本文主要是介绍论文笔记11:Relational inductive biases, deep learning, and graph networks翻译笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关系归纳偏置、深度学习和图网络
DeepMind; Google Brain; MIT; University of Edinburgh
参考
- https://zhuanlan.zhihu.com/p/40733008
摘要
人工智能近几年大火起来,在计算机视觉、自然语言处理、控制和决策等关键领域取得重大进展。这在一定程度上归因于廉价的数据和计算资源,它们符合深度学习的本质优势。然而,人类智力的许多典型特征,都是在不同的环境压力下发展形成的,目前的方法仍然无法达到这一水平。尤其是从个体经验泛化出一些可以广泛适用群体的特征,其超越了个人经验的概括的范畴,这对现代人工智能来说仍然是一个艰巨的挑战。
论文认为:组合泛化(combinatorial generalization)是AI中最首要的任务,要达到这个目的,结构化表征(structured representations)和计算能力(computations)是关键。如生物学中将先天基因和后天孕育结合在一起,我们必须摒弃在”手动设计结构(hand-engineering)“和”端到端(end-to-end)”只能二选一的错误做法,相反,应该提倡将两者优势互补的方法。
我们将探讨如何在深度学习体系结构中使用关系归纳偏差来促进对实体、关系和组合它们的规则的学习。对此,我们提出了一种可在AI中应用的新模块,即图网络。图网络提供一个用来操作结构化知识并处理结构上的行为的接口。我们对图网络如何实现关系推理(relational reasoning)和组合泛化(combinatorial generalization)进行了深入讨论,这为更复杂、可解释性更强和更灵活的推理模式奠定了基础。作为本文的伴生品,我们还发布了一个用于构建图网络的开源软件库,并演示了如何在实践中使用它们。
1. 研究背景
人类智慧的一个重要特征是具有能够无限地利用有限的手段的能力(Humboldt,1836; Chomsky, 1965) 。比如一小组元素(比如单词)可以被无限有效地组合(比如变成一条新句子)。这反映了组合泛化的原则,即从已知的模块构建新的推论、预测和行为。在这里,我们探讨如何通过给结构化表示和计算(特别是操作在图上的系统)的学习过程加上偏差对来提高现代人工智能的组合泛化能力。
人类进行组合泛化的能力在很大程度上取决于我们强大的表示关系结构和进行推理的认知机制。我们将复杂系统表示为实体和实体之间交互的组合(Navon, 1977; McClelland and Rumelhart, 1981;Plaut et al., 1996; Marcus, 2001; Goodwin and Johnson-Laird, 2005; Kemp and Tenenbaum, 2008), 比如判断一个随机的对象栈是否稳定(Battaglia et al., 2013) 。我们使用层次结构来抽象细粒度差异,并捕获表示(representations)和行为之间的更一般的共性(Botvinick, 2008; Tenenbaum et al., 2011),例如物体的一部分,视觉场景中的某个物体,城镇中的社区和乡村中的城镇等。我们一般通过熟悉的技巧和方法来解决新问题(Anderson, 1982),例如,通过组合熟悉的旅行计划和目的地去一个新的地点,比如“坐飞机旅行”,“去圣地亚哥”,“在哪吃”和“一个印度餐厅”。我们通过调整两个区域之间的关系结构来进行类比,并基于对一个领域的相应知识,对另一个领域进行推理(Gentner and Markman, 1997; Hummel and Holyoak, 2003) 。
《The Nature of Explanation 》(1943)一文将世界的构成结构与人类内心的思维模式联系了起来:
人类心理模型与它所模仿的现实过程有着相似的关系结构,我所说的“关系结构”并不是指模型中某个模糊的非物理实体,而是一个可行的物理模型,其工作方式与和它并行的现实结构相同。显然,物理现实世界是由一些基本类型的单元构成的,这些单元的基本特征决定了许多非常复杂现象的特性。
也就是说,世界是由不同部分组成的,或者说,我们可以用可组成的角度来理解它。在学习时,我们要么将新知识融入现有的结构化表示;要么调整结构本身,以更好地同时适应(并利用)新知识和旧知识(Tenenbaum et al.,2006; Griffiths et al., 2010; Ullman et al., 2017)。
自人工智能诞生以来,如何构建具有组合泛化特性的人造系统一直是其核心问题,并且是许多结构化方法的核心,包括逻辑、语法、经典规划、图模型、因果推理、贝叶斯非参数和概率编程(Chomsky, 1957; Nilsson and Fikes, 1970; Pearl, 1986, 2009; Russell and Norvig, 2009; Hjort et al., 2010; Goodman et al., 2012; Ghahramani, 2015) 。整个子领域都专注于显式的以实体和关系为中心的学习,比如关系强化学习(Dˇzeroski et al., 2001) 和统计推断学习(Getoor and Taskar, 2007) 。在过去,结构化方法对机器学习如此重要的一个关键原因是数据和计算资源过于昂贵,因此结构化方法的强归纳偏差所带来的样本复杂度的提高非常有价值。
与过去人工智能的方法形成对比,现代深度学习方法(LeCun et al., 2015;Schmidhuber, 2015; Goodfellow et al., 2016) 经常遵循“端到端”的设计哲学(端到端指的是输入是原始数据,输出是最后的结果,原来输入端不是直接的原始数据,而是在原始数据中提取的特征,[参考文章](什么是 end-to-end 神经网络? - 张旭的回答 - 知乎
https://www.zhihu.com/question/51435499/answer/129379006)),强调最小的先验表示和计算假设,并试图避免明确的结构设计和和其他手动设计。这一现象符合目前丰富并且廉价的数据和计算资源现状,这使得使用采样效率来换取更灵活的学习模型是一个非常合理的选择。在许多具有挑战性的领域,比如从图像分类(Krizhevsky et al., 2012;Szegedy et al., 2017)到自然语言处理 (Sutskever et al., 2014; Bahdanau et al., 2015),to game play (Mnih et al., 2015; Silver et al., 2016; Moravˇc´ık et al., 2017) ,都带来了引人注目的快速进展,这也恰恰是对这一最小原则的有力证明。一个突出的例子是语言翻译领域,sequence-to-sequence方法(Sutskever et al., 2014; Bahdanau et al., 2015) 已经证明不使用显式的语法解析树或语言学实体之间的复杂关系结果也能非常有效。
尽管深度学习取得了成功,但一些不可忽视的缺点(Marcus, 2001; Shalev-Shwartz et al., 2017; Lake et al., 2017; Lake and Baroni, 2018; Marcus, 2018a,b; Pearl, 2018; Yuille and Liu, 2018) 已经成为它在复杂语言和场景理解、结构化数据推理、迁移学习和小样本学习等方面的应用所面临的关键问题。这些挑战要求方法具备组合泛化能力,因此避免组合性和显式结构的方法很难奏效。
深度学习的连接主义者(Rumelhart et al., 1987) 的前辈们正面临着来自结构、符号主义者的类似批评(Fodor and Pylyshyn, 1988; Pinker and Prince, 1988), 当然也有人做出了建设性的努力(Bobrow and Hinton, 1990;马科斯(2001),直接并且谨慎地应对此挑战。大量用于表征和推理结构化对象的创新性亚符号方法被发明出来并用于诸如类比推断、语言分析、符号处理和其他形式的关系推理领域(Smolensky, 1990; Hinton, 1990;Pollack, 1990; Elman, 1991; Plate, 1995; Eliasmith, 2013)。同时关于大脑如何工作的更综合的理论也被研究发表出来(Marcus, 2001) 。这些工作也有助于推动最近火热的基于分布式理论的深度学习的进展,比如使用分布式的向量表示来捕捉文本中的丰富语义内容(Mikolov et al., 2013; Pennington et al., 2014) 、图(Narayanan et al., 2016, 2017) 、代数和逻辑表达式(Allamanis et al., 2017; Evans et al., 2018) 和程序(Devlin et al., 2017;Chen et al., 2018b) 。
我们认为,现代人工智能发展的关键是将组合泛化作为首要任务,我们提倡采用综合方法来实现这一目标。就像生物学无法在先天和后天之间同时选择一样(它利用自然和养育的共同作用,建立了一个整体,这个整体大于各部分的总和),我们认为结构性和灵活性在某种程度上也是是可以一致或相容的,并希望两者之间的优势可以互补。近期有很多基于结构的方法和深度学习原则相结合的例子(e.g., Reed and De Freitas, 2016; Garnelo et al., 2016; Ritchie et al., 2016; Wuet al., 2017; Denil et al., 2017; Hudson and Manning, 2018), 我们看到,通过充分利用人工智能工具箱来综合新技术,并将当今最好的方法与那些在数据和计算性能比较高的方法结合起来,前景十分广阔。
