本文主要是介绍【博客718】时序数据库基石:LSM Tree(log-structured merge-tree),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
时序数据库基石:LSM Tree(log-structured merge-tree)
1、为什么需要LSM Tree
LSM被设计来提供比传统的B+树更好的写操作吞吐量,通过消去随机的本地更新操作来达到这个目标,使得写入都是顺序写,而不是随机写。
那么为什么这是一个好的方法呢?这个问题的本质还是磁盘随机操作慢,顺序读写快的老问题。这二种操作存在巨大的差距,无论是磁盘还是SSD。
2、LSM Tree是一种思想,非固定实现方式
LSM树是一种将:
- 磁盘顺序写
- 多个树状数据结构集合
- 冷热(新老)数据分级
- 定期归并
- 非原地更新
这几种特性统一在一起的思想。
综述:LSM树的核心特点是利用顺序写来提高写性能,但因为分层(此处分层是指的分为内存和文件两部分)的设计会稍微降低读性能,但是通过牺牲小部分读性能换来高性能写,使得LSM树成为非常流行的存储结构。
3、LSM Tree的定义:
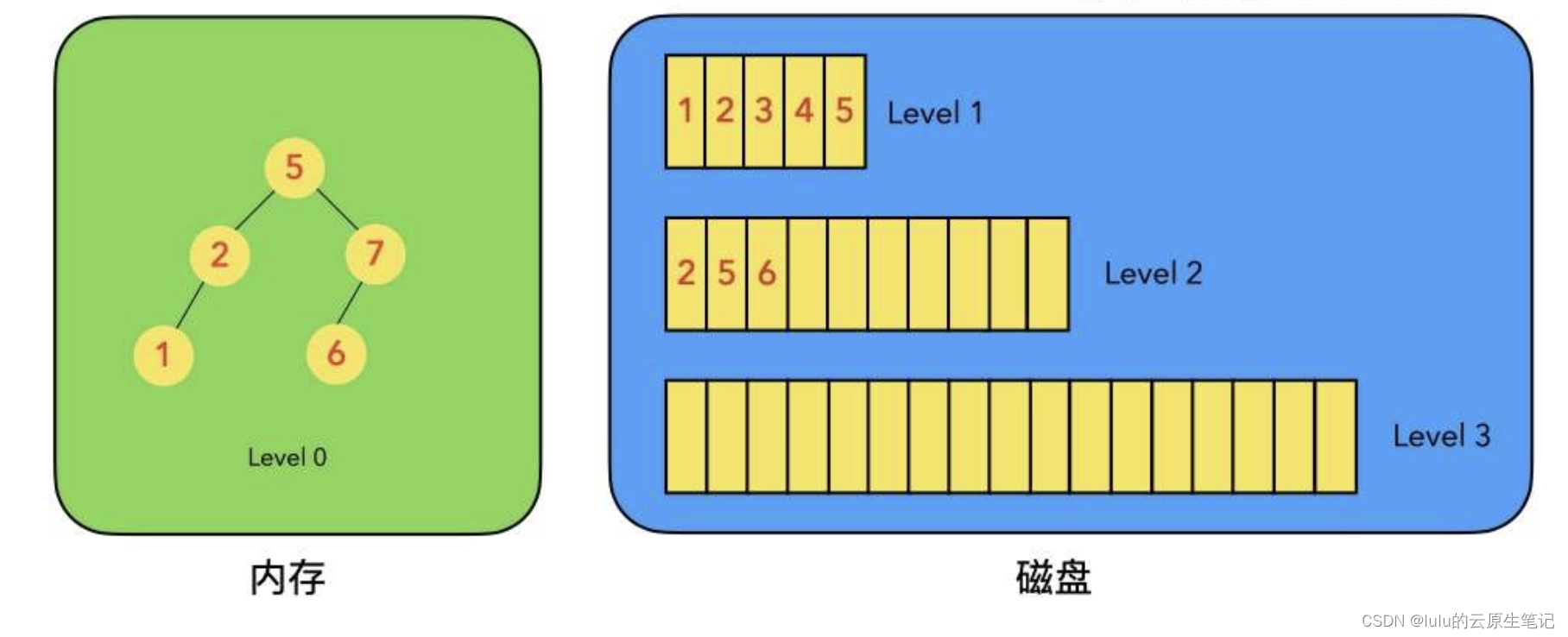
- LSM树是一个横跨内存和磁盘的,包含多颗"子树"的一个森林。
- LSM树分为Level 0,Level 1,Level 2 … Level n 多颗子树,其中只有Level 0在内存中,其余Level 1-n在磁盘中。
