本文主要是介绍TPGR代码详解 Large-Scale Interactive Recommendation with Tree-Structured Policy Gradient,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文阅读笔记链接
github代码链接
目录
- 论文内容
- MDP过程
- 训练TPGR过程:
- 采样过程
- 结构讲解
- DEBUG过程
- 代码详解
- 整体流程
- run函数
- 1. PRE_TRAIN()
- init()
- make_graph()
- train()
- evaluate
- 一些问题记录
- 参数相关
- 2. Tree()
- init()
- construct_tree()
- build_mapping()
- hierarchical_code()
- pca_clustering()
- 3. TPGR()
- init()
- make_graph()
- evaluate
- train
- 补充知识
- 函数
- GRU
- 报错
论文内容
论文阅读笔记
MDP过程
- state:用户历史交互记录(itemID编码为embedding,reward编码为one-hot)经过SRU编码后拼接上user_status(给正/负反馈的数量,给连续正/负反馈的数量)
- action:选择为用户 i i i推荐的产品 j j j
- reward: R ( s , a ) = r i , j + α ( c p − c n ) R(s,a)=r_{i,j}+\alpha(c_p-c_n) R(s,a)=ri,j+α(cp−cn),前者表示环境模拟器中标准化[-1~1]后的分数,后者表示连续正反馈数量减去连续负反馈数量。会映射到10维的向量。
训练TPGR过程:
- 给定孩子数 c c c和所有物品的 e m b e d d i n g embedding embedding(rating,VAE, MF),建立一颗层次聚类树。
- 算出非叶节点数量 L L L,对应策略网络数量,进行随机初始化。
- 根据Sampling Episode采样出一条路径 ( s 1 , p 1 , r 1 . . . . s n , p n , r n ) (s_1, p_1, r_1....s_n, p_n, r_n) (s1,p1,r1....sn,pn,rn),通过连乘选路径时做选择的概率( π θ {\pi}_{\theta} πθ输出做某个选择的概率),将路径映射到动作 a t a_t at。
- 使用策略梯度下降进行训练,已知 ( a t , s t , G ) (a_t,s_t,G) (at,st,G), G G G为累积收益。
采样过程
- 将 s t a t e state state输入 d d d个策略网络(物品id映射为embedding,reward经过one-hot编码,输入SRU,再与user_status拼接,得到state),做 d d d次选择,每次从 1 ∼ c 1\sim c 1∼c中选一个,同时记录下每次选择的 n o d e _ i n d e x node\_index node_index。
- p t = ( c 1 , c 2 , . . . , c d ) p_t=(c_1,c_2,...,c_d) pt=(c1,c2,...,cd),将 p t p_t pt映射到物品 a t a_t at,获取 r t r_t rt(将物品推荐给用户了,有反馈)。
- 根据状态转移函数得到 s t + 1 s_{t+1} st+1,重复上述过程,直到得到 E = ( s 1 , p 1 , r 1 . . . . s n , p n , r n ) E=(s_1, p_1, r_1....s_n, p_n, r_n) E=(s1,p1,r1....sn,pn,rn)

代码顺序:
- 先预训练rnn(recommender调用tpgr中的PRE_TRAIN)
- 再建树(recommender调用tpgr中的Tree)
- 最后训练TPGR(recommender调用tpgr中的TPGR)
结构讲解
在github下载代码解压后,可以看见目录如下
- data目录中的rating存放的是数据集,形式是:user item rating;可以根据需要替换成自己的数据集。
- src目录就是所有代码啦
看代码前我们先看看readme文件,如果某个代码中有Readme一定要先看看哦,里面通常包括了整个项目的简单介绍,包括一些参数设置。
其README文件和解释如下:
- run_time_tools文件中的mf_with_bias()使用PMF获取item的embedding,将结果item_embeddings_value存在rating_file(config文件定义的)中。
In run_time_tools.py, mf_with_bias() is to gain embeddings of items by utilizing the PMF model;
- clustering_vector_constructor()按照rating/vae/mf,建立平衡层次聚类树,存在result_file_path中。
clustering_vector_constructor() is to construct item representation in order to building the balanced hierarchical clustering tree.
- tpgr.py中有三个类,PRE_TRAIN:rnn预训练; TREE:构建树; TPGR:TPGR训练。
In tpgr.py, class PRE_TRAIN, TREE and TPGR correspond to the rnn pretraining step, tree constructing step and model training step of the TPGR model.
- config参数如下,具体含义都写出来了,就不解释了:
[META]
ACTION_DIM: the embedding dimension of each action (item).
STATISTIC_DIM: the dimension of the statistic information, in our implementation, there are 9 kinds of statistic information.
REWARD_DIM: the dimension of the one-hot reward representation.
MAX_TRAINING_STEP: the maximum training steps.
DISCOUNT_FACTOR: discount factor for calculating cumulated reward.
EPISODE_LENGTH: the number of recommendation interactions of each episode.
LOG_STEP: the number of interval steps for printing evaluation logs when training the TPGR model.[ENV]
RATING_FILE: the name of the original rating file, the rating files are stored in data/rating as default.
ALPHA: to control the ratio of the sequential reward as described in the paper.
BOUNDARY_RATING: to divide positive and negative rating.
MAX_RATING: maximum rating in the rating file.
MIN_RATING: minimum rating in the rating file.[TPGR]
PRE_TRAINING: bool type (T/F), indicating whether conducting pretraining step.
PRE_TRAINING_STEP: the number of pretraining steps. # 30
PRE_TRAINING_MASK_LENGTH: control the length of the historical rewards to recover when pretraining. # 32
PRE_TRAINING_SEQ_LENGTH: the number of recommendation interactions of each episode when pretraining. # 64
PRE_TRAINING_MAX_ITEM_NUM: the maximum number of items to be considered when pretraining. # 64
PRE_TRAINING_RNN_TRUNCATED_LENGTH: rnn truncated length. # 32
PRE_TRAINING_BATCH_SIZE: the batch size adopted in pre-training step.
PRE_TRAINING_LOG_STEP: the number of interval steps for printing evaluation logs when pre-training.
PRE_TRAINING_LEARNING_RATE: initialized learning rate for AdamOptimizer adopted in pre-training step.
PRE_TRAINING_L2_FACTOR: l2 factor for l2 normalization adopted in pre-training step.CONSTRUCT_TREE: bool type (T/F), indicating whether conducting tree building step.
CHILD_NUM: children number of the non-leaf nodes in the tree.
CLUSTERING_TYPE: clustering type, PCA or KMEANS.