最近,深度学习和结构化方法开始相结合,其侧重于对显式结构化数据(特别是图)进行推理(e.g. Scarselli et al., 2009b; Bronstein et al., 2017; Gilmer et al., 2017; Wang et al., 2018c; Li et al., 2018; Kipf et al., 2018; Gulcehre et al., 2018)。这些方法的共同之处在于能够对离散实体和它们之间的关系进行计算。和传统方法的区别是实体和关系的表示和结构(以及相应的计算)可以通过学习得到,不需要提前指定它们,减轻了负担。更重要的是,在特定的体系结构假设下,这些带有很强的关系归纳偏置的方法指导了用于学习实体和关系的方法(Mitchell, 1980) 。在用于学习实体和关系的方法中,我们和其他许多人都认为(Spelke et al.,1992; Spelke and Kinzler, 2007; Marcus, 2001; Tenenbaum et al., 2011; Lake et al., 2017; Lake and Baroni, 2018; Marcus, 2018b) 启发(suggest)是发展类人智力的基本要素。
Box 1: 关系推理
我们将结构(structure)定义为一组已知模块组成的产品。结构化表示(Structured representations)代表这个组合整体(例如元素的排列的所有结果),结构化计算(structured computations)在组成元素以及这些元素构成的整体上进行操作。因此,关系推理涉及操作实体和关系的结构化表示,这个表示使用一定的规则来表示它们之间如何组合计算。我们使用术语来解释来自认知科学、理论计算机科学和人工智能的概念,如下所示:
- **实体(entity)**是具有属性的元素,例如有大小和质量的物理物体
- **关系(relation)**是实体之间的属性。两个对象之间的关系可能包括大小相同、重量大于和距离多少等。关系本身也可以有属性,比如对于一个关系将"重X倍以上"作为其一个属性,属性X决定关系的相对权重阈值是否符合条件(结果是否重x倍以上)。关系还可能受数据全局上下文影响,比如对于一块石头和一根羽毛来说,在不同环境下,石头的下降速度对比羽毛下降的速度,在空气中比在真空中要快得多。这里我们主要关注实体之间的成对关系。
- **规则(rule)**可以看做一个函数(类似一个非二进制逻辑谓词),它将实体和关系映射到其他实体和关系,比如实体X是否更大或者实体X比实体Y更重吗之类的大小比较。这里我们考虑的规则接收一个或两个参数(一元和二元),并返回一元属性值。
举一个机器学习中关系推理的说明性例子,图模型(Pearl,1988; Koller and Friedman, 2009)通过在随机变量之间建立明确的的随机独立条件来表示复杂的联合分布。这些模型取得了很大成功,因为它们捕捉了许多组成真实世界生成过程基础的稀疏结构,并且支持高效的学习和推理。例如,隐马尔可夫模型的隐藏状态约束条件与前一个时间步骤中给定的其他状态相互独立。且给定当前时间步长的隐藏状态,观测值是有条件的独立的,这与许多真实世界因果过程的关系结构很好的相匹配。显式地表达变量之间的稀疏依赖关系为各种有效的推理和推理算法提供了条件。比如消息传递,其应用了图模型中跨区域的公共信息传播过程,由此产生了一个可组合的、部分可并行的推理过程,这可以应用于不同尺寸和形状的图模型。
在论文的其余部分,我们通过各种深度学习方法的关系归纳偏差来检视它们的合理性,结果表明现有方法通常带有关系假设,这些假设并不总是显式的或明显看出的。然后,我们提出了一个基于实体和关系进行推理的一般框架,我们将其称为图网络:用于统一和扩展现有的对图进行操作的方法,并描述了如何使用图网络的模块构建功能强大的架构。我们还发布了一个用于构建图网络的开源库,可以在这里找到:github.com/deepmind/graph_nets。
2. 关系归纳偏差
box2:归纳偏差(Inductive biases)
学习是通过观察和与世界进行交互来理解有用知识的过程。通过搜索解决方案空间,希望提供更好的数据解释或获得更高的回报。但是在很多情况下,有很多解决方案都一样好(Goodman, 1955) 。归纳偏差允许学习算法对某个解决方案(或解释)优先考虑,并且与观测数据无关(Mitchell,1980) 。在贝叶斯模型中,归纳偏差通常通过先验分布的选择和参数化来表示(Griffiths et al., 2010)。在其他情况下,归纳偏差可能是为了避免过拟合而添加的正则化项(McClelland, 1994),或者它可能被编码在算法本身的体系结构中。归纳偏差通常用灵活性来换取样本复杂度的提高,可以用偏差-方差权衡来理解(Geman et al., 1992) 。理想情况下,归纳偏差既能在不显著降低性能的情况下改进解决方案的搜索性能,也能帮助找到泛化良好的解决方案。然而,错误使用的归纳偏差也可能因为引入太强的约束导致性能下降。
归纳偏差可以表达关于数据生成过程或解决方案空间的假设。例如,将一维函数与数据拟合时,线性最小二乘满足逼近函数为线性模型的约束,近似误差在平方惩罚项下应该是最小的。这反映了这样一个假设,即可以简单地解释数据生成过程,作为加性高斯噪声破坏的线性过程。类似地,L2正则化优先考虑参数值较小的解决方案,并能得到原本难以解决的问题的唯一解和全局结构。这可以解释为一个关于学习过程的假设:当解决方案之间的模糊性降低时,寻找较好的解决方案将更容易。注意,这些假设不必是显式的,它们只是反映了一个模型或算法如何与世界进行交互。
个人注解:
归纳偏差是一个关于机器学习算法的目标函数的假设,其实就是模型的指导规则。其实这个指的就是目标函数评分的标准。 我们利用机器学习算法要做的是,利用一个学习器,通过学习样本使得学习器对于任意输入(可以不包含在训练数据中)可以产生最正确的预测。那么,这个假设就决定了在面对未知数据下如何去作出判断。例如,在线性回归中,作出的假设(归纳偏差)是,输出与输入是线性的,可以同时应用于训练和预测,是一种超参数(因为是模型的一部分)。
上面举的例子是线性回归,还有一种是决策树,决策树的假设就是:(1)优先选择较短的树而不是较长的(2)选择那些信息增益高的属性里根节点较近的树。这里利用了两个假设,相比之下,神经网络的假设是相当弱的。举个例子,分类神经网络模型的假设是,将输入通过非线性函数进行映射得到结果,正确的类别具有较高的softmax值。
归纳偏差的种类:
- 最大条件独立性(conditional independence):如果假设能转成贝叶斯模型架构,则试着使用最大化条件独立性。这是用于朴素贝叶斯分类器(Naive Bayes classifier)的偏置。
- 最小交叉验证误差:当试图在假设中做选择时,挑选那个具有最低交叉验证误差的假设,虽然交叉验证看起来可能无关偏置,但天下没有免费的午餐理论显示交叉验证已是偏置的。
- 最大边界:当要在两个类别间画一道分界线时,试图去最大化边界的宽度。这适用于支持向量机的偏置。这个假设是不同的类别是由宽界线来区分。
- 最小描述长度(Minimum description length):当构成一个假设时,试图去最小化其假设的描述长度。假设越简单,越可能为真的。见奥卡姆剃刀。
- 最少特征数(Minimum features):除非有充分的证据显示一个特征是有效用的,否则它应当被删除。这是特征选择(feature selection)算法背后所使用的假设。
- 最近邻居:假设在特征空间(feature space)中一小区域内大部分的样本是同属一类。给一个未知类别的样本,猜测它与它最紧接的大部分邻居是同属一类。这是用于最近邻居法的偏置。这个假设是相近的样本应倾向同属于一类别。
机器学习和人工智能中的许多方法都具有使用关系归纳偏差进行关系推理(box1)的能力。虽然这不是一个精确、正式的定义,但我们通常用这个术语来指代归纳偏差(box2),它对学习过程中实体之间的关系和交互施加约束。
近年来,创新的新型机器学习体系结构迅速涌现,研究者通常使用基本构建模块形成更复杂的结构,比如层次计算结构(这种深度写作模式在深度学习中是普遍存在的,也是“深度”的来源)和图(最近的方法(Liu et al., 2018),甚至通过学习图的生成修改过程实现了构建的自动化)。对于构建单元来说,例如”全连接层“堆叠形成“多层感知器”,“卷积层”堆叠形成“卷积神经网络”。一般来说,图像处理网络的标准结构是MLP+CNN。这种层的组合提供了一种特殊类型的关系归纳偏差,即分层处理。分阶段进行算,通常导致输入信号中信息之间的相互作用越来越弱。正如我们下面所探讨的,构建单元本身也带有各种关系归纳偏差(表1)。虽然超出了本文的研究范围,但在深度学习中也使用了各种非关系归纳偏差。例如,非线性激活函数,权重衰减,dropout(Srivastava et al., 2014),batch normalization 和 layer normalization(Ioffe and Szegedy, 2015; Ba et al., 2016) ,数据增强,课程学习(参考连接)和优化算法,所有这些都对学习的过程和结果做出了约束。
表1:标准深度学习组件中的各种关系归纳偏差
| 组件 | 实体 | 关系 | 归纳偏置 | 不变性 |
|---|---|---|---|---|
| 全连接 | 神经元 | all-to-all | 弱 | - |
| 卷积 | 网格元素 | local | 局部性 | 空间平移 |
| 循环 | 时间步长 | sequential | 序列性 | 时间平移 |
| 图网络 | 节点 | edges | 任意性 | 节点,边排列 |
为了探讨各种深度学习方法中表达的关系归纳偏差,我们必须确定几个关键因素,类似于Box1中的内容:什么是实体,什么是关系,什么是组合实体和关系的规则以及如何计算它们的隐含信息?
