structured专题

Structured Streaming | Apache Spark中处理实时数据的声明式API
关于Spark的相关文章在这里: 《Spark面对OOM问题的解决方法及优化总结》 《Spark 动态资源分配(Dynamic Resource Allocation) 解析》 《Apache Spark在海致大数据平台中的优化实践》 《Spark/Flink广播实现作业配置动态更新》 《Spark SQL读数据库时不支持某些数据类型的问题》 《阿里云Spark Shuffle的优化》 《Spa

打通实时流处理log4j-flume-kafka-structured-streaming
大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 模拟产生log4j日志 jar包依赖 pom.xml 12345678910111213<dependency><groupId>log4j</groupId><artifactId>log4j</artifactId></dependency><depe

LSM树(Log-Structured Merge Tree)存储引擎
LSM树(Log-Structured Merge Tree)存储引擎 代表数据库:nessDB、leveldb、hbase等 核心思想的核心就是放弃部分读能力,换取写入的最大化能力。LSM Tree ,这个概念就是结构化合并树的意思,它的核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在磁盘中,等到积累到最后多之后,再

【博客718】时序数据库基石:LSM Tree(log-structured merge-tree)
时序数据库基石:LSM Tree(log-structured merge-tree) 1、为什么需要LSM Tree LSM被设计来提供比传统的B+树更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标,使得写入都是顺序写,而不是随机写。 那么为什么这是一个好的方法呢?这个问题的本质还是磁盘随机操作慢,顺序读写快的老问题。这二种操作存在巨大的差距,无论是磁盘还是SSD。 2、LSM

Bigtable: A Distributed Storage System for Structured Data
2003年USENIX,出自谷歌,开启分布式大数据时代的三篇论文之一,底层依赖 GFS 存储,上层供 MapReduce 查询使用 Abstract 是一种分布式结构化数据存储管理系统,存储量级是PB级别。存储的数据类型和延时要求差异都很大。论文介绍数 bigtable 的数据模型。 Introduction BigTable 达成了几个目标:适用面广、伸缩性好、高性能、高可用。即可以满足

C++备忘录003:自定义类型实现structured binding
需要实现 tuple_size<type>返回长度tuple_element<index, type>返回index位置上的类型get<index>返回index位置上的值 #include <iostream>#include <string>#include <utility>class person_t {public:template <typename T1, typename

C++备忘录002:Structured Binding, 会生成临时变量,可能有昂贵的拷贝
auto [u, v] = s相当于如下代码 auto e = s;alias u = e.member1;alias v = e.member2; 注意,此时临时变量e是个拷贝,u和v相当于别名 int main() { struct Y {int a;std::string b;};auto y = Y{10, "h
![[论文阅读笔记31]Mamba (Selective Structured State Space Model) 及其应用](https://img-blog.csdnimg.cn/direct/b270c0fb2e0148e09188c58e74ebc44a.png)
[论文阅读笔记31]Mamba (Selective Structured State Space Model) 及其应用
最近想学一下Mamba模型,奈何看了很多视频还是感觉一知半解,因此做一篇笔记,顺便介绍一下Mamba结构作为CV backbone和时间序列预测领域的应用。 论文1. Mamba: Linear-Time Sequence Modeling with Selective State Spaces 0. Abstract 现有的基础模型都是以Transformer结构作为核心组建的。然