CLUSTERING_VECTOR_TYPE: item representation type, RATING, VAE or MF.
CLUSTERING_VECTOR_VERSION: the version of the item representation.RNN_MODEL_VS: the version of the pretrained rnn.
TREE_VS: the version of the tree.LOAD_MODEL: bool type (T/F), indicating whether loading existing model.
MODEL_LOAD_VS: the version of the model to load from.
MODEL_SAVE_VS: the version of the model to save to.HIDDEN_UNITS: the hidden units list for each policy network, seperated by ','.
SAMPLE_EPISODES_PER_BATCH: the number of sample episodes for each user in a training batch.
SAMPLE_USERS_PER_BATCH: the number of sample users in a training batch.
EVAL_BATCH_SIZE: batch size of episodes for evaluation.LEARNING_RATE: initialized learning rate for AdamOptimizer.
L2_FACTOR: l2 factor for l2 normalization.
ENTROPY_FACTOR: to control the smooth of the possibility distribution of the policy.
DEBUG过程
- 运行时,如果出现缺少包而报错,则使用
conda install packagename安装包。 - 安装完需要的包后,运行程序,发现报错
FileNotFoundError: [Errno 2] No such file or directory: '../data/run_time/demo_data_env_objects'
找到对应语句:
# if you replace the rating file without renaming, you should delete the old env object file before you run the code
env_object_path = '../data/run_time/%s_env_objects'%self.config['ENV']['RATING_FILE']####省略了很多代码行###
# dump the env object
utils.pickle_save({'r_matrix': self.r_matrix, 'user_to_rele_num': self.user_to_rele_num}, env_object_path)
找到utils中“pickle_save”函数
def pickle_save(object, file_path):f = open(file_path, 'wb')pickle.dump(object, f)
- pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。
发现data目录下不存在run_time这个文件夹,于是手动创建一个。
- 创建目录了,还是有报错:
Ran out of input。找到报错位置,还是和pickle相关:
def pickle_load(file_path):f = open(file_path, 'rb')return pickle.load(f)
原因:load的文件为空,就会出现这种错误。发现上一步并未成功保存文件。
保存时报错'module' object is not callable,检查后发现pickle.dump写错了(上面是正确的)
- 总之就是遇到bug就一个一个改,就可以跑起来啦:

代码详解
这部分讲解整个代码框架。
整体流程
- main函数使用configparse函数解析配置文件
- 创建Recommender实例,除了初始化函数只有一个run函数
- 调用Recommender中的run函数
run函数
首先获取配置文件参数值,之后:
- 判断是否需要预训练,调用tpgr.py进行预训练
if self.config['TPGR']['PRE_TRAINING'] == 'T':log.log('start pre-training', True)pre_train = PRE_TRAIN(self.config, self.sess) # TPGR中的类for i in range(pre_training_step):pre_train.train()log.log('end pre-training', True)
- 判断是否需要构建树,tpgr.py进行构建
if self.config['TPGR']['CONSTRUCT_TREE'] == 'T':log.log('start constructing tree', True)tree = Tree(self.config, self.sess)tree.construct_tree()log.log('end constructing tree', True)
- 训练TPGR模型
log.log('start training tpgr', True)tpgr = TPGR(self.config, self.sess)for i in range(0, max_training_step):if i % log_step == 0:tpgr.evaluate()log.log('evaluated\n', True)tpgr.train()log.log('end training tpgr')
可以看到,每一部分都用到了tpgr中的类,下面我们看看tpgr文件的构成。tpgr由三个类构成:

1. PRE_TRAIN()
先创建类pre_train = PRE_TRAIN(self.config, self.sess),再训练pre_train.train()。
目的预训练rnn参数,获得更好的state。输出是:W(SRU(action_embedding,reward,pre_statistic),pre_statistic)+b,groundtruth是reward。
共有以下几个函数:
init()
init(): 主要是从config文件中获取参数,创建batch_size个Env。
self.env = [Env(self.config, self.user_num, self.item_num, self.r_matrix, self.user_to_rele_num) for i in range(max(self.user_num, self.batch_size))]创建多个env实例。
然后调用make_graph()
Env():创建对象时,读取config文件内容(action维度,episode长度等);加载数据集,存储user_num(用户数), item_num, r_matrix(存储评分矩阵), user_to_rele_num(用户u给出的高分数)等信息。(其中 item_num, r_matrix 存储在env_object_path中(‘…/data/run_time/demo_data_env_objects’))
然后通过run_time_tools.mf_with_bias(self.config),获取item_embedding,并存到item_embedding_file_path(‘…/data/run_time/demo_data_item_embedding_dim8’)。(如果之前运行过,就直接loda item_embedding_file_path就好啦)
run_time_tools.mf_with_bias()主要过程:使用训练数据(80%),定义并训练user_embs和item_embs矩阵,使得二者相乘的结果接近rating真实值,将item_embeddings作为结果(和MF差不多)。
后续tpgr.py会用它查表,获取item embedding,作为rnn的一个输入。建立平衡树的时候,会用到item embedding,如果是MF-based方法,也会用到它。Env类其他函数:
get_init_data:return self.user_num, self.item_num, self.r_matrix, self.user_to_rele_num这四个刚好是env需要的初始化输入reset:self.user_id = user_id,其他属性设为0get_relevant_item_num:return self.user_to_rele_num[self.user_id]返回该用户评分高于3.5的item数量get_reward:初始化reward = [0.0, False];传入item_id,根据get_rating得到item评分,进行归一化处理得到reward[0],并按照reward[0]大小统计各种变量(con_neg_count等)。最后reward[0] += self.alpha * sr # sr是高分数量减去低分数量;item全部遍历后或者达到episode_length时,reward[1] = True。get_statistic:获取参数,如all_neg_count(获取reward时就更新过了),这部分和rnn输出拼接起来作为stateget_rating: 从评分矩阵返回评分self.r_matrix[self.user_id, item_id]- 属性:

make_graph()
初始化时就调用了,主要是定义了整个前向传播过程,loss函数定义。
- 首先建立了多个placeholder(action, rnn_state, reward, statistic),长度为rnn预训练长度32。从env中获取action_embeddings(也就是PMF分解得到的物品embedding);
- 调用
