本文主要是介绍Inductive Representation Learning on Large Graphs 论文/GraphSAGE学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 动机
1.1 过去的方法
现存的方法大多是transductive的,也就是说,在训练图的时候需要将整个图都作为输入,为图上全部节点生成嵌入,每个节点在训练的过程中都是可知的。举个例子,上一次我学习了GCN模型,它的前向传播表达式为:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) H^{(l+1)}=σ(\widetilde D^{- \frac{1}{2}} \widetilde A \widetilde D^{- \frac{1}{2}} H^{(l)} W^{(l)} ) H(l+1)=σ(D −21A D −21H(l)W(l))
可以看出,对GCN的训练需要将整个图的邻接矩阵作为输入,这不利于大图的训练,因为电脑的内存可能无法支持如此巨大的输入。同时,也没有办法对图进行很好的切割,不利于分布式训练。
并且现实中很多应用的数据都会不断地变化更新,采用这种transductive的训练方式对于新增节点的情况需要进行重新训练,这增大了计算开销。
1.2 GraphSAGE
为了解决这个问题,本文的作者们提出了inductive的方法—GraphSAGE。该方法不需要将整图输入来为图中所有节点生成嵌入,而是通过对节点的领域里的邻居进行采样和聚合的方式来为独立的节点生成嵌入。因此,GraphSAGE能更好地应对unseen节点,不需要对模型重新训练。
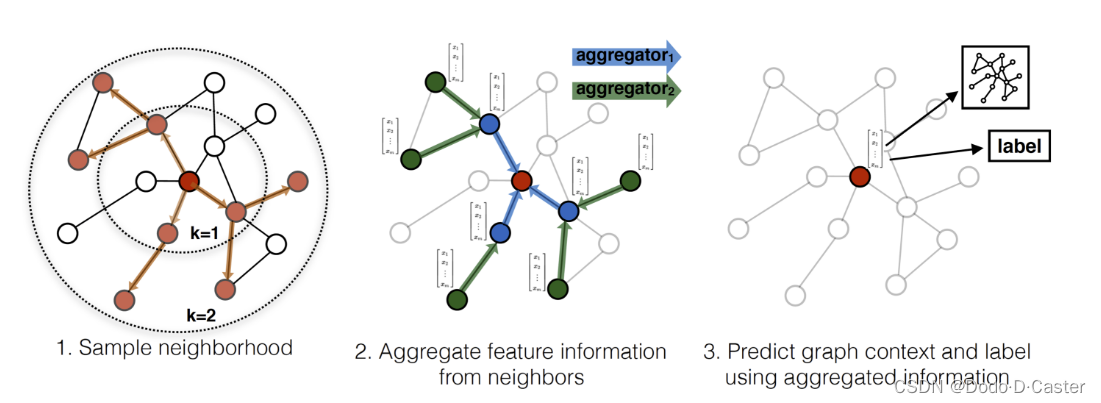
2 流程
2.1 算法1:前向传播
算法思想:在每一层,每个节点从自己的领域聚合n个邻居的信息,然后将聚合的信息和自身信息进行加权连接并乘上非线性激活函数。随着层的增加,节点能聚合到的邻居阶数也会增加。
算法的流程如下图所示:

- N ( v ) N(v) N(v)是从集合 { u ∈ V : ( u , v ) ∈ E } \{ u \in V : (u,v)\in \mathcal{E} \} {u∈V:(u,v)∈E}中用统一抽样的方法抽取固定个数的节点
总结一下,GraphSAGE的前向传播流程可以分为以下三步:
- Sample : 通过特定的方法从节点的邻居抽取固定个数的邻居
- Aggregate :通过特定的方法聚合抽取出来的邻居的信息
- Concat : 将聚合后的信息加上自身的信息从而更新节点的特征值
灵感来源:WL算法(计算图同构的算法,可以比较两个图的相似性),将WL算法种的哈希函数变成了可训练的神经网络聚合器
定理1:对于任何图,如果每个节点的特征不同(并且模型足够高维),算法 1 都存在一个参数设置使得它可以将该图中的聚类系数逼近到任意精度
2.2 采样器 Sampler
采样器的作用是选取固定个数的节点邻居,从而保持每个batch的大小固定。在本文中,作者固定大小为K,其中,对于不足邻居个数少于S的节点,则全部采样。
具体算法:
如果邻居个数小于采样数
- sample全部邻居
如果邻居个数大于采样数
- 如果总邻居的数量小于设定值(本论文中为21
- 则每次在 0~n-i 范围内抽取其中一个邻居 j ,然后把将该选择的位置 j 上的邻居变为 n-i-1 的位置上的邻居,i-1 后开始下一次选择
- 如果总邻居的数量大于设定值(本论文中为21
- 则设立一个select_add列表存储已选择的邻居下标信息,记录选择的邻居已经在select_add列表中存在,则重新随机sample一个邻居
2.3 聚合器 Aggregator
聚合器的作用是聚合邻居信息,在本文中会对无序的数组集合(也就是节点的邻居集合)进行操作。
理想情况下,聚合函数在可训练并且能够保持强表达能力的同时还要是对称的。聚合函数的对称性确保我们的神经网络模型可以被训练并应用于任意排序的节点邻域特征集。
作者总共设计了3种聚合邻居信息的方式,分别是:
Mean aggregator