Spark Structured Streaming + Kafka使用笔记
这篇博客将会记录Structured Streaming + Kafka的一些基本使用(Java 版) 1. 概述 Structured Streaming (结构化流)是一种基于 Spark SQL 引擎构建的可扩展且容错的 stream processing engine (流处理引擎)。可以使用Dataset/DataFrame API 来表示 streaming aggregation
structured streaming的checkpoint文件无限增长
目录 structured streaming的checkpoint文件无限增长 structured streaming的checkpoint文件无限增长 原理和处理办法: https://www.waitingforcode.com/apache-spark-structured-streaming/checkpoint-storage-structured-streamin
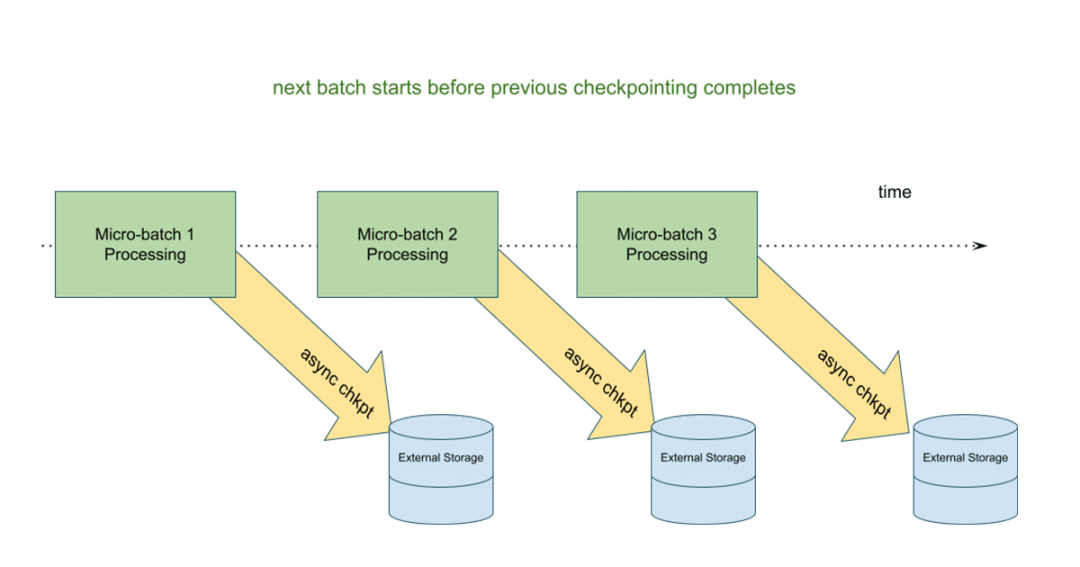
Spark Structured Streaming 2021年最新进展的总结
本文我们将花点时间来回顾一下 Databricks 和 Apache Spark™ 在流数据处理方面所取得的巨大进步!2021年,工程团队和开源贡献者在以下三个目标取得了一些进展: •降低延迟并改进有状态流处理;•提高 Databricks 和 Spark Structured Streaming 工作负载的可观测性;•改进资源分配和可伸缩性。 下面我们来简单地看下这些目标。 目标一:降低延迟并
大数据-玩转数据-Spark-Structured Streaming 监控(python版)
大数据-玩转数据-Spark-Structured Streaming 监控(python版) 查询时返回的StreamingQuery() 对象可以对查询进行监控,对象包括recentProgress,lastProgress,status等多个属性。 代码举例 #!/usr/bin/env python3from pprint import pprintimport timefrom p
大数据-玩转数据-Spark-Structured Streaming 容错(python版)
大数据-玩转数据-Spark-Structured Streaming 容错(python版) 说明: 由于网络问题,链路中断,系统崩溃,JVM故障都会导致数据流的运行结果出现错误,Spark设计了输入源,执行引擎和接收器多个松散耦合组件隔离故障。 输入源通过位置偏移量来记录目前所处位置,引擎通过检查点保存中间状态,接收器使用“幂等”的接收器来保障输出的稳定性。 我们希望数据是它产生的时间,
大数据-玩转数据-Spark-Structured Streaming 输出操作(python版)
大数据-玩转数据-Spark-Structured Streaming 输出操作(python版) 1、说明 Structured Streaming流计算过程定义的DataFrame/Dataset结果,通过writeStream()方法写入到输出接收器,接收器对应关系如下: 接收器支持输出模式File接收器AppendKafka接收器Append、Complete、UpdateForeac

大数据-玩转数据-Spark-Structured Streaming 简述及编程初步(python版)
大数据-玩转数据-Spark-Structured Streaming 简述及编程初步(python版) 一、简述: Structured Streaming 是基于Spark SQL引擎构建的、可扩展且容错性高的流处理引擎。它以检查点和预写日志记录每个触发时间正处理数据的偏移范围,保证端到端数据的一致性。Spark2.3.0版本引入持续流失处理模型后,可将数据延迟降低到毫秒级。Structur