create_sru,输入self.rnn_input_dim, self.rnn_output_dim:对W,b等参数进行初始化,运算过程函数。返回self.rnn(unit函数,定义遗忘门,重置门,记忆单元;返回隐藏层和记忆单元拼接), self.rnn_variables(5个参数)
# 创建SRU#init_matrix表示从“服从指定正态分布的序列”中随机取出指定个数的值Wf = tf.Variable(self.init_matrix([rnn_input_dim, rnn_output_dim])) bf = tf.Variable(self.init_matrix([rnn_output_dim]))Wr = tf.Variable(self.init_matrix([rnn_input_dim, rnn_output_dim]))br = tf.Variable(self.init_matrix([rnn_output_dim]))U = tf.Variable(self.init_matrix([rnn_input_dim, rnn_output_dim]))sru_variables = [Wf, Wr, U, bf, br]def unit(x, h_c):pre_h, pre_c = tf.unstack(h_c)# forget gatef = tf.sigmoid(tf.matmul(x, Wf) + bf)# reset gater = tf.sigmoid(tf.matmul(x, Wr) + br)# memory cellc = f * pre_c + (1 - f) * tf.matmul(x, U)# hidden stateh = r * tf.nn.tanh(c) + (1 - r) * xreturn tf.stack([h, c]) # 拼接起来,输出隐藏层和记忆层
- 进行查表操作,找到每一个action对应的嵌入(8维,共32个);将reward映射为one-hot形式,维度为reward_dim。构造rnn输入pre_ars:拼接action embedding + reward + pre_statistic,27维,32个;初始隐藏层,初始化为0了(2,batch_size,27)。
- SRU输出:
tmp_state = self.rnn(self.pre_ars[i], tmp_state)循环32次,结果保存在cur_rnn_states_list,32个(2,?,27) 其中2代表[h,c],27是维度。 - 整体训练过程了! W ( S R U ( ) , s t a t i c ) + b W(SRU(),static)+b W(SRU(),static)+b定义variable变量,W(36,64) b(64,)其中64是max_item_num,36是 rnn_output_dim+statistic_dim。定义了l2损失。
- 预测值:
self.pn_outputs = [tf.matmul(tf.concat([self.cur_rnn_states_list[i][0], self.pre_statistic[i]], axis=1), self.W) + self.b for i in range(self.pre_train_truncated_length)]rnn输出和pre_statistic拼接起来,和w相乘再加上b,共32个值 - 真实值:placeholder (?,64); mask也是placeholder(有的地方被设置成0了)
- loss函数:设置了两种loss函数 all_zero_loss(将预测结果视为0矩阵)和loss((1.0 / tf.reduce_sum(self.mask)*求和{根号下(mask *(预测值-真实值))} 开根号)。一共也是32个loss。
self.all_zero_loss = tf.pow((1.0 / tf.reduce_sum(self.mask)) * tf.reduce_sum(tf.square(self.mask * (tf.cast(tf.constant(np.zeros(shape=[self.batch_size, elf.max_item_num])), dtype=tf.float32)self.expected_pn_outputs))), 0.5) # mask掉的是看不见的
self.loss = [tf.pow((1.0 / tf.reduce_sum(self.mask)) * tf.reduce_sum(tf.square(self.mask * (self.pn_outputs[i] - self.expected_pn_outputs))), 0.5) for i in range(self.pre_train_truncated_length)]
train()
- 首先构造了batch_size个用户,每个用户产生了max_item_num个action,然后一个用户一个物品地训练
① 首先随机选取batch_size个用户id,每个用户都运行self.env[i].reset(user_id):记下idself.user_id = user_id把各个属性重置为零(step_count,con_neg_count,con_zero_count,all_neg_count,history_items)。
② 定义action_value_list:batch_size个预训练action列表[1,2,3…64];然后打乱顺序;再取出前pre_train_seq_length列
③ 对每一个user env类(共batch_size个),调用env中函数获取reward:首先从评分矩阵返回对该物品的评分,并进行归一化,reward[0] += self.alpha * sr。 - 循环pre_train_seq_length次:
sampled_action = action_value_list[:, i],先取出一列action的值(相当于每个env对应的item);ars存储action(最终有64个list,长度为batch_size),reward,statistic(9个固定值除以32,all_neg_count,all_pos_count, con_neg_count等)。 第j个env中用户对应的item为sampled_action[j],ars存储反馈等值。 对batch_size用户采样64个item,并存储他们的reward,statistic - 运行evaluate函数
- 训练模型,初始化ground_truth和mask_value,都是(batch_size,64)的矩阵,表示用户对第i个采样的反馈;运行pre_rnn_state_list,初始化为0
- 开始预训练了,循环64次。取出ars中的actions,rewards(长度为batchsize);存入ground_truth;初始化mask。
- 喂数据:pre_rnn_state_list[0],ground_truth,mask_value 以及ars数据。注意action是0~i+1,也就是第i次及其前面的action(一共传入i个action),reward都传进去。然后run
pre_train_op最小化损失,cur_rnn_states_list[i]rnn前向传播过程。都是一轮一轮训练的哦!pre_rnn_state_list.append(rnn_state) - 训练5轮就存储rnn_variables,即rnn的参数。这也是预训练的最终目的

注意!!训练长度64,但是是分了两部分(可能是因为episode=32?),前32和后32if i < self.pre_train_truncated_length。前32次,pre_actions长度逐渐递增,rnn输入之一pre_rnn_state一直是0,输出存起来了,训练pre_train_op[i]。后32次要一个一个取出来pre_rnn_state作为输入,ground_truth和mask_value计算方法没有变,变的是pre_actions(长度一直为32了):1-32;2-33…32-63作为pre,训练pre_train_op[31](都只训练最后一次,预测值也是只训练最后一个矩阵,因为输入都给完了)。整个64步都走完,才有pre_training_steps+1。这一整个步骤又会重复pre_training_step次。 最后保存参数
所以预训练rnn的目的是,输出结果拼接上固定值后经过全连接的结果与reward尽量相似。(有点不太明白,为什么这样就可以衡量state好坏呢)似乎是通过前i个序列(item embedding,reward,固定参数)预测第i个reward
真实值:一个矩阵,行数代表batch,列数代表采样该action获取的reward。预测值也是这样的一个矩阵,不过训练32次就有32个矩阵
有两个loss,all_zero_loss是干嘛的?应该是为了做对比
init_matrix():return tf.random_normal(shape, stddev=0.1)_get_initial_ars()
evaluate
这里只是评估,并没有训练
-
首先和train一样,创建batch_size个用户,reset;创建action_value_list [0,1,2…,63],共batch_size个。
-
获取batch_size中用户对action_value_list的reward、statistic,用ars存储

-
初始化ground_truth,mask_value,运行rnn_state(全为0)
-
循环64次,取出ars中的数据:① 取出第一轮采样的action(一共64轮,长度为batch_size) ② 为ground_truth赋值,存储对应action的对应reward。就是一个矩阵,batchsize行,64列(对应action)。 ③ mask_value,把ground_truth对应reward位置全改成0 ④ 当循环<32时,直接喂数据(第i列的action),并run
cur_rnn_states_list,rnn前向传播过程,只运行一轮,传入27位的拼接向量以及隐藏层(0初始化),输出(2,?,27) -
循环次数>=32时:
pre_actions = ars[0][i - self.pre_train_mask_length]然后把pre_actions内容对应的mask值改成0,再喂数据,run。这个地方是保证,能看见的数据长度只有32?
