本文主要是介绍Re9:读论文 DEAL Inductive Link Prediction for Nodes Having Only Attribute Information,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
诸神缄默不语-个人CSDN博文目录
论文名称:Inductive Link Prediction for Nodes Having Only Attribute Information
论文ArXiv下载地址:https://arxiv.org/abs/2007.08053
论文IJCAI官方下载地址:https://www.ijcai.org/proceedings/2020/168(在该网站中有给出讲解视频链接,这TMD是我这么多天以来听到的第一个中国人讲的英文论文视频了!感动中国,终于有一个我听得懂的英语口音了!毛子口音和三哥口音我是真的受够了!)(本文中非论文配图的插图都截自该视频)
官方GitHub项目:working-yuhao/DEAL: IJCAI2020
本文是2020年IJCAI论文,主要专注于inductive link prediction场景(但是模型也可以应用于transductive场景)。
inductive场景中新节点仅有attribute,没有结构信息。
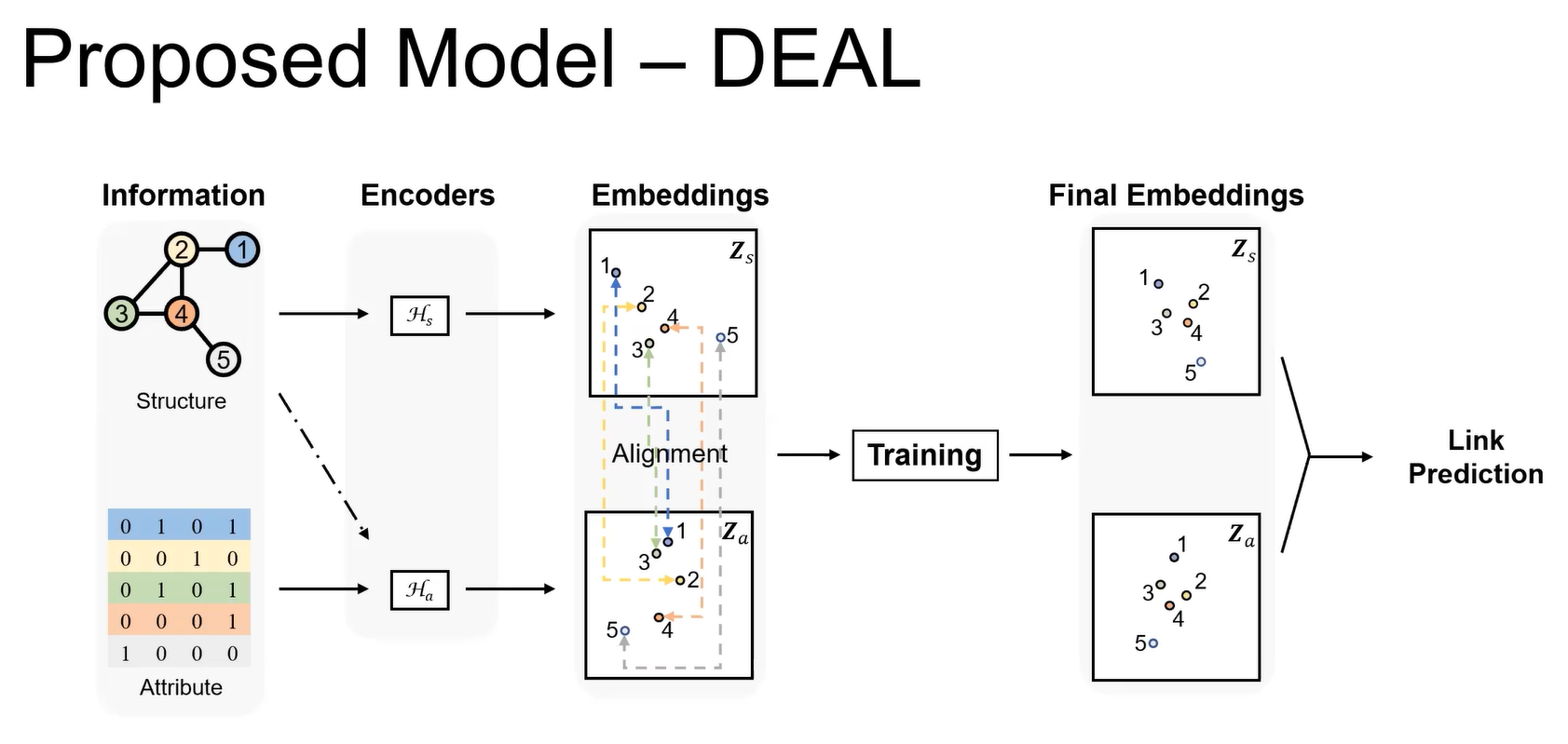
本文提出的模型DEAL (Dual-Encoder graph embedding with ALignment) 可以对新query node仅基于其attributes做表征,与其他节点嵌入做链路预测。
DEAL模型分别对attribute和图结构进行嵌入(2个encoder,一个是纯MLP,一个是直接以独热编码为初始化矩阵+MLP+weight normalization1做节点表征(效果甚至比GCN好,简单方法大力出奇迹)),然后使用一个对齐机制将两个encoder关联起来(在训练过程中一起更新,使表征在向量空间中对齐),具体实现方式是做两个对比学习:是否连边(相连的节点,encoder得到的表征相似度应该高),以及2个encoder得到的表征。
