本文主要是介绍Spark Structured Streaming 2021年最新进展的总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文我们将花点时间来回顾一下 Databricks 和 Apache Spark™ 在流数据处理方面所取得的巨大进步!2021年,工程团队和开源贡献者在以下三个目标取得了一些进展:
•降低延迟并改进有状态流处理;•提高 Databricks 和 Spark Structured Streaming 工作负载的可观测性;•改进资源分配和可伸缩性。
下面我们来简单地看下这些目标。
目标一:降低延迟并改进有状态流处理
有两个新的关键特性专门用于降低有状态操作的延迟,以及对有状态 APIs 的改进。第一种是针对大型有状态操作的异步检查点(asynchronous checkpointing),它改进了传统的同步和延迟更高的设计。
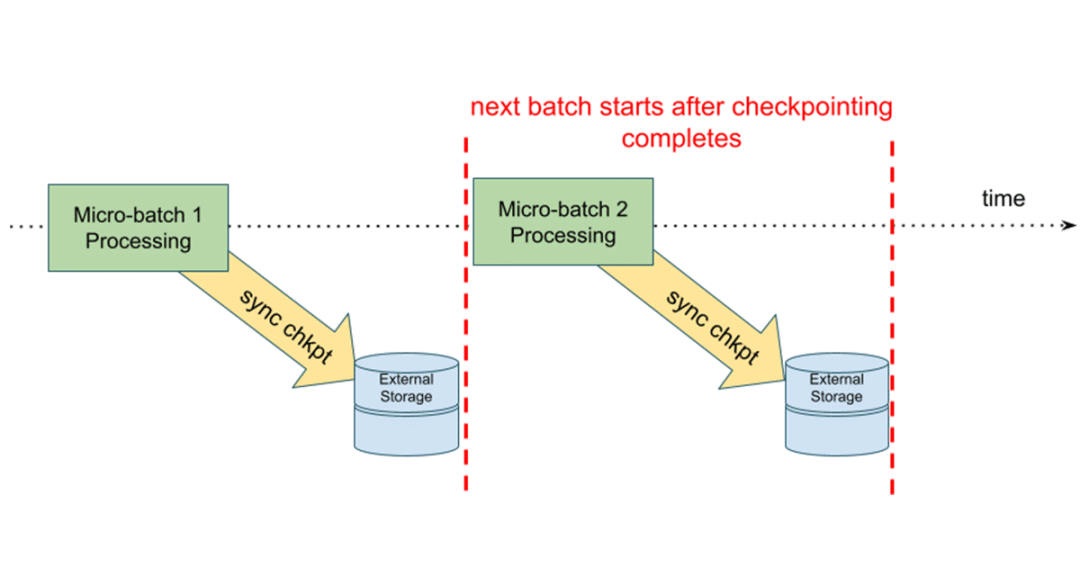
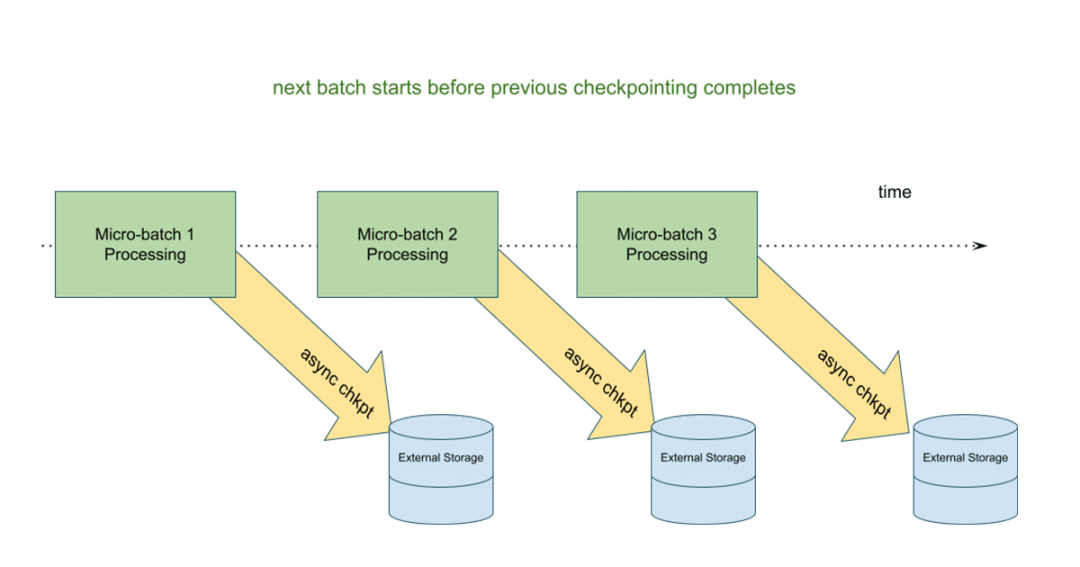
异步检查点
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
在这个模型中,状态更新会在下一个微批开始之前写到云存储检查点位置。这样做的好处是,如果有状态流查询失败,我们可以使用最后一个成功完成的批处理中的信息轻松地重新启动查询。在异步模型中,下一个微批不必等待状态更新,从而提高了整个微批执行的端到端延迟。
 如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:过往记忆大数据
任意状态操作符的改进
在这篇文章中,社区用 [flat]MapGroupsWithState 在结构化流中引入了任意状态处理。这些操作符提供了很大的灵活性,并支持聚合之外的更高级的有状态操作。在过去的一年,社区已经对这些操作符进行了改进:
允许初始状态,避免重新处理所有流数据;通过公开一个新的 TestGroupState 接口,允许用户创建 GroupState 的实例,并访问已设置的内部值,简化状态转换函数的单元测试,从而实现更简单的逻辑测试。
允许初始状态
让我们从下面的 flatMapGroupswithState 操作符开始:
def flatMapGroupsWithState[S: Encoder, U: Encoder](outputMode: OutputMode,timeoutConf: GroupStateTimeout,initialState: KeyValueGroupedDataset[K, S])(func: (K, Iterator[V], GroupState[S]) => Iterator[U])下面的例子计算每种水果的总数:
val fruitCountFunc =(key: String, values: Iterator[String], state: GroupState[RunningCount]) => {val count = state.getOption.map(_.count).getOrElse(0L) + valList.sizestate.update(new RunningCount(count))Iterator((key, count.toString))
}现在,我们针对某些水果的计数设置初始值:
val fruitCountInitialDS: Dataset[(String, RunningCount)] = Seq(("apple", new RunningCount(1)),("orange", new RunningCount(2)),("mango", new RunningCount(5)),
).toDS()
val fruitCountInitial = initialState.groupByKey(x => x._1).mapValues(_._2)
fruitStream.groupByKey(x => x).flatMapGroupsWithState(Update, GroupStateTimeout.NoTimeout, fruitCountInitial)(fruitCountFunc)简单的逻辑测试
您现在还可以使用 TestGroupState API 测试状态更新。
import org.apache.spark.sql.streaming._
import org.apache.spark.api.java.Optional