- 内存中的Level 0子树一般采用排序树(红黑树/AVL树)、跳表或者TreeMap等这类有序的数据结构,方便后续顺序写磁盘。
- 磁盘中的Level 1-n子树,本质是数据排好序后顺序写到磁盘上的文件,只是叫做树而已。
- 每一层的子树都有一个阈值大小,达到阈值后会进行合并,合并结果写入下一层。
- 只有内存中数据允许原地更新,磁盘上数据的变更只允许追加写,不做原地更新。
4、LSM Tree中的各级结构
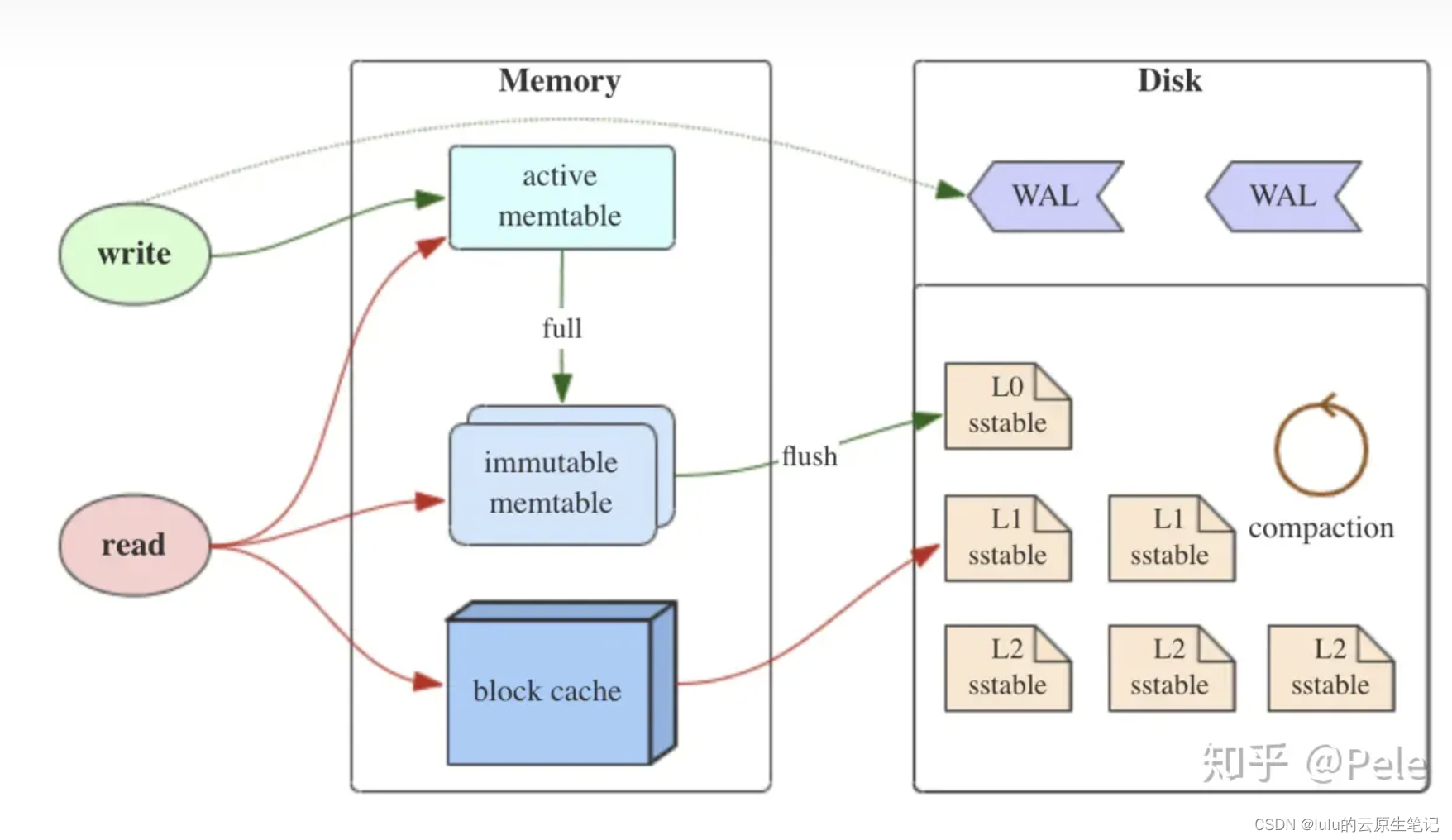
4-1、MemTable
MemTable是在内存中的数据结构,用于保存最近更新的数据,会按照Key有序地组织这些数据,LSM树对于具体如何组织有序地组织数据并没有明确的数据结构定义,例如Hbase使跳跃表来保证内存中key的有序。
因为数据暂时保存在内存中,内存并不是可靠存储,如果断电会丢失数据,因此通常会通过WAL(Write-ahead logging,预写式日志)的方式来保证数据的可靠性。
4-2、Immutable MemTable
当 MemTable达到一定大小后,会转化成Immutable MemTable。Immutable MemTable是将转MemTable变为SSTable的一种中间状态。写操作由新的MemTable处理,在转存过程中不阻塞数据更新操作。