feed_dict = {self.pre_rnn_state: rnn_state,self.expected_pn_outputs: ground_truth,self.mask: mask_value,self.pre_actions[0]: ars[0][i], # batchsize长度self.pre_rewards[0]: ars[1][i], self.pre_statistic[0]: ars[2][i]}rnn_state = self.sess.run(self.cur_rnn_states_list[0], feed_dict=feed_dict)
- run 损失函数,并输出
之后进行训练,最后再调用evaluate,训练多次后,保存rnn参数utils.pickle_save(self.sess.run(self.rnn_variables), self.rnn_file_path + 's%d' % self.pre_training_steps)。
对rnn进行预训练后,之后就不用预训练啦~
后面我就把运行预训练的部分注释掉啦~
一些问题记录
参数相关
-
pre_train_truncated_length(32,rnn预训练长度):action 的placeholder数量,也就是训练时要输入多少个action

-
max_item_num(64):决定了W和b的参数大小,有点像最后一层神经元个数。

action_value_list是由[1,2,3…64]组成的

-
pre_train_seq_length(64,预训练时每一轮的交互长度)代码中和max_item_num是一样的,用于控制action_value_list长度;控制采样多少次,ars长度
-
pre_train_mask_length(32,在预训练时控制要恢复的历史奖励的长度)mask的都看不见了

2. Tree()
先初始化tree = Tree(self.config, self.sess) ,再调用建树函数tree.construct_tree()
将item_embedding(VAE,rating,MF)聚类(k-means-based, PCA-based),结果文件包括id_to_code, code_to_id,dataset,child_num,clustering_type。
id_to_code :[父节点位置,叶节点位置], code_to_id:叶节点在最后一层的位置对应的一开始在数据集中的位置。
init()
init():定义各种参数,如非叶节点子节点数量child_num(伪代码中是给出总item数和深度d,计算c;实际代码直接给出了c),聚类方式PCA,clustering_vector_file_path,tree_file_path。创建env对象。
根据总item数和c,计算深度:self.bc_dim = int(math.ceil(math.log(self.env.item_num, self.child_num)))
construct_tree()
主要是调用 build_mapping()函数:id_to_code, code_to_id = self.build_mapping(),并将输出id_to_code,code_to_id,dataset,child_num,clustering_type转为obj并存储utils.pickle_save(obj, self.tree_file_path)。

build_mapping()
主要是两个映射。
- 初始化全为0的数组
id_to_code,[item_num, bc_dim] 这个相当于辈分列表 - 获取聚类需要的物品embedding(rating,VAE,MF):
run_time_tools.clustering_vector_constructor(self.config, self.sess),将结果id_to_vector(user num * item num)存入clustering_vector_file_path。(如果之前保存过结果,就直接打开文件就好了)
- 调用
hierarchical_code(self, item_list, code_range, id_to_code, id_to_vector函数,首先传入:从0 ∼ \sim ∼物品数组成的list,(0 ∼ c h i l d _ n u m b c _ d i m \sim {child\_num}^{bc\_dim} ∼child_numbc_dim)组成的tuple,id_to_code(会被修改), id_to_vector。经过内部的递归调用,id_to_code会变化,是一个 - code_to_id :
code_to_id = self.get_code_to_id(id_to_code)返回一个一维数组,总长度代表叶节点数量,值表示一开始在数据集中的位置。也就是item在叶节点编号对应的数据集中的id
def get_code_to_id(self, id_to_code):result = -np.ones(shape=[int(int(math.pow(self.child_num, float(self.bc_dim))))], dtype=int)for i in range(len(id_to_code)):code = id_to_code[i]result[self.get_index(code)] = iprint('leaf num count: %d\nitem num count: %d'%(len(result), int(np.sum([int(item>=0) for item in result]))))return result
- 返回
(id_to_code, code_to_id)
hierarchical_code()
先是100个物品传入,通过聚类分成十个一组,共10个列表 --> 再分别将十个列表传入,通过聚类分成一个一组,共10个列表 --> 再将一个一组的列表传入,这时就会修改id_to_code。
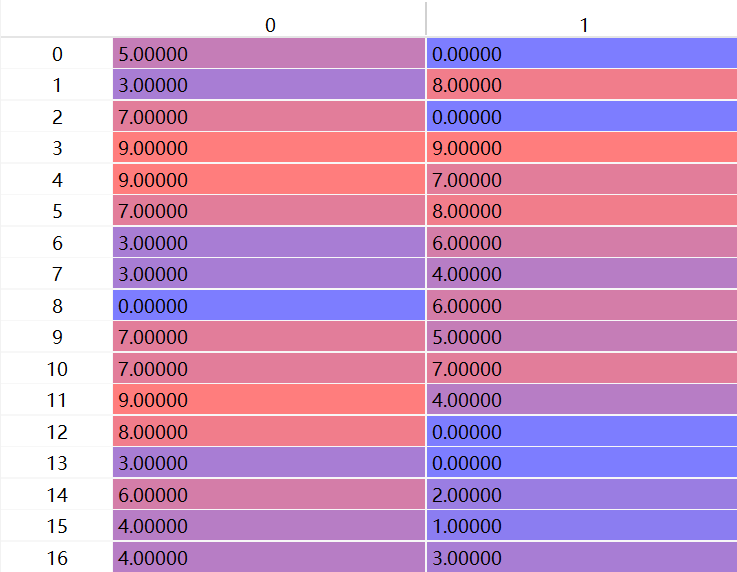
id_to_code:是一个二维数组,第一列代表父节点在整棵树的位置,第二维代表当前节点在当前子树的位置(有点类似于排辈分)。比如[5,0]就代表当前节点的爸爸是他那一辈排第五的,而当前节点在他这一辈是老大,排第一。
- 先判断item_list长度,如果为1,就要改变id_to_code:
id_to_code[item_list[0]] = self.get_code(code_range[0]),并返回“辈分排名”。 - 传入item_list和id_to_vector,进行聚类
pca_clustering(),返回结果item_list_assign,是10个列表(每个列表是n个一组的item list(n=总长度除以孩子数10))。如传入100个物品,就会返回10个list,每个list有10个元素;最后一次是传入10个物品,返回10个长度为1的list。 - 开始递归调用,重复十次(因为分成了10类)
for i in range(self.child_num): # 10个组里,每个组都继续递归调用;直到len(item_list)=1self.hierarchical_code(item_list_assign[i], (code_range[0]+i*range_len, code_range[0]+(i+1)*range_len), id_to_code, id_to_vector)
① 先是把分好的十个组一个一个放进去调用hierarchical_code,传入的第二个参数代表传入数据的起始位置((0,10),(10,20)…(90,100))
