本文主要是介绍【蒸馏】PointDistiller: Structured Knowledge DistillationTowards Efficient and Compact 3D Detection,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简述
方法的细节。fT和f S:教师检测器和学生检测器中的特征编码层。AT和AS:抽取的待蒸馏体素或重要性得分最高的点的特征。CT和CS:教师和学生检测特征的通道数。GT和GS:教师和学生检测器的图形特征。该方法基于预先定义的重要度评分,从整个点云中抽取比较关键的N个体素或点,通过动态图卷积提取它们的局部几何结构,然后对其进行加权提取。
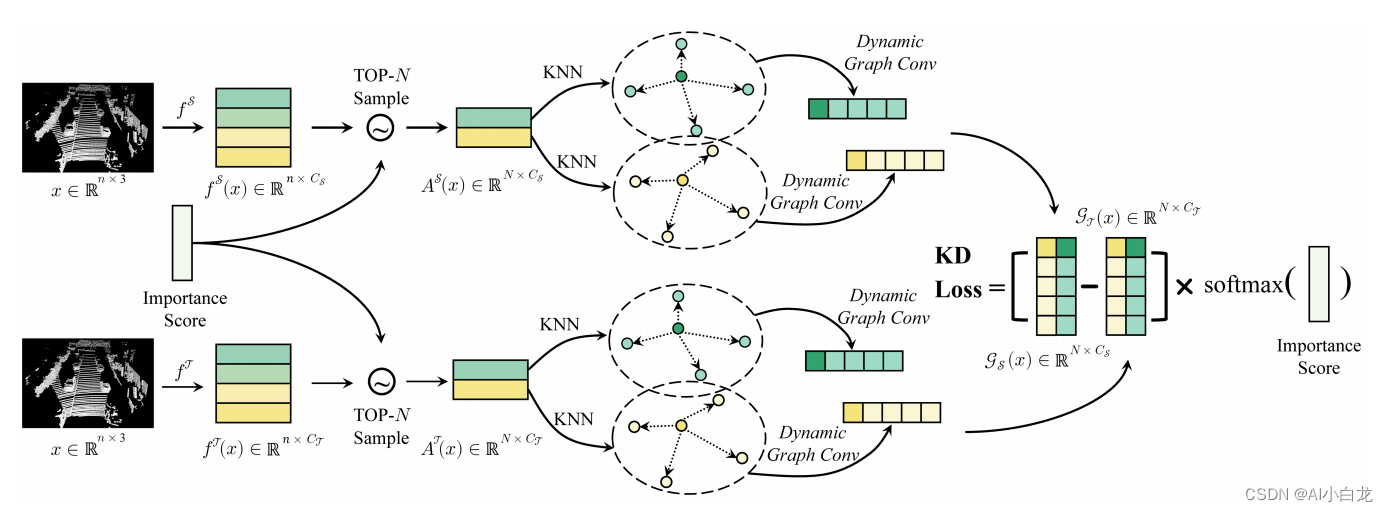
局部蒸馏
最近的大量研究表明,获取和利用点云局部几何结构中的语义信息对点云表示学习有着至关重要的影响。因此,我们提出局部蒸馏的方法,并不是直接将教师检测器的主干特征提取为学生检测器,而是先用KNN (k近邻)聚类局部邻近体素或点,然后用动态图卷积层将语义信息编码到局部几何结构中[63],最后从老师到学生中提炼出来。因此,学生检测器可以继承教师对点云局部几何信息的理解能力,实现更好的检测性能。
加权学习策略
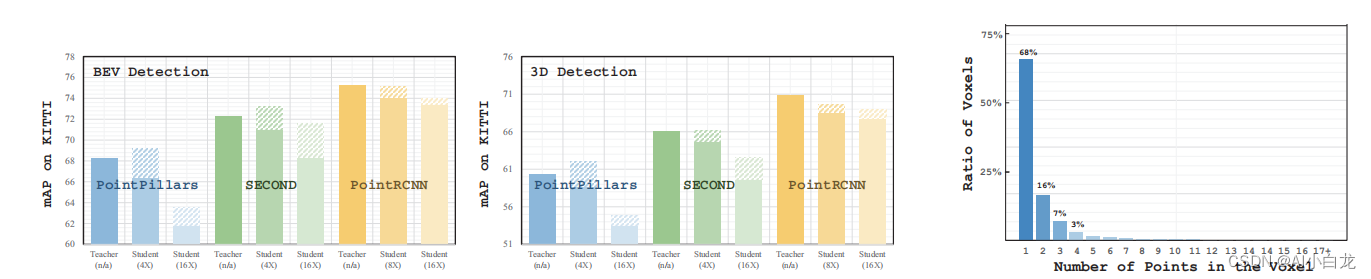
处理点云的主流方法之一是将它们转换为体积体素,然后将它们编码为常规数据。然而,由于点云的稀疏性和噪声,这些体素大多只包含单个点。例如,如图2所示,在KITTI数据集上,点云中大约68%的体素只包含一个点,这个点极有可能是噪声点。因此,与包含多个点的体素相比,这些单点体素中的代表性特征在知识提取中的重要性相对较低。基于这一观察,我们提出了一种重新加权的学习策略,该策略通过给予学生更大的学习权重来突出学生在具有多个点的体素上的学习。此外,类似的想法也可以很容易地推广到原始的基于分数的检测器上,突出对教师检测器的预测影响更大的点上的知识蒸馏。
在基于体素和基于原始点的检测器上进行了广泛的实验,以证明我们的方法比之前的7种知识蒸馏方法的有效性。如图1所示,在PointPillars和SECOND检测器上,我们的方法同时实现了4倍的压缩和0.9 ~ 1.8 mAP的改进。在PointRCNN上,我们的方法导致8×压缩,只有0.2 BEV mAP下降。我们的主要贡献总结如下。
(1)我们提出了局部精馏的方法,首先利用动态图卷积对点云的局部几何结构进行编码,然后从教师到学生之间进行精馏。
(2)我们提出重新加权学习策略来处理点云的稀疏性和噪声。它强调学生在体素上的学习,体素内部有更多的点,通过在知识蒸馏中给予他们更高的学习权重。
(3)在基于体素和基于原始点的探测器上进行了广泛的实验,以证明我们的方法的性能超过7个以前的方法。
https://arxiv.org/abs/2205.11098
这篇关于【蒸馏】PointDistiller: Structured Knowledge DistillationTowards Efficient and Compact 3D Detection的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]QLoRA: Efficient Finetuning of Quantized LLMs](https://img-blog.csdnimg.cn/img_convert/e75c9a4137c39630cd34c5ebe3fe8196.png)