test("flatMapGroupsWithState's state update function") {var prevState = TestGroupState.create[UserStatus](optionalState = Optional.empty[UserStatus],timeoutConf = GroupStateTimeout.EventTimeTimeout,batchProcessingTimeMs = 1L,eventTimeWatermarkMs = Optional.of(1L),hasTimedOut = false)val userId: String = ...val actions: Iterator[UserAction] = ...assert(!prevState.hasUpdated)updateState(userId, actions, prevState)assert(prevState.hasUpdated)
}关于 TestGroupState 的更多例子可以参见这里。
内置支持会话窗口(Session Windows)
Structured Streaming 引入了在基于事件时间的窗口上使用滚动或滑动窗口进行聚合的能力,这两种窗口都是固定长度的窗口。在 Spark 3.2 中,社区引入了会话窗口的概念,它允许动态窗口长度。这需要使用 flatMapGroupsWithState 自定义状态操作符。我们可以看下下面的例子:
# Define the session window having dynamic gap duration based on eventType
session_window expr = session_window(events.timestamp, \when(events.eventType == "type1", "5 seconds") \.when(events.eventType == "type2", "20 seconds") \.otherwise("5 minutes"))
# Group the data by session window and userId, and compute the count of each group
windowedCountsDF = events \.withWatermark("timestamp", "10 minutes") \.groupBy(events.userID, session_window_expr) \.count()关于会话窗口的介绍可以参见 Apache Spark 3.2 内置支持会话窗口。
目标二:提高 Databricks 和 Spark Structured Streaming 工作负载的可观测性
虽然 StreamingQueryListener API 允许我们在 SparkSession 中异步监视查询,并为查询状态、进度和终止事件定义自定义回调函数,但理解反压(understanding back pressure)和推断瓶颈在微批处理中的位置仍然是一个挑战。从 Databricks Runtime 8.1 开始,StreamingQueryProgress 对象报告了 Kafka、Kinesis、Delta Lake 和 Auto Loader 流数据源的特定数据源背压指标(back pressure metrics)。
比如下面是 Kafka 数据源的 metrics 例子:
{"sources" : [ {"description" : "KafkaV2[Subscribe[topic]]","metrics" : {"avgOffsetsBehindLatest" : "4.0","maxOffsetsBehindLatest" : "4","minOffsetsBehindLatest" : "4","estimatedTotalBytesBehindLatest" : "80.0"},} ]
}关于上面新增指标可以参见 SPARK-34854。注意,社区版好像没有 estimatedTotalBytesBehindLatest 指标。
另外,Databricks Runtime 8.3 引入了实时指标,以帮助理解 RocksDB 状态存储的性能,调试状态操作的性能;这些还可以帮助识别异步检查点的目标工作负载。一个新的状态存储监控的例子如下:
{"id" : "6774075e-8869-454b-ad51-513be86cfd43","runId" : "3d08104d-d1d4-4d1a-b21e-0b2e1fb871c5","batchId" : 7,"stateOperators" : [ {"numRowsTotal" : 20000000,"numRowsUpdated" : 20000000,"memoryUsedBytes" : 31005397,"numRowsDroppedByWatermark" : 0,"customMetrics" : {"rocksdbBytesCopied" : 141037747,"rocksdbCommitCheckpointLatency" : 2,"rocksdbCommitCompactLatency" : 22061,"rocksdbCommitFileSyncLatencyMs" : 