在深度学习中,实体和关系通常表示为分布式向量表示,规则是神经网络函数逼近优化。但是,实体、关系和规则的明确形式在不同架构中是不同的。为了理解不同架构之间的这些差异,我们可以进一步探究它们如何支持关系推理:
- 规则函数的参数(例如,提供哪些实体和关系作为输入)
- 规则函数如何在图的计算中重用或共享(例如,跨越不同的实体和关系,跨越不同的时间或处理步骤,等等)
- 体系结构如何定义分布式向量表示之间的交互与不交互之间的对比(例如,通过使用规则处理相关的一些实体与单独处理实体结果进行对比)
2.1 标准深度学习构建模块中的关系归纳偏差
2.1.1 全连接层
最常见的构建块就是全连接层了(Rosenblatt, 1961)。通常实现方式为输入为向量的非线性函数,输出为向量的每个元素(或unit)与权重向量之间的点积,然后是一个附加的偏置项,最后是一个非线性项,如修正线性单元(ReLU)。因此,实体是网络中的神经元,关系是all-to-all(i层的所有神经元都和j层的所有神经元连接),规则由权重和偏差决定。规则的参数是完整的输入信号,没有重用,也没有信息隔离(如图1a)。因此,全连通层中的隐式关系归纳偏差非常弱:所有输入单元都可以相互作用来确定任何输出单元的值,并且输出之间相互独立(表1)。
2.1.2 卷积层
另一个常见的构建块是卷积层(Fukushima, 1980; LeCun et al., 1989) 。它是通过将一个输入向量或张量与具有相同秩的核进行卷积来实现的,加入了偏置项,并使用了非线性点乘。这里的实体仍然是单独的神经元(或者是网格元素,比如像素),但是关系更加稀疏。全连接层和卷积层之间的差异带来了一些重要的关系归纳偏差:局部性和平移不变性(图1b)。局部性反映了关系规则的参数是那些在输入信号的坐标空间中彼此非常接近的实体,不包括远距离的实体。平移不变性反映了同一规则在输入之间的重用。这些偏差对处理图像数据非常有效,因为图像的局部邻居之间的协方差(其随着距离的增加而减小,因为统计数据在图像上基本上是不变的(表1))很大。

图1:常见的深度学习构建块中的重用和共享。(a)全连接层,所有的权重都是独立的,没有共享(b)卷积层,局部核函数在输入中被重用多次,共享的权重由相同颜色的箭头表示©循环层,相同的激活函数在不同的处理步骤中重用。
2.1.3 循环层
第三个常见的构建块是循环层(Elman, 1990) ,其实现是基于时间序列的。在这里,我们可以将每个处理步骤的输入和隐藏状态视为实体,以及在前一步隐藏状态基础上构建的隐藏状态和当前输入的马尔可夫依赖作为关系。组合实体的规则使用的是每一步的输入和隐藏状态作为参数来更新隐藏状态。规则在每个步骤中都被重用(如图1c),这反映了时间不变性的关系归纳偏差(类似CNN的空间平移不变性)。例如,一系列物理事件序列的结果应该依赖于时间。RNNs还可以通过马尔可夫结构使得序列具有局部偏置性(表1)。
2.2 集合和图上的计算
虽然标准的深度学习工具包包含各种形式的关系归纳偏差的方法,但是没有“默认的”可以在任意关系结构上通用的深度学习组件。我们需要能够显式表示实体和关系的模型,以及为了计算它们之间的交互关系而发现规则的学习算法,以及基于数据构建它们的方法。重要的是,实体(如对象和代理)没有自然的顺序,但顺序可以由它们之间关系的属性来定义。例如,一组对象的大小关系可以用来排序,它们的质量、年龄、毒性和价格也是如此。排序的不变性(除了关系中)是一个应该由用于关系推理的深度学习组件反映出来的属性。
集合是系统的一种自然表示方式,系统由未定义顺序或不相关的实体描述。值得注意的是,它们的关系归纳偏差不是来自于某物的存在,而是来自于某物的不存在。为了对插图进行说明,考虑这样一个任务:预测由n个行星组成的太阳系中心的质量,其属性(例如质量、位置、速度等)定义为 { x 1 , x 2 , … , x n } \{x_1, x_2, \dots, x_n \} {x1,x2,…,xn}。对于这样的计算,行星的顺序并不重要,因为状态只能用聚集结果的平均来描述。然而,如果我们要用MLP来完成这项任务,对特定输入 { x 1 , x 2 , … , x n } \{x_1, x_2, \dots, x_n \} {x1,x2,…,xn}进行学习预测,没必要转换为不同顺序的相同输入 { x n , x 1 , … , x 2 } \{x_n, x_1, \dots, x_2\} {xn,x1,…,x2}的预测任务。因为有n!这种可能的排列,最差情况下,MLP可以将不同顺序的输入看作是完全不同的,因此需要一个指数级别的输入/输出训练例子来学习一个近似函数。处理这种组合爆炸的一种方法是只允许模型进行基于对称函数且依赖于输入的属性的预测。这可能意味着需要计算每个共享对象的特征 { f ( x 1 ) , … , f ( x n ) } \{f(x_1), \dots, f(x_n)\} {f(x1),…,f(xn)} ,这些特征用对称的方式聚合在一起(例如,取它们的平均值)。这种方法是深层集合(Deep Sets)和相关模型的本质(Zaheer et al.,2017; Edwards and Storkey, 2016; Pevn`y and Somol, 2017),我们将在第4.2.3节中进行进一步探讨。

图2:不同的图结构表示。(a)一种分子,其中每个原子都表示为一个节点,边对应于原子之间的键(e.g. Duvenaud et al., 2015) 。(b)一种质量弹簧系统,其中绳索由一系列质量点定义,这些质量点在图中表示为节点(e.g.Battaglia et al., 2016; Chang et al., 2017) 。©一个n-body系统,其中的bodies是节点,以此为基础的图是完全连通的(e.g. Battaglia et al., 2016; Chang et al., 2017)。(d)刚体系统,其中球和壁是节点,图定义了球之间、球和壁之间的相互作用(e.g. Battaglia et al., 2016; Chang et al., 2017)。(e) 一个句子,其中的单词对应于树上的叶子,其他节点和边可以由解析器得来(e.g. Socher et al., 2013) 。另外,也可以使用完全连通的图(e.g. Vaswani et al., 2017) 。(f)一张图,它可以分解为与全连通图中的节点相对应的图像块(e.g. Santoro et al., 2017; Wang et al., 2018c)。
当然,在许多问题中,排列不变性并不是底层结构的唯一重要形式。例如,集合中的每个对象都可能受到与集合中其他对象成对交互带来的影响(Hartford et al., 2018) 。在前面的行星场景中,考虑一个预测每颗行星在一段时间间隔后的位置的任务, Δ t \Delta t Δt。在此场景中,使用对信息进行聚合、平均的手段已经不够看了,因为每颗行星的运动都取决于其他所有行星对它施加的力。相反,我们可以计算每个对象的状态为$x{^{’}}{_i} = f(x_i , \sum{_j}g(x_i, x_j )) 。 其 中 。其中 。其中g 计 算 第 j 颗 行 星 对 第 i 颗 行 星 的 引 力 , 计算第j颗行星对第i颗行星的引力, 计算第j颗行星对第i颗行星的引力,f$可以计算第i颗行星的未来状态,这是由力和动力决定的。由于系统的全局置换不变性,我们在任何地方都可以使用相同的g;但是,它还支持不同的关系结构,因为g现在接受两个参数而不是一个。
上面的太阳系例子说明了两个相关的结构:一个是结构中完全不包含关系,另一个是结构包含成对的关系。然而许多现实中的系统(比如图2)的关系结构是这两种极端的折衷,一些实体对有一对关系,其他的实体对可能缺少一条关系,不成对。在太阳系的例子中,如果这个系统是由行星和它们的卫星组成的,人们可能会忽略不同行星的卫星之间的相互作用,再对它进行近似模拟。实际上,这意味着只计算一些成对对象之间的交互,例如 x ′ i = f ( x i , ∑ j g ( x i , x j ) ) , δ ( i ) ⫅ { 1 , … , n } x{^{'}}{_i} = f(x_i , \sum{_j}g(x_i, x_j )) , \delta(i)\subseteqq\{1, \dots,n\} x′i=f(xi,∑jg(xi,xj)),δ(i)⫅{1,…,n}是节点i周围的邻居集合。这和一个图对应,因为第i个对象只与其他对象组成的子集进行交互,即它的邻居。注意,更新后的状态仍然不依赖邻域的顺序。
通常,图是支持任意(成对)关系结构的表示形式,对图上的计算提供了强大的关系归纳偏差,但这超出了卷积层和循环层能够提供的关系归纳偏差的能力。
3. 图网络
十多年来,基于图的神经网络及其计算方法得到了广泛的发展和探索(Gori et al., 2005; Scarselli et al., 2005, 2009a; Li et al., 2016) ,近年来在范围和受欢迎程度上也迅速增长。在下一小节中,我们将调查关于这些方法的文献,然后在剩下的小节中,我们介绍了我们的图网络框架,它概括并扩展了该领域的几项工作。
3.1 背景
