{G}}, \hat{\mu}_{\mathcal{H}} μ^G,μ^H分别表示两个图的kernel embedding,也就是最终的graph representation,分别定义为:
μ ^ G = 1 s ∑ i = 1 s ϕ ( z i ) , μ ^ H = 1 s ∑ i = 1 s ϕ ( h i ) \hat{\mu}_{\mathcal{G}}=\frac{1}{s} \sum_{i=1}^{s} \phi\left(\mathbf{z}_{i}\right), \quad \hat{\mu}_{\mathcal{H}}=\frac{1}{s} \sum_{i=1}^{s} \phi\left(\mathbf{h}_{i}\right) μ^G=s1i=1∑sϕ(zi),μ^H=s1i=1∑sϕ(hi)
其中 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)是与核函数 k ( ⋅ , ⋅ ) k(\cdot, \cdot) k(⋅,⋅)相关的特征映射函数(与SVM中的核技巧类似,将核函数的计算转化为更简单的计算形式)。
根据核函数的选择, ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)具有不同的形式,如RBF、MLP等。为了训练 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅),文中使用如下的近似误差,其中 θ m \theta_m θm为 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)的参数):
J ( θ m ) = ∥ D ( P G , P H ) − M M D ^ ( P G , P H ) ∥ 2 2 J\left(\theta_{m}\right)=\left\|D\left(P_{\mathcal{G}}, P_{\mathcal{H}}\right)-\widehat{M M D}\left(P_{\mathcal{G}}, P_{\mathcal{H}}\right)\right\|_{2}^{2} J(θm)=∥∥∥D(PG,PH)−MMD (PG,PH)∥∥∥22
通过最小化上述误差,就能学习到较好的聚集函数,在最终的表征中保留子图表征的分布距离。
该论文的方法与核方法有一定的相似性。论文还证明了同构的图的WEAVE的子图分布是类似的,并且对子图的采样长度进行了证明,详细内容可以参考论文。
4 方法的优势与局限性
4.1 优势
- 给出了无监督形式的、inductive的图结构对象表征学习方法
- 避免了复杂的图相似性计算,以类似于核技巧的方法较好地度量了图之间地距离
- 对相关地定理进行了证明
4.2 局限性
- 当图地规模较大时,采样的子图也会非常大,且可能需要采样地子图数量会很大
欢迎访问我的个人博客~~~
这篇关于Inductive and Unsupervised Representation Learning on Graph Structured Objects的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