用余弦相似度来衡量距离。
这个损失函数是可以用超参数调整的ranking-motivated loss。
在测试时用两个节点的两种表征两两交叉计算相似度线性求和来计算连边概率:
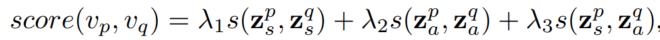
如果是inductive范式,就不计算第一项。
可以跟引用了DEAL模型的LeSICiN2做对比。
LeSICiN可以说是将DEAL模型extend到了有监督异质图场景,对齐机制是两种节点的不同表征做交叉对齐(为什么不是每种节点自己对齐自己的,我也不知道),打分则和DEAL使用的表征对相同(只做了inductive场景),但不用相似度而用MLP解码。损失函数则直接将3种打分得到的分数视作概率,用多任务分类任务范式将3个交叉熵损失函数加权求和。
文章目录
- 1. Background & Motivation
- 2. DEAL模型
- 2.1 Attribute-oriented Encoder
- 2.2 Structure-oriented Encoder
- 2.3 对齐机制和模型训练
- 2.3.1 损失函数
- 2.3.2 对齐机制
- 2.3.3 训练算法和预测过程
- 3. 实验
- 3.1 数据集
- 3.2 baseline
- 3.3 实验设置
- 3.4 主实验结果
- 3.5 模型分析
- 4. 代码复现
1. Background & Motivation
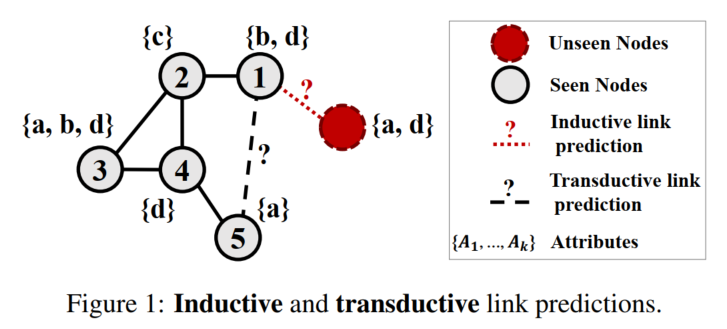
早期链路预测任务关注节点相似性的度量,近年来往往通过图嵌入方法来实现链路预测。有些图嵌入方法只能捕获图结构信息,能捕获attributes信息的大多关注transductive范式(两个节点都在训练时就存在于图中)。
可以做inductive链路预测,但是需要边的模型:SDNE3(只能捕获图结构信息)和GraphSAGE4。