1710,"rocksdbCommitFlushLatency" : 19032,"rocksdbCommitPauseLatency" : 0,"rocksdbCommitWriteBatchLatency" : 56155,"rocksdbFilesCopied" : 2,"rocksdbFilesReused" : 0,"rocksdbGetCount" : 40000000,"rocksdbGetLatency" : 21834,"rocksdbPutCount" : 1,"rocksdbPutLatency" : 56155599000,"rocksdbReadBlockCacheHitCount" : 1988,"rocksdbReadBlockCacheMissCount" : 40341617,"rocksdbSstFileSize" : 141037747,"rocksdbTotalBytesReadByCompaction" : 336853375,"rocksdbTotalBytesReadByGet" : 680000000,"rocksdbTotalBytesReadThroughIterator" : 0,"rocksdbTotalBytesWrittenByCompaction" : 141037747,"rocksdbTotalBytesWrittenByPut" : 740000012,"rocksdbTotalCompactionLatencyMs" : 21949695000,"rocksdbWriterStallLatencyMs" : 0,"rocksdbZipFileBytesUncompressed" : 7038}} ],"sources" : [ {} ],"sink" : {}
}关于这个功能可以参见 SPARK-36236。
目标三:改进资源分配和可伸缩性
Streaming Autoscaling Delta Live Tables (DLT)
在去年的 Data + AI Summit 峰会上,数砖发布了 Delta Live Tables,这是一个框架,允许我们声明式地构建和编排数据管道,并在很大程度上抽象了配置集群和节点类型的需求。在过去的一边这个功能得以提升,并为流管道引入了一个智能自动伸缩解决方案,该解决方案改进了现有的 Databricks 优化自动伸缩(Databricks Optimized Autoscaling)。这些好处包括:
•更好地利用集群:新的算法利用新的背压度量(back pressure metrics)来调整集群大小,以更好地处理流工作负载波动的场景,这最终导致更好的集群利用率。•主动优雅的 Worker 关闭:现有的自动伸缩解决方案只有在节点空闲时才会关闭节点,而新的 DLT Autoscaler 会在利用率低时主动关闭选定的节点,同时保证不会因为关闭而导致任务失败。
Trigger.AvailableNow
在 Structured Streaming 中,触发器允许用户定义流查询数据处理的时间。这些触发器类型可以是 micro-batch (默认)、fixed interval micro-batch (Trigger.ProcessingTime)、one-time micro-batch (Trigger.Once)和 continuous (Trigger.Continuous)。
Databricks Runtime 10.1 (对应社区的 Spark 3.3.0 版本,参见 SPARK-36533)引入了一种新的触发器:Trigger.AvailableNow,类似于 Trigger.Once ,但提供了更好的可伸缩性。与 Trigger Once 一样,所有可用的数据都将在查询停止之前处理,但是是以多批处理的方法来处理而不是一次处理所有的数据,这有可能会导致 Driver 出现 OOM。这个功能支持 Delta Lake 、Auto Loader 以及 Kafka(SPARK-36649)流数据源。下面是一个使用例子:
spark.readStream.format("delta").option("maxFilesPerTrigger", "1").load(inputDir).writeStream.trigger(Trigger.AvailableNow).option("checkpointLocation", checkpointDir).start()本文翻译自《Structured Streaming: A Year in Review》https://databricks.com/blog/2022/02/07/structured-streaming-a-year-in-review.html。
这篇关于Spark Structured Streaming 2021年最新进展的总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