② 长度为10的列表传入后,还是先进行聚类,这次返回的是[[83], [95], [20], [92], [65], [58], [98], [42], [94], [90]]。(返回10个list);然后继续传入hierarchical_code,这次item_list长度为1。
③ 当传入递归的列表长度为1时,要修改id_to_code了!运行id_to_code[item_list[0]] = self.get_code(code_range[0]),传入当前在原始数据集中的位置。id_to_code[item]等于返回的二元数组
def get_code(self, id):code = np.zeros(dtype=int, shape=[self.bc_dim])for i in range(self.bc_dim):c = id % self.child_numcode[self.bc_dim-i-1] = cid = int(id / self.child_num)if id == 0:breakreturn code
pca_clustering()
- 输入为(0~item_num)的列表以及每个item对应的向量;首先找到每个item对应的向量,然后调用sklearn中的pca.fit(data)
- 然后建立投影,w是pca中的参数(代表所保留的特征个数):
item_to_projection = [(item, np.dot(id_to_vector[item], w)) for item in item_list](这里像是按聚类相似度排序?),然后按照从小到大排序存入result,然后10个一组(10也是算出来的,传入的物品数除以孩子数,int(math.ceil(len(result) * 1.0 / self.child_num)))item_list_assign.append([result[j][0] for j in range(start, end)])。
三种聚类方式:
kmeans_clustering(),random_clustering(),pca_clustering()
小小总结一下,这里就是建立平衡层次聚类树的过程,首先根据item embedding(三种获取方式)进行聚类,然后不停递归调用,建立聚类层次树。还有两个映射操作id_to_code :[父节点位置,叶节点位置], code_to_id:item在叶节点中的编号对应在数据集中的id
3. TPGR()
先创建对象,再运行evaluate函数。tpgr = TPGR(self.config, self.sess), tpgr.evaluate(),再train
在创建变量时可以看出,分成了训练集和评估集
init()
定义了损失函数哦
- 首先是从配置文件中读取参数,读取前面保存的的obj文件(rnn参数,建树的结果)
- 建立了env对象,
forward_env = Env(self.config),有很多数据集中的属性,以及使用PMF获取embedding的函数、获取reward的函数。 - 使用刚刚初始化env对象时的值,再次创建64000个env对象。
layer_units = [self.statistic_dim + self.rnn_output_dim] + self.hidden_units + [self.child_num]这里不知道是什么意思,(state + 隐藏层 + 孩子数 目前是[36,7])- self.aval_val = self.get_aval() ,调用时首先获取
node_num_before_depth_i,创建一个aval_list(child_num, node_num_before_depth_i(self.bc_dim)),然后又开始递归调用函数rec_get_aval。
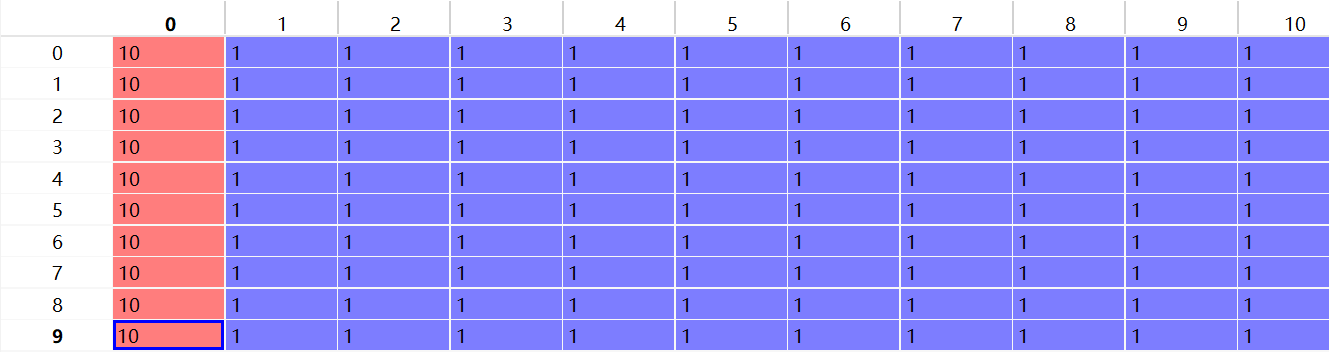
最后的aval_list如下,表示 每个非叶节点的每个子树中可用的item。
-
行数代表孩子节点数,列表示非叶节点数量(policy数量)。
-
第i列表示标号为i的policy的各个孩子节点可用的nodes;第一列代表节点0,也就是根节点。他一共有10个孩子节点0~9,每个孩子节点都还有10个孩子节点可用。行数=孩子数
-
后面十列表示第二层那十个节点,他们也有10个孩子节点,但是都是叶节点了,每个子节点只有一个节点可用。
make_graph()
- 创建很多个placeholder:forward_action(None),forward_reward(None),forward_statistic(None,statistic_dim),forward_rnn_state(2, None, rnn_output_dim),cur_q(None)(Q值),cur_action(None)
- 创建常量:action_embeddings(value=self.forward_env.item_embedding)PMF生成的物品embedding,bc_embeddings(value=self.id_to_code)[爸爸辈分,儿子辈分]
- 创建RNN输入需要的值。forward_a_emb(使用forward_action查表action_embeddings),one_hot_reward(使用tf.one命令将经过转换的forward_reward映射到reward_dim维),forward_ars(拼接[forward_a_emb, one_hot_reward, forward_statistic],这就是rnn输入哦)
- 初始化 rnn initial_states:拼接两个0值填充的tensor:
tf.stack([tf.zeros([self.train_batch_size, self.rnn_output_dim]), tf.zeros([self.train_batch_size, self.rnn_output_dim])])shape:(2,64000,27) - 加载前面预训练rnn得到的obj文件,并用参数创建create_sru,返回函数rnn和参数rnn_variables
- 定义rnn_state:使用rnn函数
rnn(forward_ars, forward_rnn_state),给rnn两个输入(item embedding+reward+statistic)+ forward_rnn_state(placeholder) - 定义user_state:拼接rnn隐藏层和固定参数[rnn_state[0], forward_statistic]。(rnn函数会返回两个值[h, c],隐藏层的和记忆细胞)
- 定义需要更新的参数W_list和b_list,初始化时正太分布,
shape=[node_num_before_depth_i(self.bc_dim), layer_units[i], layer_units[i + 1]]。(11,36,10):11表示非叶节点数,36是statistic_dim + rnn_output_dim,10是孩子数;layer_units = [self.statistic_dim + self.rnn_output_dim] + self.hidden_units + [self.child_num]。 - 将hidden state映射到action。定义常量code2id(value=code_to_id),树中的位置对应在数据集中的索引。
- Variable变量:aval_list和aval_eval_list。