G2G5:可以对没有局部结构的新节点做inductive链路预测,但无法区分特征相似的节点,因为它无法很好地捕获节点表征中体现的结构信息。
2. DEAL模型
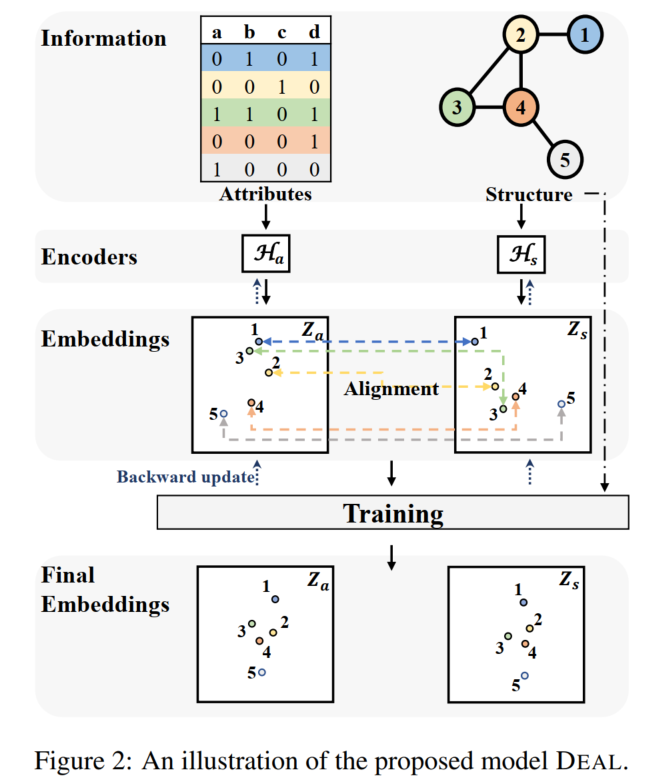
在视频中的画法,换了个方向:
2.1 Attribute-oriented Encoder
输入是节点attributes,输出节点嵌入: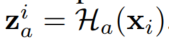
可以选择各种神经网络,本文直接用了MLP(激活函数是ELU):
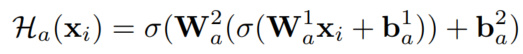
(这里论文对没用GCN的解释是:经实验观察,聚合太多邻居信息会影响attributes表征效果。我的迷惑点在于,这他妈的在inductive场景下不是本来就不能用GCN吗!)
2.2 Structure-oriented Encoder
用节点独热编码作为输入,得到节点嵌入: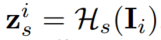
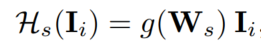
就是说这个本来也可以用GCN(以邻接矩阵为输入),但是实验证明效果不如本文提出的方法。
2.3 对齐机制和模型训练
学习特征和结构之间的关联。
模型训练时2个encoder一起更新参数,在向量空间对齐表征。
2.3.1 损失函数
ranking-motivated loss(证明其效果的参考文献:5和Content-based citation recommendation)
本文提出了一个新的mini-batch learning method with a personalized ranking-motivated loss
contrastive loss6:
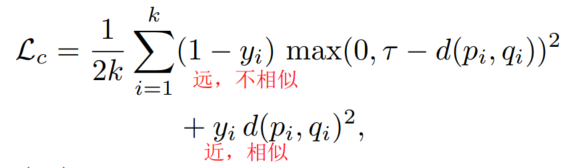
(公式中p-q是成对样本,共有k对)
