本文主要是介绍带你从Spark官网啃透Spark Structured Streaming,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
By 远方时光原创,可转载,open
合作微信公众号:大数据左右手

本文是基于spark官网结构化流解读
Structured Streaming Programming Guide - Spark 3.5.1 Documentation (apache.org)
spark官网对结构化流解释
我浓缩了一些关键信息:
1.结构化流是基于SparkSQL引擎构建的可扩展且容错的流处理引擎。(也就是他摒弃了DStream)
2.可以像批数据一样处理流数据。可以使用Dataset/DataFrame API在Scala、Java、Python或R中流聚合、事件时窗口、流批数据join等操作。(Stream表是无界表)
3.通过检查点和预写日志确保端到端精确一次容错保证。(一条数据只被消费一次)
4.默认结构化流查询使用微批次处理作业引擎进行处理,并实现低至100毫秒的端到端延迟和精确一次的容错保证。
5.自Spark 2.3,引入了一种新的更低延迟处理模式,称为连续处理,它可以实现低至1毫秒的端到端延迟,并保证至少一次。(这个延迟基本和flink处理流无区别了)
基本概念:
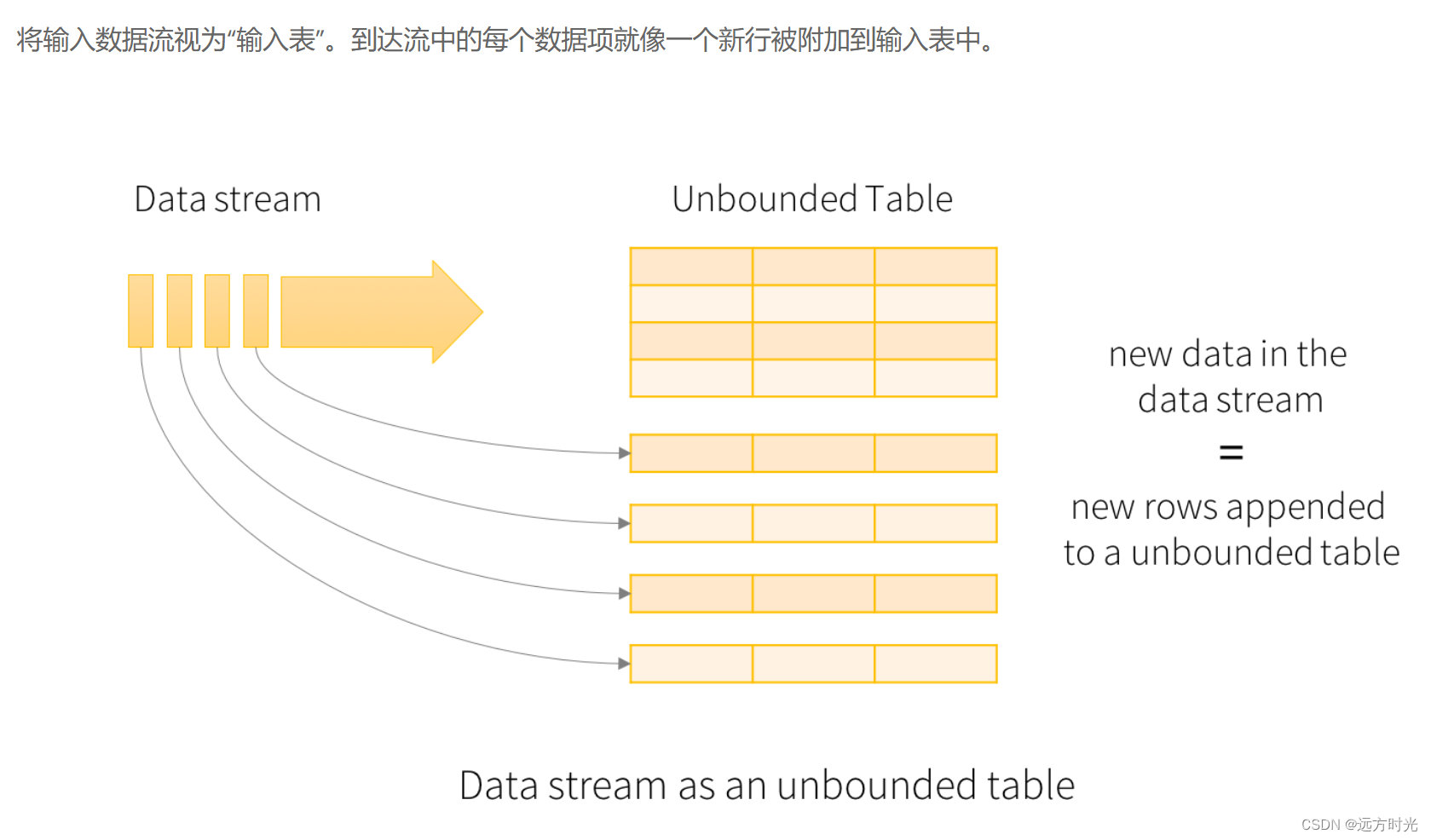
输入表