tf.Variable(np.tile(np.expand_dims(self.aval_val, 1), [1, self.train_batch_size, 1]), dtype=tf.float32),tile() 函数将原矩阵按照维度复制;np.expand_dims:用于扩展数组的形状; 首先expand_dims把aval_val扩展成(10,1,11),再经过tile变为(10, 64000, 11)。相当于复制了train_batch_size份和eval_batch_size份aval_val。aval_val本来是(10,11),表示 每个非叶节点的每个子树中可用的item数。 eval_probs=[] - 又开始创建常量了,全部为0值:pre_shift(大小为train_batch_size),pre_mul_choice(大小为train_batch_size),action_index(大小为train_batch_size),pre_shift_eval(大小为eval_batch_size),pre_max_choice_eval(大小为eval_batch_size),action_index_eval(大小为eval_batch_size)。
- 赋值aval_list_t = aval_list,aval_eval_list_t = aval_eval_list;就是刚刚定义为Variable的变量。
后面开始进行采样过程,总采样次数应该是episode次(也就是需要为用户推荐多少item),每一次采样需要做d次选择,输入state,通过策略网络从1~child_num中做选择,并记录下节点索引。做了d次选择后, p t p_t pt存储每次做的选择,然后需要把路径映射到action。获取reward,更新state(h)。
前面算出的11,是非叶节点数,也是需要初始化的策略网络数
- 采样过程,做d次选择:循环深度次数
for i in range(self.bc_dim)2次:① 计算forward_indexself.forward_index = self.node_num_before_depth_i(i) + self.child_num * self.pre_shift + tf.cast(self.pre_mul_choice, tf.int32)(第i层前面的节点索引+孩子数*pre_shift + pre_mul_choice,是一个shape为64000的tensor)② 给h(h就是RL的输入state)赋值,if i == 0一开始赋user_state(拼接rnn隐藏层和固定参数(?,36)),之后将user_state增加一个维度(tf.expand_dims(self.user_state, axis=1)):tf.expand_dims(self.user_state, axis=1) ,(?, 1, 36) ③for k in range(len(self.W_list)):循环len(self.W_list)次(1次),W_list是前面定义的Variable变量,它的长度是len(self.layer_units) - 1,layer_units的长度又是state + 隐藏层 (为空)+ 孩子数[36,7],长度减一是1(如果有隐藏层,就要先经过一层隐藏层)。 ④if k == (len(self.W_list) - 1)(k是循环的最后一轮)定义移动概率forward_prob(否则给h赋值),if i == 0,self.forward_prob = tf.nn.softmax(tf.matmul(h, self.W_list[k][0]) + self.b_list[k][0], axis=1),就是经过一层全连接 外面包一层softmax,最终维度是(?,10),不就是输入state,返回选择10个节点的概率嘛(但是不是最终概率,后面还会处理的)。W的维度是(11,36,10):11表示非叶节点数,36是statistic_dim + rnn_output_dim,10是孩子数;self.W_list[k][0]维度是(36, 10)。b的维度是(11,10),h维度是(?,36)(后来会修改成 (?, 1, 36))
W维度(11,36,10)的含义:有11个一模一样的二维数组(36,10),36行,10列。10应该代表可选子树数量,11代表策略网络个数
下面写了一个例子,方便理解三维向量的意思。随机生成了(2,3,5):生成了两个一样的二维数组(3,5)
x = np.random.random([2,3,5])
x = array([[[0.90213642, 0.86585019, 0.63359569, 0.54320493, 0.61305485],[0.92393074, 0.54836019, 0.06053656, 0.57022926, 0.78738432],[0.24339059, 0.68440075, 0.42425335, 0.34418762, 0.42389787]],[[0.99615986, 0.16249693, 0.79286802, 0.45866597, 0.9477994 ],[0.80744563, 0.38976343, 0.56733192, 0.62285278, 0.038492 ],[0.11921885, 0.00678705, 0.67478142, 0.12596062, 0.58212996]]])

- 还是刚刚
for i in range(self.bc_dim)循环里面:修改pre_shift (一开始全赋值为0)self.pre_shift = self.child_num * self.pre_shift + tf.cast(self.pre_mul_choice, tf.int32); - 修改gather_index(64000, 10, 3)
evaluate
-
先计算eval_step_num,也就是每次采样多少;再将初始化eval_batch_size * eval_step_num个用户env( 共创建了5000个env),并传入用户id进行reset(从0~499,10个轮回)。这样每一个env都有对应的userID了
-
初始化ars:_get_initial_ars,调用env中获取reward的函数返回item_id,reward,statistic。① 循环5000次 ② 先随机选itemid,调用env[i]中函数获取选择item_id得到的reward,同时得到get_statistic。因此最终的result包括了5000组结果:item_id,reward,statistic。对应的是用户0~499。
 -
初始化entropy_list,用于存储指标rmse
-
为每位用户采样episode:① 算出首尾:0-5000。② 零值初始化rnn_state,step_count=0;
self.update_avalable_items(ars[0][0][start:end])③ 开始赋值,5000为一个batchsize:self.forward_action: ars[0][step_count][start:end],self.forward_reward: ars[1][step_count][start:end],self.forward_statistic: ars[2][step_count][start:end],self.forward_rnn_state: rnn_state(ars[0]代表action,也就是itemID,ars[1]代表reward,ars[2]代表固定值;这些placeholder都是在make_graph中定义的)。 -
开始run了:
run_list = [self.forward_sampled_action_eval, self.rnn_state, self.eval_probs, self.update_aval_eval_list],其中① forward_sampled_action_eval是查表操作,目的是将action索引转成数据集中的;② rnn_state是运行rnn函数,传入forward_ars和forward_rnn_state,输出h和c的stack;③ eval_probs存储了每次选择时算出的概率;④ update_aval_eval_list是删除了选过的item,并进行赋值。