直接使用contrastive loss的问题是:1. 负样本对距离不同,因此用同一个margin( τ \tau τ)不合适。2. 损失函数中没有考虑regularization。
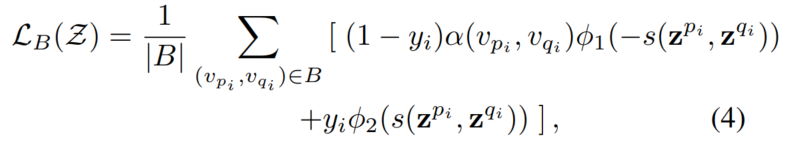
y是节点是否连边, α \alpha α是weight function, ϕ \phi ϕ通过不同的超参形成 ϕ 1 \phi_1 ϕ1和 ϕ 2 \phi_2 ϕ2。 s s s在本文中用的是余弦相似度。
由于logistic loss可看作margin无限的软版hinge loss(参考文献:A tutorial on energy-based learning)(没看懂这个啥意思),因此本文使用了the generalized logisitic loss function:
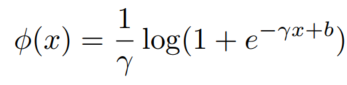
(参考文献:A view of margin losses as regularizers of probability estimates)
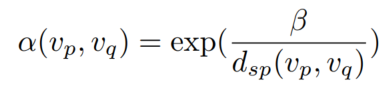
(衡量不同距离样本的重要性。 d s p d_{sp} dsp是shortest path distance)
2.3.2 对齐机制
最小化2个encoder的上述损失函数,然后加上对齐机制。
- Tight Alignment (T-align):最小化节点的2种表征(太严格了)
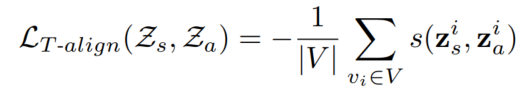
- Loose Alignment (L-align):最大化相连节点的不同表征(就是一个结构、一个attributes)的相似性(用和2.3.1部分介绍的一样的损失函数来做)
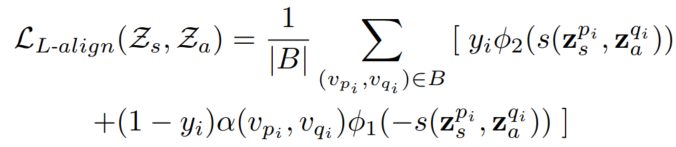
最后就是两个链路预测的损失,加对齐的损失:
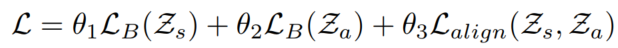
2.3.3 训练算法和预测过程