从spark streaming与structured streaming看spark core与spark sql的区别
导读 Spark中针对流式数据处理的方案有: Spark StreamingStructured Streaming 本文通过对比spark streaming与structured streaming,来深入理解spark core与spark sql的区别。 Spark Streaming 基于微批(DStream) Spark Streaming是基于微批(Micro batc
带你从Spark官网啃透Spark Structured Streaming
By 远方时光原创,可转载,open 合作微信公众号:大数据左右手 本文是基于spark官网结构化流解读 Structured Streaming Programming Guide - Spark 3.5.1 Documentation (apache.org) spark官网对结构化流解释 我浓缩了一些关键信息: 1.结构化流是基于SparkSQL引擎构建的可扩展且容错
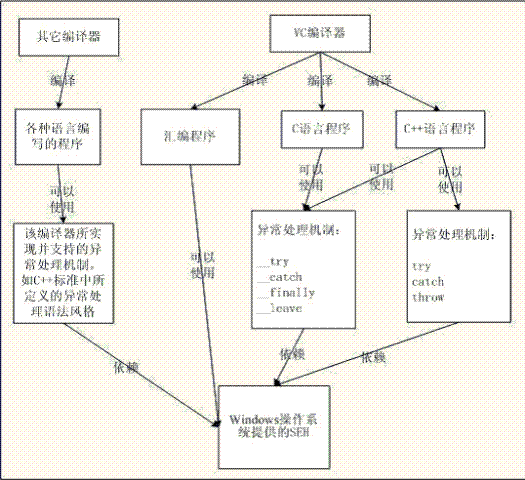
SEH(structured exception handling)中__try __except异常处理模型
SEH(structured exception handling)中__try __except异常处理模型 一、SEH 的工作原理 Windows 程序设计中最重要的理念就是消息传递,事件驱动。当GUI应用程序触发一个消息时,系统将把该消息放入消息队列,然后去查找并调用窗体的消息处理函数(CALLBACK),传递的参数当然就是这个消息。我们同样可以把异常也当作是一种消息,应用程序发生异常时就
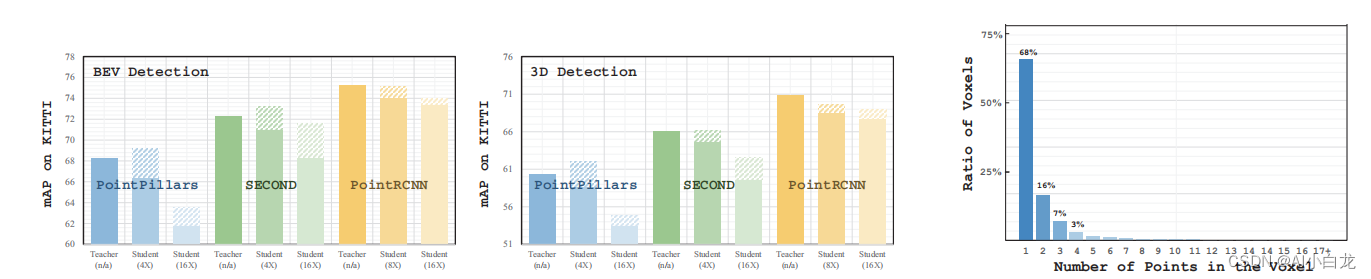
【蒸馏】PointDistiller: Structured Knowledge DistillationTowards Efficient and Compact 3D Detection
简述 方法的细节。fT和f S:教师检测器和学生检测器中的特征编码层。AT和AS:抽取的待蒸馏体素或重要性得分最高的点的特征。CT和CS:教师和学生检测特征的通道数。GT和GS:教师和学生检测器的图形特征。该方法基于预先定义的重要度评分,从整个点云中抽取比较关键的N个体素或点,通过动态图卷积提取它们的局部几何结构,然后对其进行加权提取。 局部蒸馏 最近的大量研究表明,获取和利用点云
Spark编程实验五:Spark Structured Streaming编程
目录 一、目的与要求 二、实验内容 三、实验步骤 1、Syslog介绍 2、通过Socket传送Syslog到Spark 3、Syslog日志拆分为DateFrame 4、对Syslog进行查询 四、结果分析与实验体会 一、目的与要求 1、通过实验掌握Structured Streaming的基本编程方法; 2、掌握日志分析的常规操作,包括拆分日志方法和分析场景。 二
TPGR代码详解 Large-Scale Interactive Recommendation with Tree-Structured Policy Gradient
论文阅读笔记链接 github代码链接 目录 论文内容MDP过程训练TPGR过程:采样过程 结构讲解DEBUG过程代码详解整体流程run函数1. PRE_TRAIN()init()make_graph()train()evaluate 一些问题记录参数相关 2. Tree()init()construct_tree()build_mapping()hierarchical_code()pc

Iceberg从入门到精通系列之二十四:Spark Structured Streaming
Iceberg从入门到精通系列之二十四:Spark Structured Streaming 一、Streaming Reads二、Streaming Writes三、Partitioned table四、流表的维护 Iceberg 使用 Apache Spark 的 DataSourceV2 API 来实现数据源和目录。 Spark DSv2 是一个不断发展的 API,在 Spa
Structured Streaming基础--学习笔记
Structured streaming介绍 spark进行实时数据流计算时有两个工具: Spark Streaming:编写rdd代码处理数据流,可以解决非结构化的流式数据Structured Streaming:编写df代码处理数据流,可以解决结构化和半结构化的流式数据 1,数据相关介绍 有界数据和无界数据 ①有界数据: 有起始位置,有结束位置。比如文件数据 有起始行,有结束行有
数据库——SQL语句(Structured query Language)
sql查询 查询:Select 【predicate】字段列表 from 表的列表(可以是多个表) 注:predicate的选取:1.all,返回所有满足条件的记录 2.Distinct,返回不同的记录

【长文阅读】MAMBA作者博士论文<MODELING SEQUENCES WITH STRUCTURED STATE SPACES>-Chapter2
Gu A. Modeling Sequences with Structured State Spaces[D]. Stanford University, 2023. 本文是MAMBA作者的博士毕业论文,为了理清楚MAMBA专门花时间拜读这篇长达330页的博士论文,由于知识水平有限,只能尽自己所能概述记录,并适当补充一些相关数学背景,欢迎探讨与批评指正。内容多,分章节更新以免凌乱。 Chap

【论文阅读】GPT4Graph: Can Large Language Models Understand Graph Structured Data?
文章目录 0、基本介绍1、研究动机2、准备2.1、图挖掘任务2.2、图描述语言(GDL) 3、使用LLM进行图理解流程3.1、手动提示3.2、自提示 4、图理解基准4.1、结构理解任务4.1、语义理解任务 5、数据搜集5.1、结构理解任务5.2、语义理解任务 6、实验6.1、实验设置6.2、结构理解任务的结果6.2.1、输入设计对最终结果有重要影响。6.2.2、角色转换通常会提高绩效6.2.