可以抽象的认为:消费的流数据,源源不断的追加到一张无界表中。
输出表
处理后的结果,比如下图中groupby($"word").count()
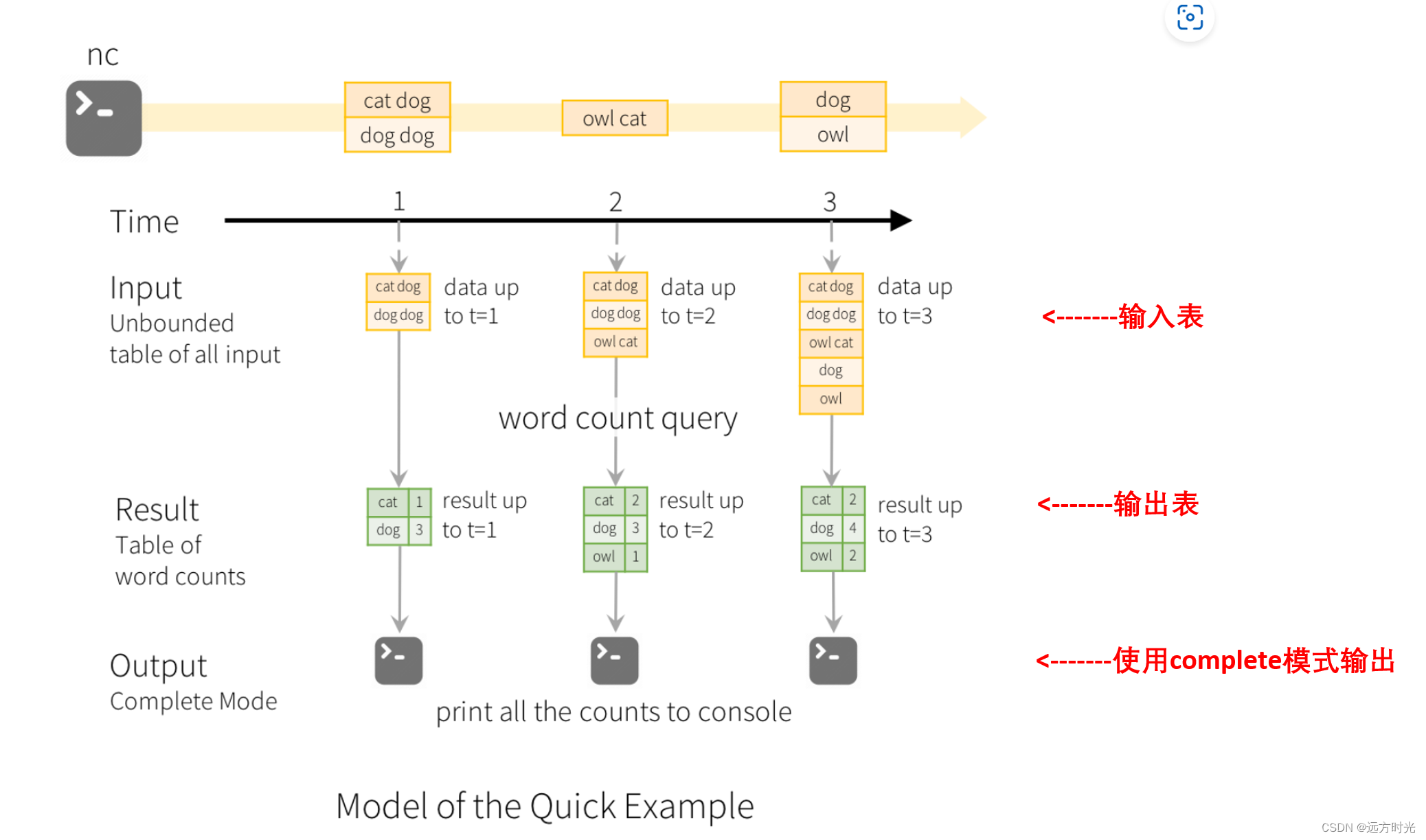
输出模式:
·完成模式(complete):整个更新的结果表将被写入外部存储。全部输出,必须要有聚合。
time1:
输入表:''cat dog dog dog''
-> groupby($"word").count()
-> 结果表输出:cat 1, dog 3
time2:
新增消息 "owl cat"
-> groupby($"word").count()
-> 结果表输出:cat 2, dog 3, owl 1
time3:
新增消息 "dog owl"
-> groupby($"word").count()
-> 结果表输出:cat 2, dog 4, owl 2
·追加模式(apend):自上次触发器以来,追加到结果表中的新增的行才会写入外部存储。仅适用于结果表中现有行预计不会更改。
time1:
输入表:''cat dog'' -> 不处理 -> 结果表输出:cat, dog
time2:
新增消息 ''fish'' -> 不处理 -> 结果表输出:fish
·更新模式(update):自上次触发器以来,在结果表中更新的行才会写入外部存储(自Spark2.1.1起可用)。如果查询不包含聚合,则相当于追加模式。
time1:
输入表:''cat dog dog dog''