-
sampled_action, rnn_state, probs = result_list[0:3]进行赋值:数据集中对应的action(5000,),运行rnn的结果(2,5000,27),每次选择item的概率list(5000,20)(长度为20,因为需要选择2次,每次有10个选项) -
计算rmse:
rmse = np.power(np.mean(np.square(probs - 1.0 / self.child_num)), 0.5)这里不太明白。append到entropy_list中。step_count+1 -
为ars添加[]
-
循环5000次,衡量action好坏了!查找sampled_action的reward,像之前一样append到ars中,如果reward[1]=True(item全部遍历后或者达到episode_length),stop_flag = True。 好奇怪 step_count应该每次都+1啊,不对!传入的user不一样,是不同的env
-
结束上面的循环后, 取出前500个用户的reward,并计算训练集的平均奖励和测试集的平均奖励,以及平均rmse
-
tp_list存储每个用户推荐列表中的高分数量;rele_list存储用户历史评分高于3.5的数量
-
循环user_num次,要衡量rating了:self.forward_env.reset(j),这是最开始传入config文件初始化的哦,返回ratings(list 32)
ratings = [self.forward_env.get_rating(ars[0][k][j]) for k in range(0, len(ars[0]))],ars[0]是(32,5000),k是0~31,代表获取给用户生成的32长度的episode的rating;tp = len(list(filter(lambda x: x>=self.boundary_rating, ratings)))返回分数大于等于3.5的个数,也相当于这个用户的高分数量。 -
计算precision(高分数量除以32)和recall(高分数量除以用户历史高分数量)以及f1值;计算训练集各个指标的平均值train_ave_precision,train_ave_recall,train_ave_f1;测试集的指标:train_ave_f1,test_ave_precision,test_ave_recall,test_ave_f1
-
保存training_steps的模型,W_list,b_list (‘…/data/result/result_log/20210725160757_0.0_demo_data’)。保存结果:
self.storage.append([train_ave_reward, train_ave_precision, train_ave_recall, train_ave_f1, test_ave_reward, test_ave_precision, test_ave_recall, test_ave_f1, ave_rmse]) -
输出结果:这里的0是训练次数,与training_steps相关,它只在train中更改;

然后就返回recommender中,开始调用train了!
train
- 每一个batch选的用户数=4000, 训练的时候每个用户采样的episode=16
- 循环4000次,从1~400(boundry_user_id)中随机选userID;嵌套循环16次,
self.env[i*self.sample_episodes_per_batch+j].reset(user_id),传入userID进行重置。(self.env()在初始化的时候,初始化了64000个)这个地方就是先选出4000个用户id,再重置该用户的前16个env,刚刚好64000. - 初始化ars:64000个 item_id,reward,statistic;给用户随机选item,然后获取reward,train_batch_size=64000
self.update_avalable_items(ars[0][0]),传入64000个itemid,目的是删除树中选过的item(爸爸和儿子都要删除?),①sampled_codes = self.id_to_code[sampled_items],从爸爸找儿子(64000,2) ②aval_val_tmp = np.tile(np.expand_dims(self.aval_val, axis=1), [1, self.train_batch_size, 1])(10,64000,11); ③ 开始循环,修改aval_val_tmp,并且run assign_aval_list,也就是赋值操作。
for i in range(len(sampled_codes)):code = sampled_codes[i]index = 0for c in code: # 爸爸和儿子辈分c = int(c)aval_val_tmp[c][i][index] -= 1index = self.child_num * index + 1 + c #
- 用0初始化rnn_state;step_count = 0;stop_flag = False;action_list = []
- 根据策略采样action,先赋值
feed_dict = {self.forward_action: ars[0][step_count],#长度为64000self.forward_statistic:ars[2][step_count],self.forward_reward: ars[1][step_count],self.forward_rnn_state: rnn_state}
run_list =[self.forward_sampled_action, self.rnn_state, self.update_aval_list],其中
① forward_sampled_action是查表操作,目的是将action索引转成数据集中的id;
② rnn_state是运行rnn函数,传入forward_ars和forward_rnn_state,输出[h,c];
③ update_aval_eval_list是删除了选过的item。赋值给sampled_action, rnn_stateaction_list.append(sampled_action),step_count += 1(最后加到了31),ars加[]- 又开始循环64000次,
reward = self.env[j].get_reward(sampled_action[j]),这里是返回选取的item的reward,共32个,每个长度为64000。也就是要衡量采样结果好不好了。 - 接下来标准化Q值, 就是在算累积收益
for i in reversed(range(len(qs))): # 折扣值c_reward = self.discount_factor * c_reward + qs[i]qs[i] = c_reward
- qs_mean_list 取平均;又对qs进行标准化。这里传入的matrix是(31,16)
def standardization(self, q_matrix):q_matrix -= np.mean(q_matrix)std = np.std(q_matrix)if std == 0.0:return q_matrixq_matrix /= stdreturn q_matrix
- 初始化rnn(2,64000,27)
- 强化学习更新!