图神经网络模型家族(Gori et al., 2005; Scarselli et al., 2005, 2009a; Li et al.,2016) 在不同的问题领域进行了探索,横跨监督、半监督、无监督和强化学习。它们在包含丰富关系结构的任务(如视觉场景理解任务(Raposo et al., 2017; Santoro et al., 2017) 、小样本学习(Garcia and Bruna, 2018) )中非常有效。它们也被用于物理系统的动力学(Battaglia et al., 2016; Chang et al., 2017; Watters et al., 2017;van Steenkiste et al., 2018; Sanchez-Gonzalez et al., 2018) 和多智能体系统(Sukhbaataret al., 2016; Hoshen, 2017; Kipf et al., 2018) ,预测分子的化学性质(Duvenaud et al., 2015; Gilmer et al., 2017) ,预测道路交通流量(Li et al., 2017; Cui et al.,2018) ,对图像和视频进行分类和分割(Wang et al., 2018c; Hu et al., 2017) ,三维网格和点云(Wang et al., 2018d) ,对图像中的区域进行分类(Chen et al., 2018a) ,半监督文本分类(Kipf and Welling, 2017) ,机器翻译(Vaswani et al., 2017; Shaw et al., 2018; Gulcehre et al., 2018)。它们也被用于无模型(Wang et al., 2018b) 和有模型(Hamrick et al., 2017; Pascanu et al., 2017;Sanchez-Gonzalez et al., 2018) 的连续控制,用于无模型强化学习(Hamrick et al., 2018; Zambaldi et al., 2018) 以及更经典的规划方法(Toyer et al.,2017) 。
许多传统的计算机科学问题,比如对离散实体和结构的推理,已经探讨了可以用图神经网络解决组合优化(Bello et al., 2016; Nowak et al., 2017; Dai et al., 2017), 布尔可满足性问题(Selsam et al., 2018) 、程序表示与验证(Allamanis et al., 2018; Li et al., 2016) 、细胞自动机和图灵机的建模(Johnson, 2017)、在图模型中执行推理(Yoon et al., 2018) 等。最近的工作也集中于建立图的生成模型(Li et al.,2018; De Cao and Kipf, 2018; You et al., 2018; Bojchevski et al., 2018) 、图嵌入的无监督学习(Perozzi et al., 2014; Tang et al., 2015; Grover and Leskovec, 2016; Garc´ıa-Dur´an and Niepert, 2017) 。
上面所引用的工作并不是一个大而全的清单,而只是提供了一个具有代表性的某一方面,图神经网络已经被证明是有用的。我们向有兴趣的读者列出了一些现有的综述,这些综述更深入地研究了图神经网络的主要内容。特别的,Scarselli等人(2009a)提供了早期图神经网络方法的权威概述。Bronstein等(2017)对非欧几里德数据的深度学习进行了很好的调查,并探索了图神经网络、图卷积网络以及相关的光谱方法。最近,Gilmer等(2017)引入了消息传递神经网络(message-passing neural network, MPNN),它通过类比图模型中的消息传递机制,统一了各种图神经网络和图卷积网络方法(Monti et al., 2017; Bruna et al., 2014; Henaff et al., 2015; Defferrard et al., 2016;Niepert et al., 2016; Kipf and Welling, 2017; Bronstein et al., 2017) 。同样地,Wang等(2018c)介绍了非局部神经网络(NLNN),它过类比计算机视觉和图模型中捕捉信号的长期依赖关系的方法统一了各种“self-attention ”风格的方法。
3.2 图网络(GN)模块
接下来我们提出了我们的图网络(GN)框架,它定义了一类函数,用于在图结构表示上进行关系推理。我们的GN框架对各种图神经网络、MPNN和NLNN方法进行了概括和扩展(Scarselli et al., 2009a; Gilmer
et al., 2017; Wang et al., 2018c) ,并支持从简单的构建块构建复杂的体系结构。注意,我们避免在”graph network”标签中使用术语“neural“,来说明它们可以用神经网络以外的函数来实现,虽然这里我们的重点是神经网络的实现。
Box3:我们对于“图”的定义

这里我们使用“graph”来表示具有全局属性的有向、有属性的多重图。在我们的术语中,节点定义为 v i v_i vi,边定义为 e k e_k ek,全局属性定义为 u u u。另外,对于边 k k k,使用 s k s_k sk和 r k r_k rk分别表示发送节点和接收节点。更准确地说,我们将这些术语定义为:
- Directed 有向的:单向边,从”发送方“节点到“接收方”节点
- Attribute 属性:可以编码为向量、集合甚至是另一个图的属性。
- Attributed 属性化的:边和顶点都有与其相关联的属性。
- Global attribute 全局属性:graph-level的属性
- Multi-graph 多重图 :顶点之间可以有不止一条边,包括自连边。
图2显示了我们可能对其建模感兴趣的不同类型的图,这些图与真实数据相对应,包括物理系统、化学分子、图像和文本等。
GN框架的主要计算单元是GN块,一个“graph-to-graph”的模块,以图作为输入,在图结构上进行计算,返回结果也是一个图。如Box3所描述的那样,实体为图中的节点,关系为图中的边,全局属性表示系统级属性。GN框架的模块组织强调可定制性和综合新的体系结构来表达所需的关系归纳偏差。关键的设计原则是:灵活的表示(见4.1) ,可配置的内部模块结构(见4.2)和可组合的多模块结构(见4.3)。
为了使GN形式体系更加具体,我们引入了一个实例。考虑预测一组橡胶球在任意引力场中的运动,它们不是相互碰撞,而是有一个或多个弹簧将它们与其他一些(或全部)弹簧连接起来。我们将在下面的定义中引用这个正在运行的示例,以激活图表示和在其上运行的计算。图2描述了一些其他常见的场景,这些场景可以用图表示,并通过使用图网络进行推理。
3.2.1 图的定义
在GN框架下,一个图被定义为一个三元组 G = ( u , V , E ) G=(u, V, E) G=(u,V,E)(图表示的具体细节参考Box3)。 u u u是全局属性,例如 u u u可能代表引力场。 V = { v i } i = 1 : N v V=\{v_i\}_{i=1:N^v} V={vi}i=1:Nv是节点集合(规模为 N v N^v Nv),每一个 v i v_i vi代表一个节点的属性。例如,V可能表示每个球的位置、速度和质量等属性。 E = { ( e k , r k , s k ) } k = 1 : N e E=\{ (e_k, r_k, s_k) \}_{k=1:N^e} E={(ek,rk,sk)}k=1:Ne是边的集合(规模为 N e N^e Ne),其中每一个 e k e_k ek代表一条边的属性, r k r_k rk是接收节点, s k s_k sk是发送节点。例如, E E E可以表示不同球之间存在的弹簧,以及相应的弹簧劲度系数。

3.2.2 GN块的内部结构
一个GN模块包含三个更新函数 ∅ \varnothing ∅,三个聚合函数 ρ \rho ρ。
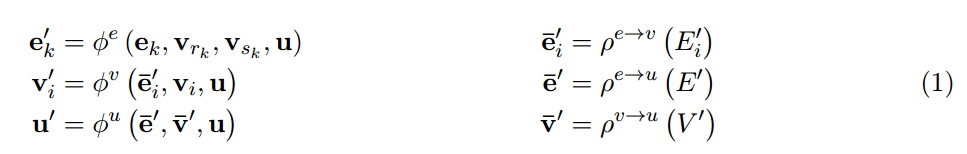
其中 E i ′ = { ( e k ′ , r k , s k ) } r k = 1 , k = 1 : N e , V ′ = { v i ′ } i = 1 : N v , a n d E ′ = ⋃ i E i ′ = { ( e k ′ , r k , s k ) } k = 1 : N e E^{'}_{i} = \{(e^{'}_{k}, r_k, s_k)\}_{r_k=1, k=1:N^e}, V^{'}=\{v_{i}^{'}\}_{i=1:N^v}, and E^{'}=\bigcup_{i}E^{'}_{i}=\{(e^{'}_{k}, r_k, s_k)\}_{k=1:N^e} Ei′={(ek′,rk,sk)}rk=1,k=1:Ne,V′={vi′}i=1:Nv,andE′=⋃iEi′={(ek′,rk,sk)}k=1:Ne。
