streaming专题

周期性清除Spark Streaming流状态的方法
在Spark Streaming程序中,我们经常需要使用有状态的流来统计一些累积性的指标,比如各个商品的PV。简单的代码描述如下,使用mapWithState()算子: 现在的问题是,PV并不是一直累加的,而是每天归零,重新统计数据。要达到在凌晨0点清除状态的目的,有以下两种方法。 编写脚本重启Streaming程序 用crontab、Azkaban等在凌晨0点调度执行下面的Shell脚本

Structured Streaming | Apache Spark中处理实时数据的声明式API
关于Spark的相关文章在这里: 《Spark面对OOM问题的解决方法及优化总结》 《Spark 动态资源分配(Dynamic Resource Allocation) 解析》 《Apache Spark在海致大数据平台中的优化实践》 《Spark/Flink广播实现作业配置动态更新》 《Spark SQL读数据库时不支持某些数据类型的问题》 《阿里云Spark Shuffle的优化》 《Spa

打通实时流处理log4j-flume-kafka-structured-streaming
大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 模拟产生log4j日志 jar包依赖 pom.xml 12345678910111213<dependency><groupId>log4j</groupId><artifactId>log4j</artifactId></dependency><depe
Spark Streaming整合log4j、Flume与Kafka的案例
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 来源:作者TAI_SPARK,http://suo.im/5w7LF8 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 1.框架 2.log4j完成模拟日志输出 设置模拟日志格式,log4j.properties: log4j.rootLogger = INFO,stdo

How to apply streaming in azure openai dotnet web application?
题意:"如何在 Azure OpenAI 的 .NET Web 应用程序中应用流式处理?" 问题背景: I want to create a web api backend that stream openai completion responses. "我想创建一个 Web API 后端,用于流式传输 OpenAI 的完成响应。" How can I apply the f

Spark实战(五)spark streaming + flume(Python版)
一、flume安装 (一)概述 Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外部存储系统中,一般的采集需求,通过对flume的简单配置即可实现,Flume针对特殊场景也具备良好的自定义扩展能力,因此flume可以适用于大部分的日

using showdown js with openAi streaming response
题意:"使用 Showdown.js 处理 OpenAI 流式响应" 问题背景: I tried using showdownjs to translate streamed markdown from OpenAi to HTML "我尝试使用 Showdown.js 将来自 OpenAI 的流式 Markdown 转换为 HTML" I changed the code g

spark从入门到放弃五十四:Spark Streaming(14)checkpoint
1.概述 每一个spark streaming 应用正常来说都要7*24小时运转的,这就是实时计算程序的特点。因为要持续不断的对数据进行计算。因此,对实时计算的要求,应该是必须能够与应用程序逻辑无关的失败,进行容错。 如果要实现这个目标,spark streaming 程序就必须将足够的信息checkpoint 到容错的存储系统上,从而让他能够从失败中进行恢复。有两种数据需要进行checkpo

spark从入门到放弃五十三:Spark Streaming(13)缓存于持久化
与RDD 类似,spark Streaming 也可以让开发人员手动控制,将数据流中的数据持久化到内存中。对DStream 调用persist ( ) 方法,就可以让spark Streaming 自动将该数据流中的所有产生的RDD 都持久化到内存中。如果要对于一个DStream 多次执行操作,那么对DStream 持久化是非常有用的。因为多次操作,可以共享一份数据。 对于基于窗口的操作,例如re
spark从入门到放弃五十二:Spark Streaming(12)结合spark Sql
文章地址:http://www.haha174.top/article/details/253627 1.简介 Spark Streaming 强大的地方在于,可以于spark core 和spark sql 整合使用,之前已经通过transform foreachRDD 等算子看到了 如何将DStream 种的RDD 使用spark core 执行批处理操作。现在就来看看 如何将spark s

任务5.1 初识Spark Streaming
实战概述:使用Spark Streaming进行词频统计 1. 项目背景与目标 背景: Spark Streaming是Apache Spark的流处理框架,用于构建可伸缩、高吞吐量的实时数据处理应用。目标: 实现一个实时词频统计系统,能够处理流式数据并统计文本中的单词出现频率。 2. 技术要点 Spark Streaming集成: 与Spark生态的其他组件如Spark SQL、ML