-> groupby($"word").count()
-> 结果表输出:cat 1, dog 3
time2:
新增消息 "owl cat"
-> groupby($"word").count()
-> 结果表输出:cat 2, owl 1 (变化和新增输出,dog 3对比time1无变化不输出)
处理事件时间
{''id'':''8888888'', ''time'':''2024-03-04 19:36:30'',''data'':''****''}
事件时间是嵌入在数据本身中的时间,spark允许基于eventTime窗口聚合
时间窗口:
滚动窗口:窗口无重合,window($"timestamp", "5 minutes", "5 minutes")
滑动窗口:窗口有重合,window($"timestamp", "10 minutes", "5 minutes")
会话窗口:设有一个时间间隔(5分钟),结合下图看,12:09分后面5分钟,都没收到新数据,所以在12:14分窗口关闭

水位线解决延迟数据 (超级重点,面试爱问)
从 Spark 2.1 开始,支持水印或者叫水位线(watermark),一种窗口关闭延迟机制,用于解决部分乱序数据。
官网写的太长,我简化一下,你对着图看:
注:④抽象为一条数据(其事件时间为12:04的)
水位线 = 消费到曾经最晚一条数据的事件时间(max eventTime) - 允许延迟的时间(threshold)
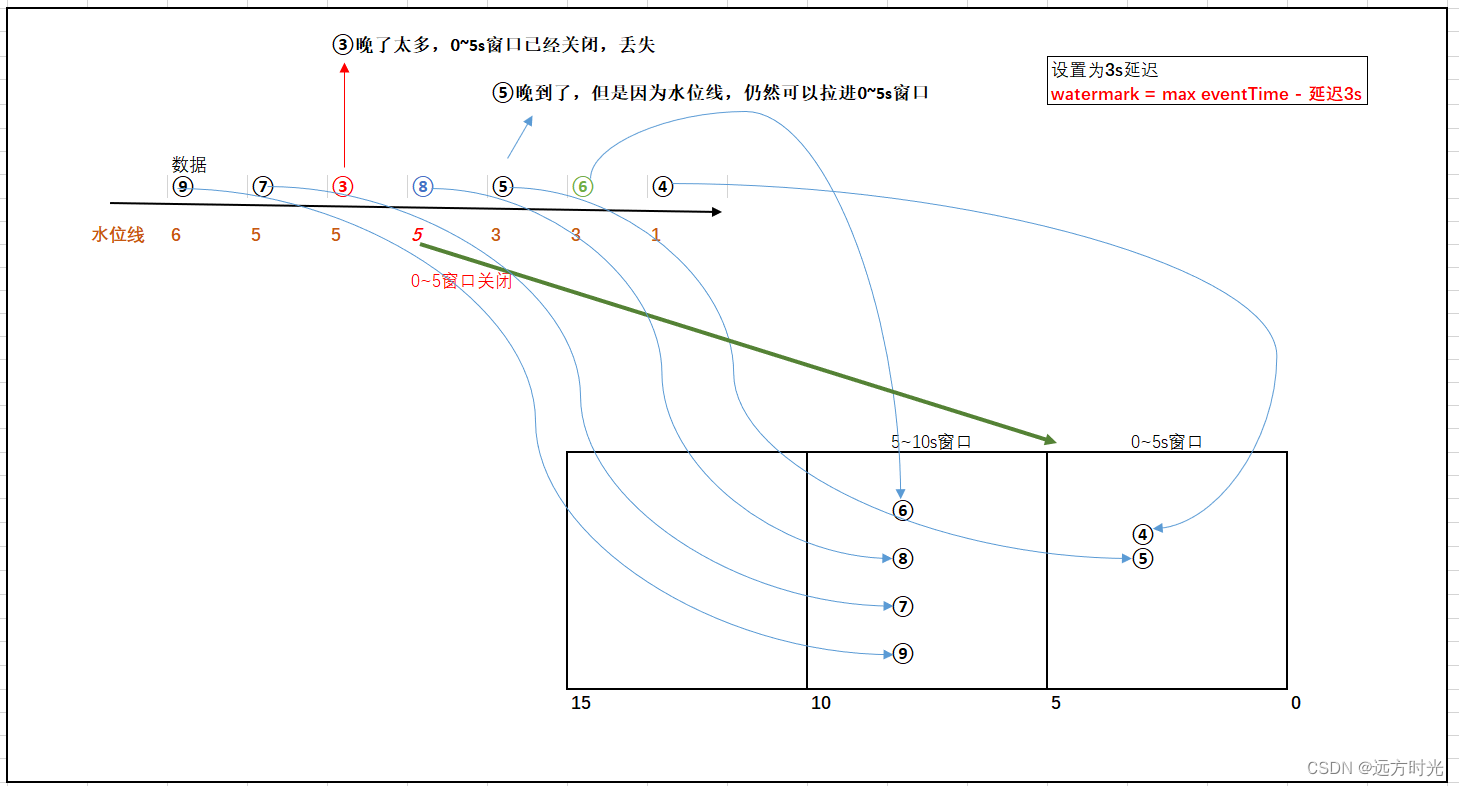
1)消费到④,拉倒0~5s窗口,watermark=4 - 3 = 1
2)消费到⑥,拉到5~10s窗口,watermark=6 - 3 = 3
3)消费到⑤,拉到5~10s窗口,⑤正常是会⑥之前被消费到,此时出现乱序,⑤它晚到了
如果没有设置水位线,消费到⑥的时候0~5s窗口就应该被关闭,⑤丢失
但是我们设置了3s水位线延迟机制,
此时水位线watermark = 6 - 3 = 3 (消费到曾经最晚的eventTime是⑥ - 3,而不是⑤ - 3),抽象理解为水位线只会上涨,不会下降
因为水位线机制,晚到的⑤仍然可以进入到0~5s窗口
只有当水位线>=5,这里5指的是时间窗口(0,5]右区间,0~5s窗口才会关闭
4)消费到⑧,拉倒5~10s窗口,watermark=8 - 3 = 5,那么0~5s窗口此时正式关闭
5)消费到③,0~5s窗口已经关闭,这条数据晚太多了,被丢失掉了
水位线用来鉴别延迟数据的有效性:在水位线以内的数据都是有效数据参与窗口的计算,水位线以外的数据则为过期数据丢弃
2024-03-04 22:44,太困了,明天我再写后续的
这篇关于带你从Spark官网啃透Spark Structured Streaming的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![[大数据之Spark]——快速入门](/front/images/it_default.jpg)