∅ e \varnothing^{e} ∅e对所有边进行映射,计算更新每条边。 ∅ v \varnothing^{v} ∅v对所有节点进行映射,计算更新每个节点。 ∅ u \varnothing^{u} ∅u仅更新一次,作为全局更新。 ρ \rho ρ 函数每次输入一个集合,并将其规约为表示聚合信息的单个元素。更重要的是, ρ \rho ρ函数不能改变输入的排列顺序,并且应该能够接受可变数量的参数(如元素求和、平均值、最大值等)。
3.2.3 GN块内的计算步骤
当图形G作为输入提供给GN块时,计算从边开始,到节点,再到全局级别。图3展示了计算过程中涉及的图元素的描述,图4a展示了一个完整的具有更新和聚合功能的GN块。算法1给出了计算步骤如下:
- ∅ e \varnothing^{e} ∅e作用于每一条边,参数为 ( e k , v r k , v s k , u ) (e_k, v_{r_k}, v_{s_k},u) (ek,vrk,vsk,u),返回 e k ′ e_{k}^{'} ek′。在我们的例子中,这可能对应于两个相互连接的球之间的力或势能。每个节点i的每条边输出的结果集是 E i ′ = { ( e k ′ , r k , s k ) } r k = 1 , k = 1 : N e E^{'}_{i} = \{(e^{'}_{k}, r_k, s_k)\}_{r_k=1, k=1:N^e} Ei′={(ek′,rk,sk)}rk=1,k=1:Ne。 E ′ = ⋃ i E i ′ = { ( e k ′ , r k , s k ) } k = 1 : N e E^{'}=\bigcup_{i}E^{'}_{i}=\{(e^{'}_{k}, r_k, s_k)\}_{k=1:N^e} E′=⋃iEi′={(ek′,rk,sk)}k=1:Ne是每条边输出的结果集。
- ρ e → v \rho^{e \to v} ρe→v作用于 E i ′ E_{i}^{'} Ei′,将投影到顶点i的边的所有边更新聚集到 e ⃗ i ′ \vec{e}_{i}^{'} ei′,用于下一步的节点更新。在我们的例子中,这可能相当于把作用在第i个球上的所有力或势能加起来。

图3:GN块的更新。蓝色表示正在更新的元素,黑色表示更新中涉及的其他元素(注意更新中还使用了蓝色元素的预更新值),有关符号的详细信息请参见方程1。
- ∅ v \varnothing^{v} ∅v应用于每个节点i,计算更新后的节点属性 v i ′ v_{i}^{'} vi′。在我们的例子中, ∅ v \varnothing^{v} ∅v可能计算一些类似于更新位置,速度和每个球的动能等。每个节点输出的结果集为 V ′ = { v i ′ } i = 1 : N v V^{'}=\{v_{i}^{'}\}_{i=1:N^v} V′={vi′}i=1:Nv。
- ρ e → u \rho^{e \to u} ρe→u作用于 E ′ E^{'} E′,将所有边的更新聚合到 e ⃗ i ′ \vec{e}_{i}^{'} ei′,将用于下一步的全局更新。在我们的例子中, ρ e → u \rho^{e \to u} ρe→u可能计算总的力(根据牛顿第三定律,在这种情况下,其应该是零)和弹簧的势能。
- ρ v → u \rho^{v \to u} ρv→u作用于 V ′ V^{'} V′,聚合所有节点的更新 v ⃗ ′ \vec{v}^{'} v′,将用于下一步的全局更新。在我们的例子中, ρ v → u \rho^{v \to u} ρv→u可能计算系统的总动能。
- ∅ u \varnothing^{u} ∅u作用于每个图,计算全局属性的一次更新 u ′ u^{'} u′。在我们的例子中, ∅ u \varnothing^{u} ∅u可能计算一些类似于合力和物理系统的总能量。
注意,虽然我们在这里假设了这一系列步骤,但并不严格规定执行顺序:可以改变更新函数顺序,比如从全局更新、到每个节点的更新、再到每个边的更新,比如Kearnes et al. (2016) 就是以类似的方式从节点计算边的更新。
3.2.4 图网络中的关系归纳偏差
作为学习过程的组成部分,我们的GN框架引入了几个强的关系归纳偏差。
第一,图可以表示实体之间的任意关系,这意味着GN的输入决定了表示结果如何交互和隔离,而不是由固定的体系结构决定这些选择。例如,假设两个实体之间有一个关系,因此应该有交互,用实体对应节点之间的一条边来表示。同样,两节点之间没有边表示节点之间没有关系,不应该相互直接影响。
第二,图将实体及其关系表示为集合,集合的排列结果是不变的(注意,可以通过在节点或边的属性中编码索引,或者通过边缘本身对索引进行排序)。这意味着GNs对这些元素的顺序是不变的,这通常是合理的。例如,视频场景中的对象没有自然的顺序(见2.2)。
第三,GN的每条边和每个节点的函数可以分别对所有边和节点重用。这意味着,GNs自动支持一种组合泛化形式(见5.1)。因为图由边、节点和全局特征组成,一个单独的GN可以在图的不同尺寸(节点和边的数量)和形状上(边的连通度)进行操作。
4. 图网络体系结构设计原则
按照以上3.2章节所列的设计原则,GN框架可以用来实现多种架构,这与下面要讲的4.1、4.2和4.3也有关系。一般来说,框架对特定的属性表示和函数形式是不可知的。然而,这里我们主要关注的是深度学习架构,它允许GNs充当可学习的graph-to-graph的函数逼近器。
4.1 灵活的表示
图网络以两种方式支持高度灵活的图表示:首先,属性的表示;其次,图本身的表示。
4.1.1 属性
GN块的全局属性、节点属性和边缘属性可以使用任意的表示格式。在深度学习实现中,实值向量和张量是最常见的。但是,也可以使用其他数据结构,如序列、集合,甚至图。
问题的需求常常决定应该为属性使用什么表示。例如,当输入数据为图像时,属性可以表示为图像的张量;然而,当输入数据是文本文档时,属性可能是与句子对应的单词序列。
对于更广泛的体系结构中的每个GN块,边和节点输出通常对应于向量或张量列表,每个边或节点对应一个向量或张量,全局输出对应于单个向量或张量。这使得GN的输出可以传递给其他深度学习构建模块,如MLPs、CNNs和RNNs。
GN块的输出也可以根据任务的需求进行定制。特别地:
- 聚焦于边的GN使用边作为输出,例如,对实体之间的交互进行决策(Kipf et al., 2018; Hamrick et al., 2018)。
- 聚焦于节点的GN使用节点作为输出,例如物理系统的推理(Battaglia et al., 2016; Chang et al., 2017; Wang et al., 2018b; Sanchez-Gonzalez et al., 2018) 。
- 聚焦于图的GN使用全局变量作为输出,例如,预测一个物理系统的势能(Battaglia et al., 2016) ,分子的性质(Gilmer et al., 2017) ,或者回答关于视觉场景的问题(Santoro et al., 2017) 。
取决于具体任务,节点、边和全局变量输出可以进行混合。例如,Hamrick等人(2018)同时使用输出边和全局属性来计算一些操作对应的策略。
4.1.2 图结构
定义输入数据如何表示为图时,通常有两种情况:首先,输入显式地指定了关系结构;其次,对关系结构做出了推断或假设。这两点不难区分,属于两个极端。
有些已经显式地指定了实体和关系,比如知识图谱、社交网络、解析树、最优化问题、化学图、公路网络和已知相互作用的物理系统。图2a-d举例说明了一些数据如何表示为图结构。
有些数据表示中,关系结构并不明确,必须经过推断或假设。比如视觉场景,文本语料库,编程语言源码分析、多智能体系统。在这些领域背景中,数据可以被格式化为一组没有关系的实体,或者仅仅是一个向量或张量(比如一张图像)。如果没有显式地指定实体,可以通过假设,例如,将句子中的每个单词看作一个实体(Vaswani et al., 2017)或CNN的out feature map中的每个局部特征向量作为一个节点(Watters et al., 2017; Santoro et al., 2017; Wang et al., 2018c)(图2e-f) 。如果关系不可用,最简单的方法是实例化实体之间所有可能的有向边(图2f)。但是,如果实体非常多,最好别使用此方法,因为边的数量可能会随着节点的数量以指数级的方式增长。因此,开发更复杂的方法从非结构化数据推断稀疏结构(Kipf et al., 2018)是未来重要的一个方向。
4.2 可配置的within-block结构
GN块中的结构和功能可以用不同的方式配置的,这提供了很强的灵活性,可以;灵活配置将哪些信息作为其函数的输入,以及如何产生输出边、节点和全局更新等。特别地,每一个公式1中的 ∅ \varnothing ∅ 函数必须使用一些函数 f f f进行实现, f f f的参数签名决定了它需要什么信息来作为输入。在图4中,到每个 ∅ \varnothing ∅的输入箭头描述了 u , V , 和 E u,V,和E u,V,和E是否作为输入。