Spark Streaming(七)—— Spark Streaming性能优化
文章目录 1. 减少批数据的执行时间2. 设置合理的批容量3. 内存调优 1. 减少批数据的执行时间 在Spark中有几个优化可以减少批处理的时间: ① 数据接收的并行水平 通过网络(如Kafka,Flume,Socket等)接收数据需要这些数据反序列化并被保存到Spark中。如果数据接收成为系统的瓶颈,就要考虑并行地接收数据。注意,每个输入DStream创建一个Receiver
Spark Streaming(六)—— 检查点
文章目录 1. 一般会对两种类型的数据使用检查点2. 何时启用检查点3. 如何配置检查点4. 改写之前的WordCount程序 流数据处理程序通常都是全天候运行,因此必须对应用中逻辑无关的故障(例如,系统故障,JVM崩溃等)具有弹性。为了实现这一特性,Spark Streaming需要checkpoint足够的信息到容错存储系统,以便可以从故障中恢复。 1. 一般会对两种类型的

Spark Streaming(五)—— Spark Streaming缓存/持久化
与RDD类似,DStreams还允许开发人员将流数据保留在内存中。也就是说,在DStream上调用persist() 方法会自动将该DStream的每个RDD保留在内存中。如果DStream中的数据将被多次计算(例如,相同数据上执行多个操作),这个操作就会很有用。 对于基于窗口的操作,如reduceByWindow和reduceByKeyAndWindow以及基于状态的操作,如updateSta

Spark Streaming(四)—— Spark Streaming输出
输出操作允许DStream的操作推到如数据库、文件系统等外部系统中。目前,定义了下面几种输出操作: 使用Spark SQL来查询Spark Streaming处理的数据: import org.apache.log4j.Loggerimport org.apache.log4j.Levelimport org.apache.spark.SparkConfimport org.apache
Spark Streaming(三)—— 高级数据源Flume
文章目录 高级数据源Flume1. Push方式2. 基于Custom Sink的Pull模式 高级数据源Flume Spark Streaming 是一个流式计算引擎,就需要对接外部数据源来对接、接收数据。每一个输入流DStream和一个Receiver对象相关联,这个Receiver从源中获取数据,并将数据存入内存中用于处理。Spark Streaming的基本数据源(文件

Spark Streaming(二)—— Spark Streaming基本数据源
文章目录 基本数据源1. 文件流(textFileStream)2. RDD队列流(queueStream,队列里是RDD)3. 套接字流(socketTextStream) 基本数据源 Spark Streaming 是一个流式计算引擎,就需要对接外部数据源来接收数据。每一个输入流DStream和一个Receiver对象相关联,这个Receiver从源中获取数据,并将数据存入

Spark Streaming(一)—— Spark Streaming介绍
文章目录 1. 什么是Spark Streaming2. Spark Streaming特点3. 常用的实时计算引擎4. Spark Streaming内部结构5. StreamingContext对象创建方式6. 离散流DStream6.1 什么是DStream6.2 DStream中的算子 7. 窗口 1. 什么是Spark Streaming Spark Streamin
spark streaming中的广播变量应用
1. 广播变量 我们知道spark 的广播变量允许缓存一个只读的变量在每台机器上面,而不是每个任务保存一份拷贝。常见于spark在一些全局统计的场景中应用。通过广播变量,能够以一种更有效率的方式将一个大数据量输入集合的副本分配给每个节点。Spark也尝试着利用有效的广播算法去分配广播变量,以减少通信的成本。 一个广播变量可以通过调用SparkContext.broadcast(v)方法从一个初
spark-Streaming direct和receiver方式读取的区别
区别: Spark-Streaming获取kafka数据的两种方式-Receiver与Direct的方式,可以从代码中简单理解成Receiver方式是通过zookeeper来连接kafka队列,Direct方式是直接连接到kafka的节点上获取数据了。 一、基于Receiver的方式 这种方式使用Receiver来获取数据。Receiver是使用Kafka的高层次Consumer API来实
kafka+spark streaming例子入门
启动Kafka Server: bin/zookeeper-server-start.sh config/zookeeper.propertiesbin/kafka-server-start.sh config/server/properties 创建topic bin/kafka-topics.sh --create --zookeeper localhost:2181 --replic
解决KafkaConsumer多线程接入不安全问题(spark streaming 消费kafka)
使用场景: 设置并行度参数spark.streaming.concurrentJobs >1 时候,使用spark streaming消费kafka 异常信息: There may be two or more tasks in one executor will use the same kafka consumer at the same time, then it will throw

Spark的Streaming + Flume进行数据采集(flume主动推送或者Spark Stream主动拉取)
Spark的Streaming + Flume进行数据采集(flume主动推送或者Spark Stream主动拉取) 1、针对国外的开源技术,还是学会看国外的英文说明来的直接,迅速,这里简单贴一下如何看: 2、进入到flume的conf目录,创建一个flume-spark-push.sh的文件: [hadoop@slaver1 conf]$ vim flume-spark-push.