测试时:
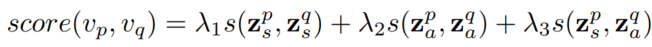
(在inductive场景下, λ 1 \lambda_1 λ1为0)
3. 实验
3.1 数据集
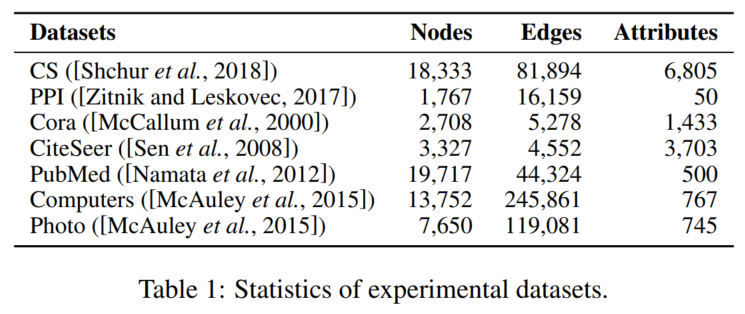
细节略
3.2 baseline
MLP
SEAL
G2G5
GAE
细节略
3.3 实验设置
略。
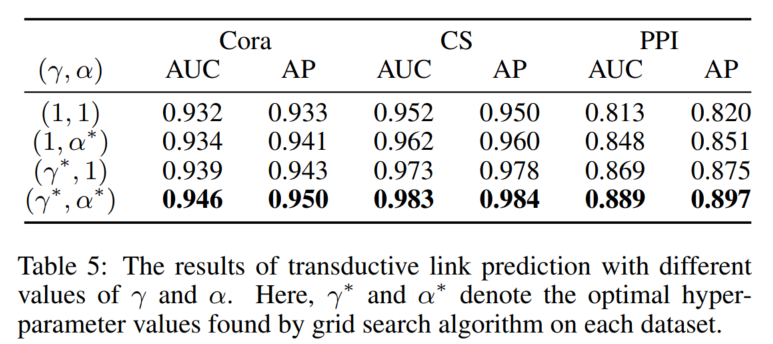
3.4 主实验结果
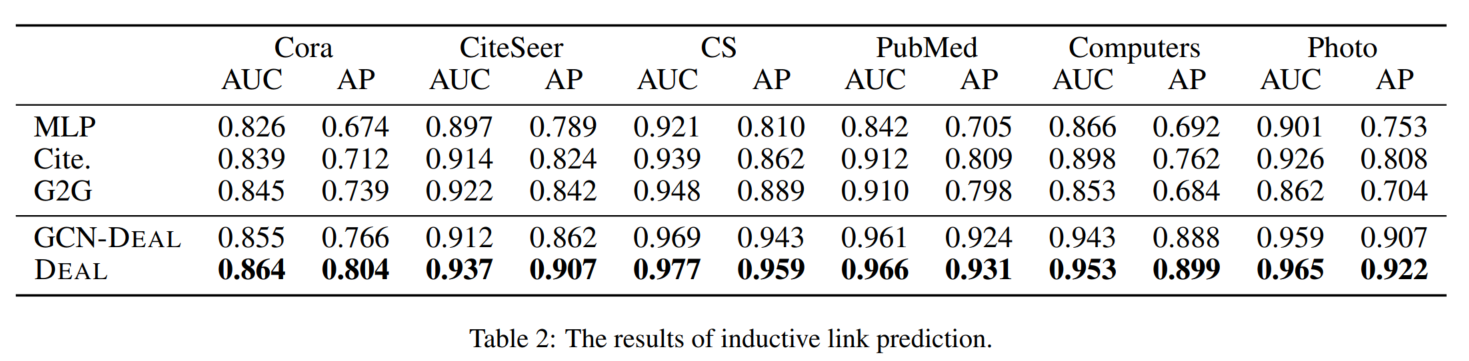
论文里也没说这个Cite.是啥模型。
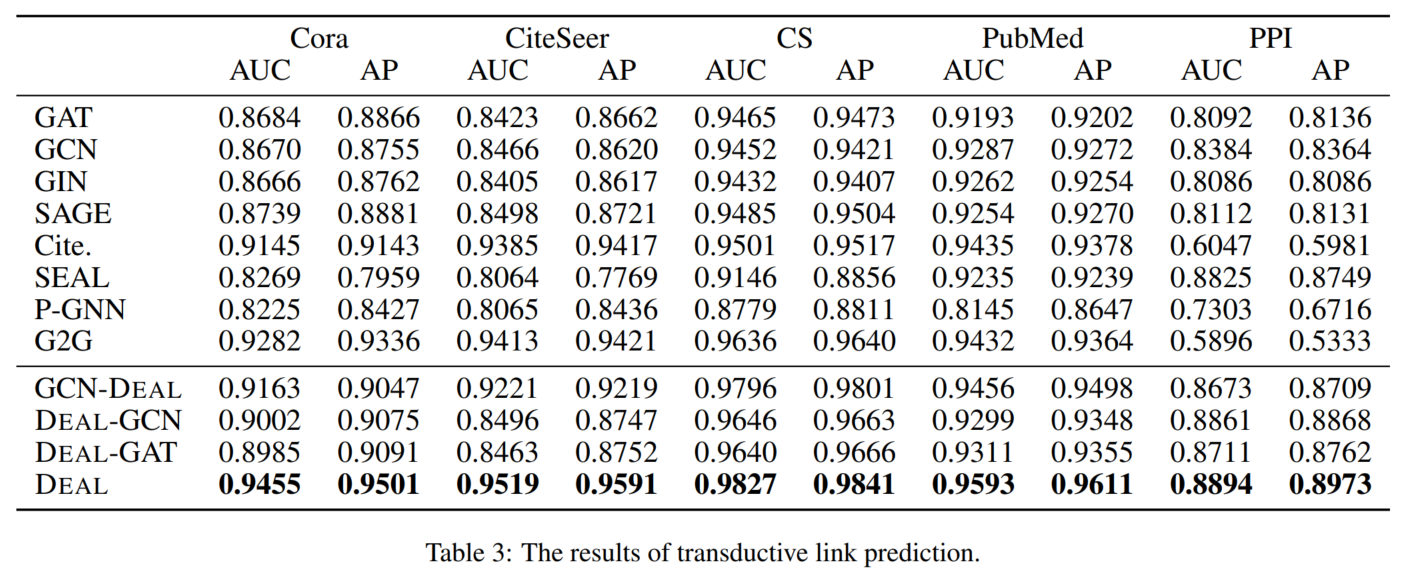
3.5 模型分析
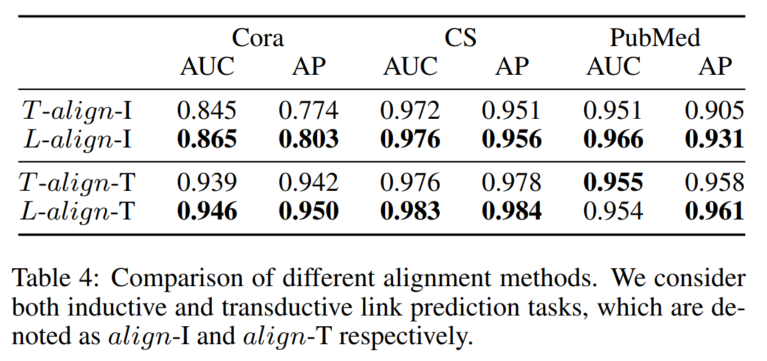
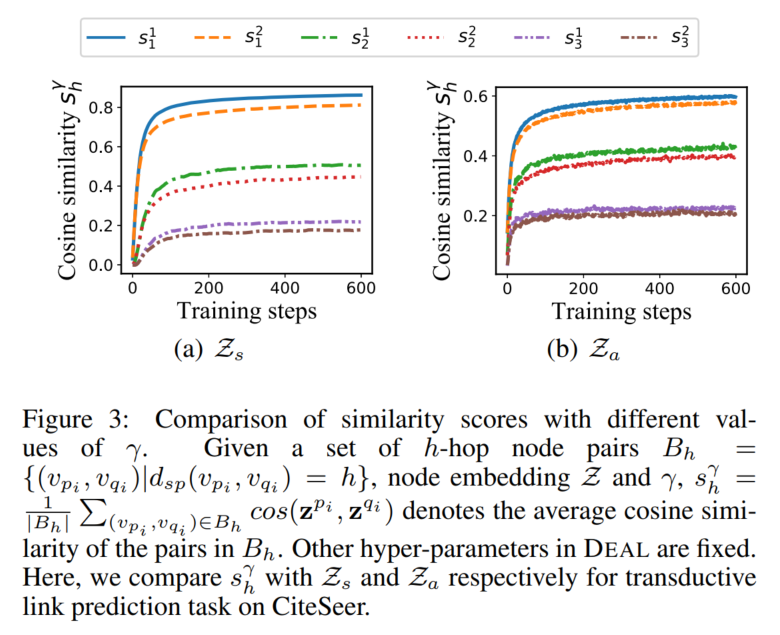
细节略,待补。
4. 代码复现
等我服务器好了再说。
Weight normalization: A simple reparameterization to accelerate training of deep neural networks
我直接百度了相关的一些资料:
① 【深度学习】Weight Normalization: 一种简单的加速深度网络训练的重参数方法_Shwan_Ma的博客-CSDN博客:这篇开头就满篇错别字
② Generative Modeling with Variational Auto Encoder (VAE) | by Fathy Rashad | ViTrox-Publication | Medium:重要内容:AE (Auto Encoder) 和VAE (Variational Autoencoder),VAE是用来规范化AE的(强迫隐向量空间连续、有意义,把每个特征值学成一个高斯分布)。后面数学部分简单带过了,没仔细看,总之大约来说就是这个分布需要通过差分推断来学习,也就是需要学习另一个tractable相似分布,通过KL散度来学习两个分布的相似程度。
对应的中文翻译(我是直接看的英文版):使用(VAE)生成建模,理解可变自动编码器背后的数学原理 - 知乎
③ inference - What does a ‘tractable’ distribution mean? - Cross Validated:不能用闭包表现形式解决的问题
④ GAN — Why it is so hard to train Generative Adversarial Networks! | by Jonathan Hui | Medium
⑤ 重参数 (Reparameterization)_连理o的博客-CSDN博客_重参数
⑥ 模型优化之Weight Normalization - 知乎:怎么说呢,看起来好像就是对参数的一种归一化方法(将其拆成两部分,然后直接优化这两部分) ↩︎Re6:读论文 LeSICiN: A Heterogeneous Graph-based Approach for Automatic Legal Statute Identification fro ↩︎
Structural deep network embedding ↩︎
Inductive representation learning on large graphs ↩︎
Deep gaussian embedding of graphs: Unsupervised inductive learning via ranking ↩︎ ↩︎ ↩︎
Dimensionality reduction by learning an invariant mapping ↩︎
这篇关于Re9:读论文 DEAL Inductive Link Prediction for Nodes Having Only Attribute Information的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