Hamrick et al. (2018) 和 Sanchez-Gonzalez et al. (2018) 使用了图4a所示的全GN块。它们的 ∅ \varnothing ∅使用神经网络实现(定义 N N e , N N v , 和 N N u NN_e, NN_v, 和NN_u NNe,NNv,和NNu不同的下标,意味着使用不同的参数)。它们的 ρ \rho ρ实现使用的是元素求和,但是一般也可以使用求平均或者最大/最小值。

其中,[x,y,z]表示向量/张量连接。 ∅ \varnothing ∅经常使用MLP。而对于张量,如图像特征映射,CNNs更合适。
∅ \varnothing ∅也可以使用RNNs,但需要额外的隐藏状态作为输入和输出。图4b展示了一个简单的使用RNNs作为 ∅ \varnothing ∅函数的GN块版本:该公式中没有传递消息,这种类型的块可用于某些动态图状态的递归平滑。当然,RNNs也可以作为 ∅ \varnothing ∅函数用于全GN块(图4a)。
其他各种架构都可以使用GN框架进行搭建,通常通过不同的函数选择和内置块配置来实现。剩下的小节将探讨GN的块内结构不同配置方式,并举例说明使用相应配置进行建模的示例。详见附录。

图34:不同的内部GN块配置。关于符号的细节参考3.2,第4节了解每种变体的详细信息。(a)一个完整的GN根据传入节点、边和全局属性预测节点、边和全局输出属性。(b)一个独立的、使用输入和隐藏图周期性更新block, ∅ \varnothing ∅ 函数是RNNs(Sanchez-Gonzalez et al., 2018) 。©MPNN(Gilmer et al., 2017) ,基于传入的节点、边和全局属性来预测节点、边和全局输出属性。注意,全局预测不包括聚合的边。(d)NLNN(Wang et al., 2018c) ,只预测节点输出属性。(e)一个仅使用边预测来预测全局属性的关系网络(Raposo et al., 2017; Santoro et al., 2017) 。(f) 深度集(Zaheer et al., 2017)不使用边更新,进行预测更新全局属性。
4.2.1 消息传递神经网络(Message-passing neural network, MPNN)
Gilmer et al. (2017) 的消息传递神经网络概括了许多以前的体系结构,并且可以自然地转换为GN形式。遵循MPNN论文的术语(见Gilmer et al.(2017) ,2-4页):
- 消息函数, M t M_t Mt,起到GN中 ∅ e \varnothing ^e ∅e的作用,但是不输入 u u u
- 向量求和将用于GN的 ρ e → u \rho ^{e\to u} ρe→u
- 更新函数 U t U_t Ut,起到GN中 ∅ v \varnothing ^{v} ∅v的作用
- 读出函数 R R R,起到GN中 ∅ u \varnothing ^{u} ∅u的作用,但是不将 u 或 E ′ u或E^{'} u或E′作为输入, 因此模拟GN的 ρ e → u \rho^{e \to u} ρe→u不是必须的
- d m a s t e r d_{master} dmaster起到的作用和GN中的 u u u大致相同,但是其被定义为一个连接到其他所有节点的额外节点,因此不会直接影响边更新和全局更新。它也可以用GN的 V V V来表示。
图4c展示了MPNN使用GN框架的架构模式,具体细节和不同的的MPNN架构,参考附录。

图5:MLNNs作为GNs。一张展示MLNN(Wang et al., 2018c) 如何在GN框架下使用 ∅ e 和 ρ e → v \varnothing^{e}和\rho^{e \to v} ∅e和ρe→v来实现的原理图。通常,NLNNs假定图像(或句子中的单词)的不同区域对应于完全连接图中的节点。注意机制定义了聚合步骤中节点的加权和。
4.2.2 非局部神经网络(Non-local neural networks, MLNN)
Wang et al. (2018c) 的非局部神经网络,其统一了各种内部注意力/自注意力/顶点注意力/图注意方法(Lin et al., 2017; Vaswani et al., 2017; Hoshen, 2017; Veliˇckovi´c et al., 2018; Shaw et al., 2018) ,也可以使用GN来描述。注意力表示节点如何更新:每个节点的更新都基于其邻居节点属性的加权和(或某些其他函数),其中,节点与其相邻节点之间的权重是由某种函数使用它们的属性计算出来的(然后和邻居进行标准化)。已经公开发布的MLNN标准形式不包括显式边,而是计算所有节点之间成对的注意力权重。但是对于不同的MLNN模型,例如顶点注意力交互网络(vertex attention interaction network, (Hoshen, 2017) )和图注意力网络(graph attention network,(Veliˇckovi´c et al., 2018) )能够通过将不共享边的节点之间的权重设置为零来有效地处理显式边。
如图4d和5所示, ∅ e \varnothing^{e} ∅e被分解为标量形式的成对交互函数,其返回未归一化的注意力值,定义为 α e ( v r k , v s k ) = a k ′ \alpha^{e}(v_{r_k, v_{s_k}})=a^{'}_{k} αe(vrk,vsk)=ak′,和一个非成对形式的向量,定义为 β e ( v s k ) = b k ′ \beta^{e}(v_{s_k})=b^{'}_{k} βe(vsk)=bk′。在 ρ e → v \rho^{e \to v} ρe→v聚合操作中, a k ′ a_k^{'} ak′和每一个接收者的边 b k ′ b_k^{'} bk′进行点乘求和。
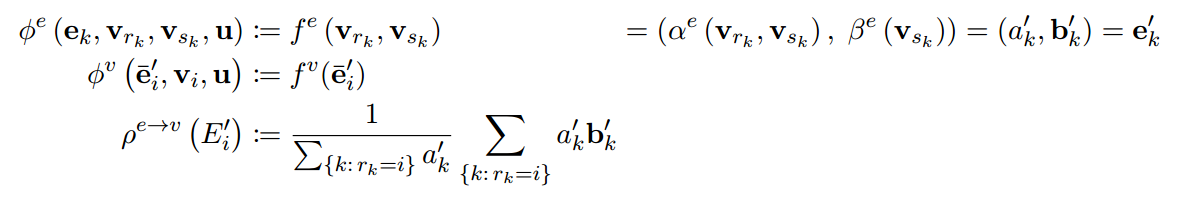
在MLNN论文的术语表中(参考Wang et al. (2018c) 2-4页)
- 它们的 f f f代表上面的 α \alpha α
- 它们的g代表上面的 β \beta β
这个公式可能有助于只关注那些与下游任务最相关的交互,特别是当输入实体是一个集合时,可以通过在它们之间添加所有可能的边,从而形成一个图。
Vaswani et al. (2017) 的多头自注意力机制增加了有趣的特征,其中 ∅ e 和 ρ e → v \varnothing^{e}和\rho^{e \to v} ∅e和ρe→v通过一组并行的函数集合来实现,这些函数集合的结果通过最后步骤的 ρ e → v \rho^{e \to v} ρe→v连接在一起。这可以解释为使用有类型的边,不同类型的索引对应不同的 ∅ e \varnothing^{e} ∅e组件函数,与Li et al. (2016) 类似。
对于不同的MLNN架构实现的细节,见附录。
4.2.3 其他图网络变体
全GN(Equation 2) 可以用于预测如4.1.1描述的完全图或任何 ( u ′ , V ′ , E ′ ) (u^{'}, V^{'}, E^{'}) (u′,V′,E′)的子图。例如,预测图的全局性质, V ′ 和 E ′ V^{'}和E^{'} V′和E′可以暂时忽略。类似地,如果输入中未指定全局属性、节点属性或边属性,则这些向量可以是零长度,而不是作为显式输入参数。同样的概念适用于其他GN变种,即不使用完整的映射函数( ∅ \varnothing ∅)和规约函数($ \rho $)。例如,交互网络(Battaglia et al., 2016; Watters et al., 2017) 和神经物理引擎((Chang et al., 2017) )使用了全GN但是没有全局的边属性更新(详细细节见附录)。
包括CommNet(Sukhbaatar et al., 2016) 、structure2vec(Dai et al., 2016) (in the version of (Dai et al., 2017)) 和Gated Graph Sequence Neural Networks(Li et al., 2016) 在内的不同模型都使用了这样的 ∅ e \varnothing^{e} ∅e:不直接计算成对的交互,而是忽略接收方节点,只在发送方节点上操作,在某些情况下还计算边属性。这可以使用如下的$\varnothing $函数实现来表述:
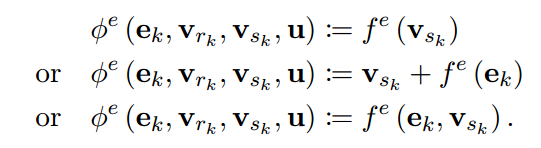
更多详细细节参考附录。
关系网络(Raposo et al., 2017; Santoro et al., 2017) 完全绕过节点更新,直接使用聚合的边信息预测全局输出(图4e)。
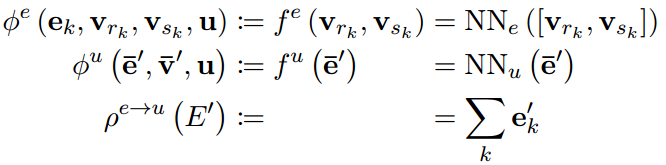
Deep Sets (Zaheer et al., 2017) 完全绕过边更新,直接使用聚合的节点信息预测全局输出(图4f)。
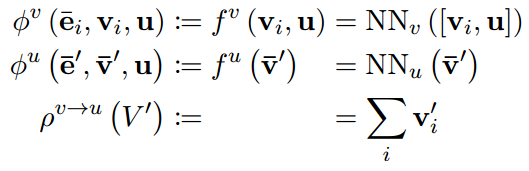
PointNet(Qi et al., 2017) 使用相似的更新规则,对于 ρ v → u \rho ^ {v \to u} ρv→u使用了最大聚合,以及一个两阶段的节点更新。