Spark的Streaming和Spark的SQL简单入门学习
Spark的Streaming和Spark的SQL简单入门学习 1、Spark Streaming是什么? a、Spark Streaming是什么? Spark Streaming类似于Apache Storm,用于流式数据的处理。根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、
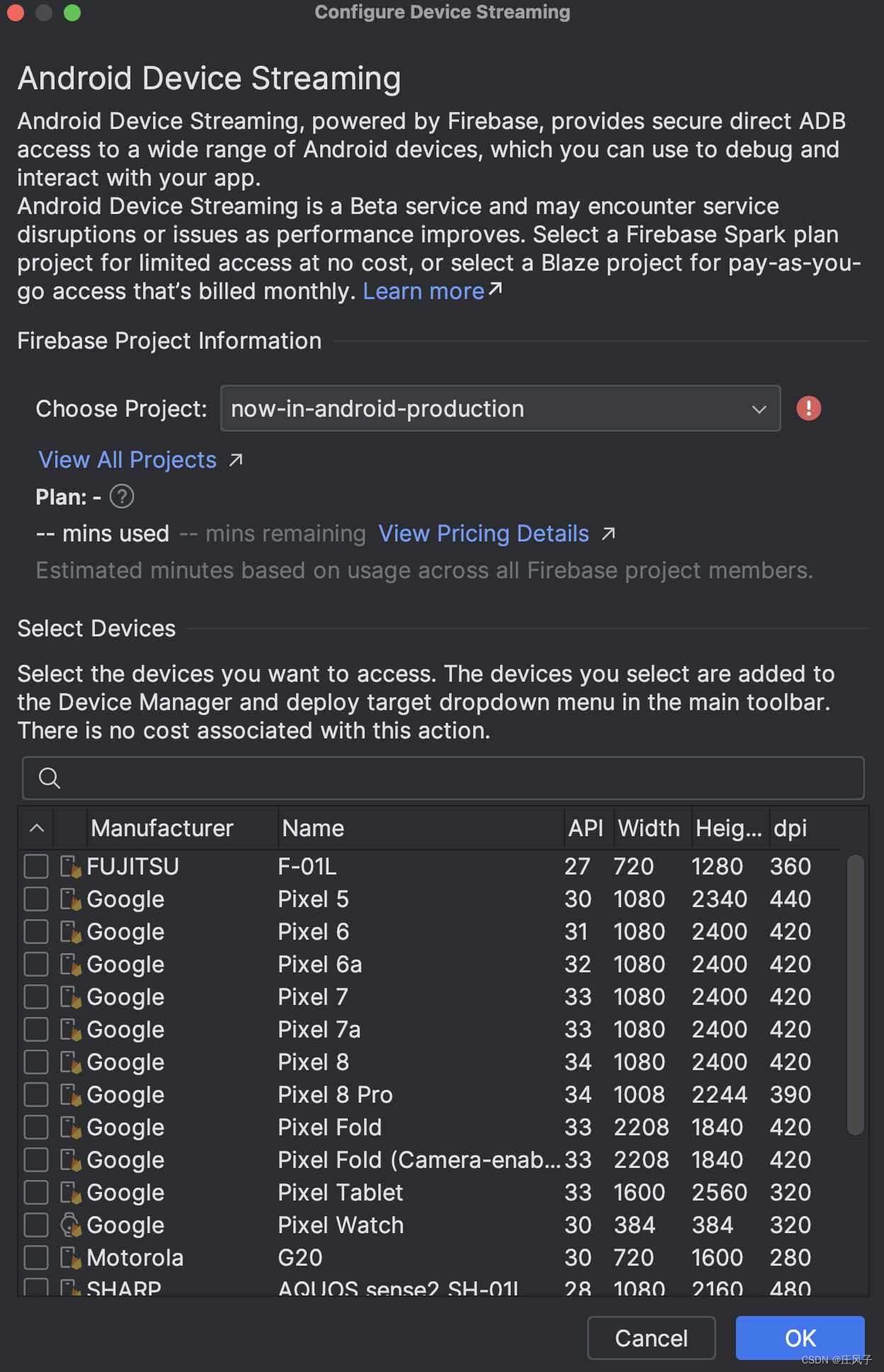
Android Studio新增功能:Device Streaming
今天将Android Studio升级到2023.3.1 Patch2。发现新增了Device Streaming功能。支持远程使用Google的物理设备调试程序。这样可以方便地在真实设备上测试自己的APP。这对于手头没有Google设备的开发者而言,确实方便很多。该功能目前处于测试阶段,在2025年2月之前,每个项目每月有120分钟的免费额度。 国内现在其实也有一些类似的平台,支持远程在指定型