for i in range(step_count):feed_dict = {self.forward_action: ars[0][i],self.forward_reward: ars[1][i],self.forward_statistic: ars[2][i],self.forward_rnn_state: rnn_state,self.cur_action: ars[0][i + 1],self.cur_q: qs[i]} # Q值 _, rnn_state = self.sess.run([self.train_op, self.rnn_state], feed_dict=feed_dict)
总结:传入采样生成的action,reward等记录(是为用户随机选item,得到reward;大小为batchsize),返回推荐结果(长度为64000),然后衡量好坏。
补充知识
这部分是遇到的一些没见过的或者是需要巩固的知识点:
函数
- Batch Size定义:一次训练所选取的样本数。Batch Size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况,假如你GPU内存不大,该数值最好设置小一点
configparser:用来读取配置文件的包配置文件的格式如下:中括号“[ ]”内包含的为section。section 下面为类似于key-value 的配置内容。- 读文件时,r,rb,w,wb等的含义:
‘r’:只读。该文件必须已存在。
‘r+’:可读可写。该文件必须已存在,写为追加在文件内容末尾。
‘rb’:表示以二进制方式读取文件。该文件必须已存在。
‘w’:只写。打开即默认创建一个新文件,如果文件已存在,则覆盖写(即文件内原始数据会被新写入的数据清空覆盖)。
‘w+’:写读。打开创建新文件并写入数据,如果文件已存在,则覆盖写。
‘wb’:表示以二进制写方式打开,只能写文件, 如果文件不存在,创建该文件;如果文件已存在,则覆盖写。
‘a’:追加写。若打开的是已有文件则直接对已有文件操作,若打开文件不存在则创建新文件,只能执行写(追加在后面),不能读。
‘a+’:追加读写。打开文件方式与写入方式和’a’一样,但是可以读。需注意的是你若刚用‘a+’打开一个文件,一般不能直接读取,因为此时光标已经是文件末尾,除非你把光标移动到初始位置或任意非末尾的位置。(可使用seek() 方法解决这个问题,详细请见下文Model 8 示例)
- 创建一个不含有重复值的列表,不要再用
list.append()方法了,因为要提前判断是否在列表内。可以采用set add()方法,用于给集合添加元素,如果添加的元素在集合中已存在,则不执行任何操作。 coo_matrix构建稀疏矩阵;coo_matrix((data, (i, j)), [shape=(M, N)]),data[:] 表示原始矩阵中的数据;i[:] 是行的指示符号,如row的第0个元素是0,就代表data中第一个数据在第0行;j[:] 是列的指示符号;如col的第0个元素是0,就代表data中第一个数据在第0列;总结一下,根据i和j的位置确定data的每个元素位于矩阵哪个位置。但是主要用来创建矩阵,因为 coo_matrix 无法对矩阵的元素进行增删改等操作- 之前将评分数据转换为矩阵都是先用numpy初始化空矩阵,再一个一个读取数据集填充。现在可以使用coo_matrix方法啦!
self.r_matrix = coo_matrix((rating[:, 2], (rating[:, 0].astype(int), rating[:, 1].astype(int)))).todok() todok():采用字典来记录矩阵中不为 0 的元素。字典的 key 存的是记录元素的位置信息的元组, value 是记录元素的具体值。 这篇文章总结的很好tqdm是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator)。- filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
filter(function, iterable)该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判断,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。 tf.nn.embedding_lookup函数:选取一个张量里面索引对应的元素。tf.nn.embedding_lookup(params, ids):params可以是张量也可以是数组等,id就是对应的索引。tf.stack用于拼接矩阵。tf.concat是沿某一维度拼接shape相同的张量,拼接生成的新张量维度不会增加。而tf.stack是在新的维度上拼接,拼接后维度加1。math.ceil()“向上取整”, 即小数部分直接舍去,并向正数部分进1。math.log(10,2)以2为底10的对数。tf.nn.embedding_lookup(params,id):根据id,寻找embeddings中的第id行。tf.cast()函数的作用是执行 tensorflow 中张量数据类型转换:cast(x, dtype, name=None),第一个参数 x: 待转换的数据(张量)第二个参数 dtype: 目标数据类型;第三个参数 name: 可选参数,定义操作的名称.- ·tf.random_normal()·函数用于从“服从指定正态分布的序列”输出指定维度的值。
tf.unstack()是一个矩阵分解的函数- PCA方法:
PCA(n_components=None, copy=True, whiten=False);
(1)n_components: int, float, None 或 string,PCA算法中所要保留的主成分个数,也即保留下来的特征个数,如果 n_components = 1,将把原始数据降到一维;
(2)copy:True 或False,默认为True,即是否需要将原始训练数据复制;
(3)whiten:True 或False,默认为False,即是否白化,使得每个特征具有相同的方差。
(4)方法 :fit(X,y=None)表示用数据X来训练PCA模型。函数返回值:调用fit方法的对象本身。比如pca.fit(X),表示用X对pca这个对象进行训练。n_components_返回所保留的特征个数
拓展:fit()可以说是scikit-learn中通用的方法,每个需要训练的算法都会有fit()方法,它其实就是算法中的“训练”这一步骤。 主成分分析(PCA)的概念很简单——减少数据集的变量数量,同时保留尽可能多的信息。
(5)fit_transform(X):用X来训练PCA模型,同时返回降维后的数据。 - 创建常量:创建一个常量tensor,按照给出value来赋值,可以用shape来指定其形状。value可以是一个数,也可以是一个list。
tf.constant(value,dtype=None,shape=None,name='Const',verify_shape=False
)
filter(function, iterable),过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换- gc.collect()可以清内存
ConfigParser模块在python中用来读取.conf配置文件,每个节可以有多个参数(键=值)tf.equal(x, y, name=None)逐个元素进行判断,如果相等就是True,不相等,就是False。
GRU
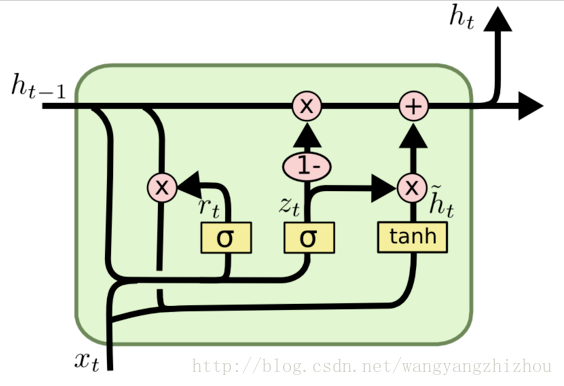
GRU是LSTM网络的一种效果很好的变体,它较LSTM网络的结构更加简单,而且效果也很好,因此也是当前非常流形的一种网络。GRU既然是LSTM的变体,因此也是可以解决RNN网络中的长依赖问题。
图中的 z t z_t zt和 r t r_t rt分别表示更新门和重置门。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门控制前一状态有多少信息被写入到当前的候选集 h t ~ \tilde{h_t} ht~上,重置门越小,前一状态的信息被写入的越少。
- 截断反向传播(truncated backpropagation)
在配置文件中看见“rnn truncated length”这个描述,不是很懂“截断”的意思,所以百度了一下。大概是指训练时的长度,应该和batch size差不多吧。 - 假设我们训练含有1000000个数据的序列,如果全部训练的话,整个的序列都feed进RNN中,容易造成梯度消失或爆炸的问题,所以解决的方法就是truncated backpropagation,我们将序列截断来进行训练(num_steps)。
报错
1.dictionary changed size during iteration:找了一个多小时,发现是传入字典的时候就出问题了!key值当中,int和str没有统一!!
这篇关于TPGR代码详解 Large-Scale Interactive Recommendation with Tree-Structured Policy Gradient的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