图6:(a)一个按顺序组合多个GN模块形成GN “core”的例子。此时,GN模块之间可以共享权重,或者也可以是相互独立的。(b)encode-process-decode架构,对GN模块来说是一种比较常见的选择(见4.3)。此时,一个GN将输入图进行编码,然后使用一个GN core进行处理。核心的输出由第三个GN块解码成输出图,其节点、边和全局属性将根据具体任务做具体处理。©encode-process-decode架构使用的是序列模型,除了在每个时间步中重复,其核心是按时间展开的(可能使用GRU或LSTM架构)。这里,合并行表示连接,拆分行表示复制。
4.3 可组合的多模块架构
图网络的一个关键设计原则是通过构造GN块来构造复杂的模型结构。我们定义一个GN块,它总是以一个由边、节点和全局元素组成的图作为输入,并且返回一个由相同组成元素的图作为输出(当这些元素没有显式更新时,只需将输入元素传递到输出即可)。即使它们的内部结构不同,类似于标准深度学习工具包的张量到张量接口,这种graph-to-graph的输入/输出接口确保了GN模块的输出可以作为输入传递到其他GN模块。在大多数基本形式中,两个GN块,GN1和GN2可以通过传递第一个的输出作为第二个的输入组成GN1 ◦ GN2: G ′ ′ = G N 2 ( G N 1 ( G ) ) G^{''} = GN_2(GN_1(G)) G′′=GN2(GN1(G))。
任意数量的GN块也可以相互组合,如图6a所示。块之间可以使不共享的(类比CNN的网络层,不同的函数或参数), G N 1 ≠ G N 2 ≠ … ≠ G N M GN_1 \neq GN_2 \neq \dots \neq GN_M GN1̸=GN2̸=…̸=GNM。也可以是共享的(类比一个铺开的RNN的网络层,可重用的函数和参数), G N 1 = G N 2 = ⋯ = G N M GN_1 = GN_2 = \dots = GN_M GN1=GN2=⋯=GNM。图6a中, G N c o r e GN_{core} GNcore周围的白色边框代表M个重复的内部处理子步骤,其为要么共享要么不共享的GN块。共享的配置类似于消息传递(Gilmer et al., 2017) ,迭代的进行相同的本地更新过程,进行跨结构信息传播(图7)。如果排除全局 u u u(其跨节点和边进行信息聚合),在传播m步之后,节点可以访问的信息由最多m跳距离的节点集集和边集合决定。这可以解释为把复杂的计算分解成更小的基本步骤。这些步骤还可以用来实时捕获序列性信息。在我们的球弹簧例子中,如果每个传播步长预测持续时间为∆t的一个时间步长的物理动能,则M个传播步长导致的总仿真时间为,M·∆t。
一种常见的体系结构设计就是我们所说的encode-process-decode配置(Hamrick et al. (2018); 或者图6ba) :输入一个图 G i n p G_{inp} Ginp被encoder G e n c G_{enc} Genc转换为一个潜在的表示, G 0 G_0 G0;共享的核心模块 G N c o r e GN_{core} GNcore被使用M次返回 G M G_M GM;最后通过decoded模块 G N d e c GN_{dec} GNdec得到一个输出图 G o u t G_{out} Gout。例如,在我们的运行示例中,encoder计算球之间的初始力和相互作用能量, core使用一个基本动态更新,decoder可能从已更新的图状态中读出最后的位置 。

图7:消息传递的例子。每一行都突出显示从特定节点开始在图中扩散的信息的节点。在第一行中,开始节点位于右上角;在下一行中,开始节点位于右下角。阴影节点表示在消息传递的m个步,信息距离原始节点的距离;粗体边表示信息有可能经过哪些边。注意,在完整的消息传递过程中,对图中的所有节点和边同时进行信息传播(不仅仅是图中这两个展示的)。
类似于encode-process-decode这种模式, 通过维护一个隐藏图 G h i d t G_{hid}^{t} Ghidt,基于GN的循环架构模式也可以构建出来。其每一步输入为此步骤下能观察到的图 G i n p t G_{inp}^{t} Ginpt,返回一个输出图 G o u t t G_{out}^{t} Goutt(见图6c)。这种架构对于预测图序列特别有用,例如预测动态系统随时间变化的轨迹(e.g. Sanchez-Gonzalez et al., 2018)。被 G N e n c GN_{enc} GNenc编码过的图必须和 G h i d t G_{hid}^{t} Ghidt有相同的结构,通过连接它们对应的 e k , v i , 和 u e_k, v_i, 和 u ek,vi,和u向量,在传递给 G N c o r e GN_{core} GNcore之前可以很容易地组合它们(图6c中,向上的箭头合并到左边水平向右的箭头)。对于输出, G h i d t G_{hid}^{t} Ghidt被拷贝(图6c中,右边水平指向右的箭头被复制分割到向下一条箭头),并且被 G N d e c GN_{dec} GNdec编码。这种设计在几个方面重复利用GN块: G N e n c , G N d e c , 和 G N c o r e GN_{enc},GN_{dec},和GN_{core} GNenc,GNdec,和GNcore在每一步t都都是共享的。在每一步中, G N c o r e GN_{core} GNcore可能执行多次共享子步骤。
基于GN设计架构的其他不同技术都是有用的。例如,图跳过了连接,将GN块的输入图 G m G_{m} Gm与其输出图 G m + 1 G_{m+1} Gm+1连接起来,然后进行下一步的计算。如图6c所示,对输入和隐藏的图信息进行合并和平滑操作,对LSTM-或者GRU-式的门控结构时有用的,而不是使用简单的连接(Li et al., 2016)。循环GN模块(如图4b)可以在组合在其他GN块之前或之后,来提高多个传播步骤上数据表示结果的稳定性。
4.4 图网络的代码实现
类似于CNNs(见图1),其天生可以并行(比如在GPU上),GNs也有天生的并行结构:因为公式1中的 ∅ e 和 ∅ v \varnothing^{e}和\varnothing^{v} ∅e和∅v函数分别在边上和节点上进行共享,它们可以并行计算。实际上,这意味着对于 ∅ e 和 ∅ v \varnothing^{e} 和\varnothing^{v} ∅e和∅v,在一般的小型批处理训练中,节点和边可以以批处理维度进行处理。此外,一些图可以将它们视为较大图的不同组件而自然地组合在一起。加上一些额外的处理,这允许将几个独立图上的计算结果并行处理。
Box4:图网络开源软件库:github.com/deepmind/graph nets
我们发布了一款基于TensorFlow/Sonnet的用于构建GNs的开源库。它包括演示如何创建、操作和训练GNs来对图结构数据进行推理任务、最短路径查找任务、排序任务和物理预测任务。每个例子都使用相同的GN架构,这突出了方法的灵活性。
最短路径演示例子:tinyurl.com/gn-shortest-path-demo
这个例子创建了一个随机的图,然后训练一个GN来给任意两个节点之间最短路径上的节点和边打标签。通过一系列消息传递步骤(如每个步骤的图所示),模型改进了对最短路径的预测结果。

排序的例子:tinyurl.com/gn-sort-demo
这个例子创建了随机数列表,并训练GN对列表进行排序。在经过一系列消息传递步骤之后,模型可以准确地预测下一个元素。

物理例子:tinyurl.com/gn-physics-demo
这个例子创建了一个随机质量弹簧物理系统,然后训练一个GN来预测下一个时间步长系统的状态。该模型的下一步预测可以作为输入反馈回来,反应未来轨迹的变化。下面的每个子图显示了50个时间步长内真实的和预测的质量-弹簧系统状态。这和论文(Battaglia et al., 2016) 的“interaction networks ”的模型和实验相似。

重复利用 ∅ e 和 ∅ v \varnothing^{e}和\varnothing^{v} ∅e和∅v也可以提高GNs的采样效率。类似于卷积核,用于优化GN的 ∅ e 和 ∅ v \varnothing^{e}和\varnothing^{v} ∅e和∅v函数的样本数量是边和节点的数量,分别在所有的训练图中。例如,在第3.2节的balls例子中,一个由弹簧连接的四个球的系统,包含12种(4×3)球之间接触交互的场景。
我们发布了一个用于构建GNs的开源软件库,地址为:github.com/deepmind/graph nets 。相关概述可以参考Box 4。
4.5 总结
在本节中,我们讨论了图网络背后的设计原则:灵活的表示、可配置的块内结构和可组合的多块体系结构。这三个设计原则结合在我们的框架中,带来了灵活性,适用于从感知、语言到符号推理的广泛领域。并且,我们将在本文的其余部分看到,图网络所具有的强大的关系归纳偏差和支持组合泛化的能力,从而使其无论是在实现方面还是在理论方面成为一个强大的工具。
5. 讨论