4-3、SSTable
LSM Tree采取读写分离的策略,会优先保证写操作的性能;其数据首先存储内存中,而后需要定期 Flush 到硬盘上。LSM-Tree 通过内存插入与磁盘的顺序写,来达到最优的写性能,因为这会大大降低磁盘的寻道次数,一次磁盘 IO 可以写入多个索引块。HBase, Cassandra, RockDB, LevelDB, SQLite 等都是基于 LSM Tree 来构建索引的数据库;LSM Tree 的树节点可以分为两种,保存在内存中的称之为 MemTable, 保存在磁盘上的称之为 SSTable。
LSM tree 通过一种叫做 SSTable (Sorted Strings Table) 的格式,持久化到硬盘上。正如其名,SSTable 是一种用来存储有序的键值对的格式,其中键的组织是有序存储的。一个SSTable 会包括多个有序的子文件,被称为 segment 。 这些 segments 一旦被写入硬盘,就不可以再修改了。一个简单的SSTable 例子如下图所示:
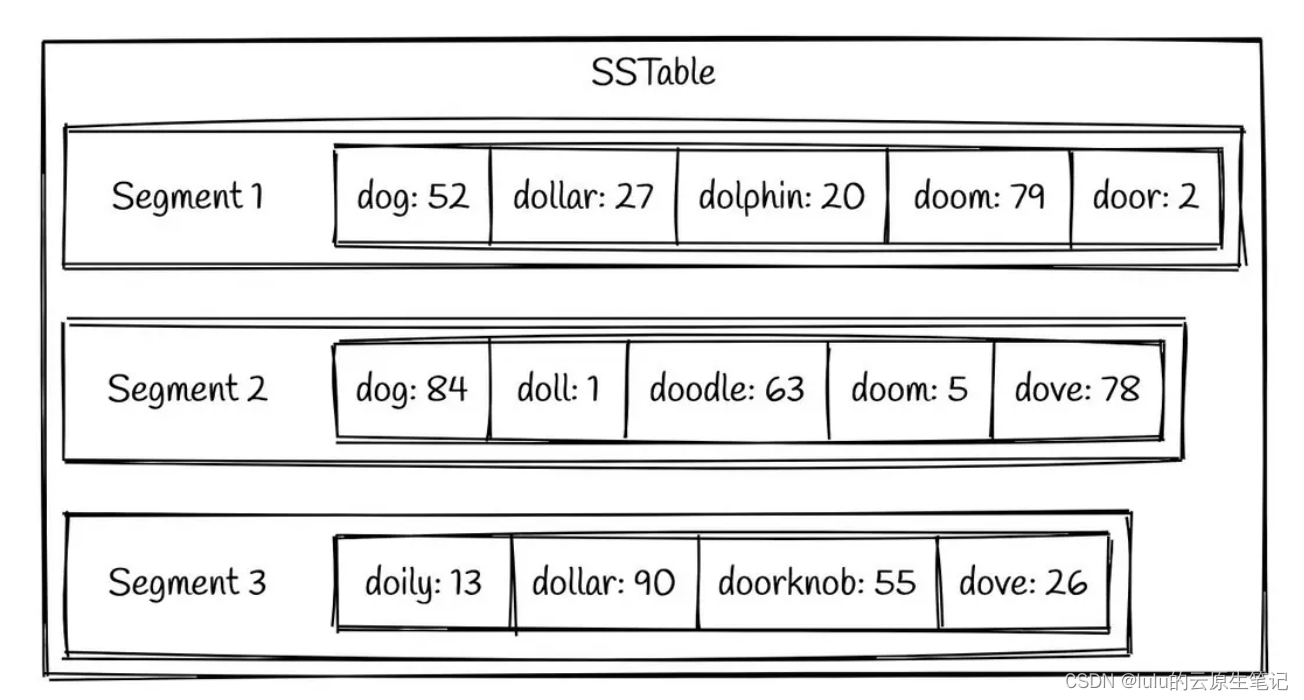
SSTable的查找优化:


这篇关于【博客718】时序数据库基石:LSM Tree(log-structured merge-tree)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