在本文中,我们分析了诸如MLPs、CNNs、和RNNs等深度学习架构中关系归纳偏差存在的程度。结论是,虽然CNNs和RNNs确实包含关系归纳偏见,但是它们不能自然地处理更结构化的表示,比如集合或图。我们提倡在深度学习体系结构中构建更强的关系归纳偏差,方法是提出一个未被充分利用的深度学习构建块,即图网络,其对图形结构数据执行计算。我们的图网络框架统一了也通过图操作的现有方法,并提供了一个直观的接口,用于将图网络组装成更复杂的体系结构。
5.1 图网络中的组合泛化
GNs的结构天生支持组合泛化,因为它们不仅严格地在系统级别上执行计算,而且还跨实体和跨关系共享计算。这允许对从未见过的系统进行推理,因为它们是基于我们熟悉的部件构建的,某种程度上反映了冯·洪堡“infinite use of finite means(对有限手段的无限运用)”原则(Humboldt,1836;Chomsky,1965)
已经有许多研究探索了GNs的组合泛化能力。Battaglia et al. (2016) 研究发现,接受单步物理状态预测训练的GNs可以模拟未来数千步时间步长的结果,而且在训练过程中实体数量增加一倍或减少一半的情况下,还可以使物理系统进行精确的零样本迁移。Sanchez-Gonzalez et al.(2018) 在更复杂的物理控制设置中发现了类似的结果,作为前向模型在仿真多关节智能体上训练的GNs可以推广到具有新关节数的智能体上。Hamrick et al.(2018)和Wang et al. (2018b)都发现基于GN的决策也可以转移到包含新实体的数据中。在组合优化问题中,Bello et al. (2016); Nowak et al. (2017); Dai et al. (2017); Kool and Welling (2018) 证明了GNs可以很好地推广到它们没有训练过模型的不同规模的问题。类似的,Toyer et al. (2017) 证明了对不同规模规划问题的泛化,并且Hamilton et al. (2017) 证明了为以前未见的数据生成有用的节点嵌入的泛化能力。对于布尔在SAT问题,Selsam等(2018)证明了对不同问题大小和跨问题分布的泛化能力:该模型对输入图的分布及其典型局部结构进行了较强的改造,保持了良好的性能。
考虑到GNs以实体和关系为中心的组织结构,这些组合泛化的显著例子并不令人惊讶。但尽管如此,它们为以下观点提供了重要支持:采用显式结构和灵活的学习方式是在现代人工智能中实现更好的采样效率和泛化能力的可行方法。
5.2 图网络的局限性
GNs和MPNNs学习到的消息传递的一个限制(Shervashidze et al., 2011)是不能保证它能解决某些类别的问题,例如区分某些非同构图。Kondor et al. (2018) 认为应该协方差(Cohen and Welling, 2016; Kondor and Trivedi, 2018) ,比节点和边的排列组合的不变性更好,并提出了“协变组成网络”,其可以保留结构信息,也可以忽略。
通常来说,虽然图是表示结构信息的一种强大方法,但它们也有局限性。例如,递归、控制流和条件迭代等概念不容易用图表示,而且需要额外的假设(比如在解释抽象语法树时)。与这些概念相比,程序和“类计算机“处理可以提供更强的表示性和计算表达能力,一些人认为它们是人类认知的重要组成部分(Tenenbaum et al., 2011; Lake et al., 2015; Goodman et al., 2015) 。
5.3 开放性问题
尽管我们对图网络的潜力感到兴奋,但必须指出的是这些模型只是向前迈出了很小一步。实现图网络的全部潜力可能比在一个统一框架下组织它们的操作更具挑战性,而且关于使用图网络的最佳方式还有许多未解决的问题。
一个紧迫的问题是:这些图从哪里来的呢?深度学习的一个特点是能够对原始的感官数据进行复杂的计算,比如图像和文本。然而,目前还不清楚将感官数据转换成更结构化的表示形式(如图)的最佳方式。一种方法是(我们已经讨论过)假设空间或语言实体之间存在完全连接的图结构,例如在有关自我注意的文献中就使用过此假设(Vaswani et al., 2017; Wang et al., 2018c) 。然而,这样的表示可能并不完全对应于“true“实体(例如,卷积特征并不直接对应于场景中的对象)。此外,许多底层图结构比完全连通图稀疏得多,如何导致的这种稀疏性是一个悬而未决的问题。一些研究正在探索这些问题(Watters et al., 2017; van Steenkiste et al., 2018; Li et al., 2018; Kipf et al., 2018) 但目前还没有一种方法能够可靠地从感官数据中提取出离散的实体。开发这样一种方法对未来研究工作来说是一项令人兴奋的挑战,一旦解决了这个问题,就有可能发明更强大、更灵活的推理算法。
另一个相关的问题是如何在计算过程中自适应地修改图结构。例如,如果一个对象分裂为多个块,表示该对象的节点也应该分裂为多个节点。类似地,只表示处于联系中的对象之间的边可能很有用,因此需要根据上下文添加或删除边。如何支持这种自适应性正在被研究,用于确定图的基本结构的一些方法可能是适用的(e.g. Li et al., 2018; Kipf et al., 2018) 。
人类的认知基于一个很强的假设,即世界是由物体和关系构成的(Spelke and Kinzler, 2007) 。因为GNs做了类似的假设,所以它们的行为更易于解释。GNs操作的实体和关系通常与人类理解的事物相对应(例如物理对象),从而支持更多可解释的分析和可视化(Selsam et al., 2018)。未来工作的一个有趣方向是进一步探索图网络行为的可解释性。
5.4 学习和结构的综合方法
虽然我们在这里关注的是图,但本文的一个结论不是关于图本身,而是关于如何将强大的深度学习方法与结构化表示相结合。我们对相关的方法感到兴奋,这些方法探索了其他类型的结构化表示和计算,如语言树(Socher et al.,2011a,b, 2012, 2013; Tai et al., 2015; Andreas et al., 2016) ,状态动作图中的部分树遍历(Guez et al., 2018; Farquhar et al., 2018) ,层次的行动策略(Andreas et al., 2017) ,多代理交流通道(Foerster et al., 2016) ,胶囊网络(Sabour et al., 2017) 和程序(Parisotto et al., 2017) 。其他方法试图通过模仿计算机中的关键硬件和软件以及它们之间如何传输信息来捕捉不同类型的结构,例如持久存储器、寄存器、内存I/O控制器、堆栈和队列(e.g. Dyer et al., 2015; Grefenstette et al., 2015; Joulin and Mikolov, 2015; Sukhbaatar et al., 2015; Kurach et al., 2016; Graves et al., 2016)。
5.5 结论
在深度学习的推动下,人工智能的最新进展在许多重要领域都具有革命性。尽管如此,人类和机器智能之间仍然存在巨大的鸿沟,尤其是在高效、可泛化的学习方面。我们主张将组合泛化能力作为人工智能的首要任务,并提倡采用综合方法,充分利用人类认知、传统计算机科学、标准工程实践和现代深度学习的思想。在这里,我们探索了科学系的灵活的方法,它实现了强大的关系归纳偏差,利用显式的结构化表示和计算。并提出了一个称为图网络的框架,它概括和扩展了应用于图的各种神经网络的最新方法。图网络旨在使用可自定义的graph-to-graph构建块来构建复杂的体系结构,相对于其他标准的机器学习构建模块,它们的关系归纳偏差促进了组合泛化和提高了样本效率。
然而,尽管有这些好处和潜力,可学习的图模型只是通往类人智能道路上的一块踏脚石。我们对其他一些相关的,也许被低估的研究方向持乐观态度,包括将基于学习的方法与程序结合(Ritchie et al., 2016; Andreas et al., 2016; Gaunt et al., 2016; Evans and Grefenstette, 2018; Evans et al., 2018) ,开发强调抽象的基于模型的方法(Kansky et al., 2017; Konidaris et al., 2018; Zhang et al., 2018; Hay et al., 2018) ,加大对元数据学习的投入(Wang et al., 2016, 2018a; Finn et al., 2017) 和探索多智能体学习和交互作为高级智能的关键催化剂(Nowak, 2006; Ohtsuki et al., 2006) 。这些方向都包含了实体、关系和组合泛化的丰富概念,用于可学习的关系推理方法包含更多的交互,这比显式的结构化表示起到更大的作用。
这篇关于论文笔记11:Relational inductive biases, deep learning, and graph networks翻译笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