这个方法将传统的transductive GCN的传播规则变成了inductive的方式,用以下的公式来代替聚合更新的过程(没有concatenation操作):
h v k ← σ ( W ⋅ M E A N ( { h v k − 1 } ∪ { h u k − 1 , ∀ u ∈ N ( v ) } ) ) h^k_v \leftarrow \sigma (W \cdot MEAN( \{ h_v^{k-1} \} \cup \{ h_u^{k-1} , \forall u \in \mathcal{N}(v) \} )) hvk←σ(W⋅MEAN({hvk−1}∪{huk−1,∀u∈N(v)}))
LSTM aggregator
LSTM相比Mean方法,有着更好的表达能力,但不对称。
由于LSTM需要输入是有序的,作者将节点的邻居顺序随机打乱作为输入。
Pooling aggregator
Pooling既有对称性又是可训练的,作者在本文种选择了最大池化的方法,也就是说,在聚合的时候,只选择计算值最大的邻居作为最终聚合的信息,其公式为:
A G G R E G A T E k p o o l = m a x ( { σ ( W p o o l h u i k + b ) , ∀ u i ∈ N ( v ) } ) AGGREGATE_k^{pool} = max(\{ \sigma (W_{pool} h_{u_i}^k +b), \forall u_i \in \mathcal{N}(v) \}) AGGREGATEkpool=max({σ(Wpoolhuik+b),∀ui∈N(v)})
其中,作者没有选择平均池的原因是作者发现平均池和最大池方法的差距不大。
2.4 更新 Concat
if not self.concat:output = tf.add_n([from_self, from_neighs])else:output = tf.concat([from_self, from_neighs], axis=1)
源码中的连接方式非常直接,将邻居信息连接到自身信息后面。
2.5 损失函数
无监督
J G ( z u ) = − l o g ( σ ( z u T z v ) ) − Q ⋅ E v n ∼ P n ( v ) l o g ( σ ( − z u T z v n ) ) J \mathcal{G} (z_u) = - log(\sigma (z_u^T z_v)) - Q \cdot E_{v_n \sim P_n(v)}log(\sigma (-z_u^T z_{v_n})) JG(zu)=−log(σ(zuTzv))−Q⋅Evn∼Pn(v)log(σ(−zuTzvn))
- v v v 是同时出现在节点 u 附件的固定随机游走长度的节点
- σ \sigma σ 是sigmoid函数
- P n P_n Pn 是负采样分布
- Q Q Q 是负采样数量
- z u z_u zu 是节点u的特征,由节点u的邻居的特征得到
该基于图的损失函数鼓励相近的节点拥有相似的表征,而相离的节点拥有不同的表征
有监督
交叉熵损失
3 实验
3.1 实验设置
4个baseline:
- 随机分类器 (Random)
- 基于特征的逻辑回归分类器(忽略图结构)(Raw features)
- DeepWalk算法(作为基于分解的代表方法)
- 结合原始特征和DeepWalk嵌入的方法 (DeepWalk + features)
超参数设置:
- 网络层数: K = 2 K=2 K=2里
- 理由:选择K=2相比k=1可以提高10-15%的准确率,但是训练时长会提高10-100倍(取决于采样个数)
- 采样个数: S 1 = 25 , S 2 = 10 S_1=25,S_2=10 S1=25,S2=10
- Batch size:512
三个实验,每个实验都会进行有监督和无监督训练进行对比
实验一:在一个大型引文数据集(Citation)上预测论文类别
- 数据集:Thomson Reuters Web of Science Core Collection中2000-2005的生物领域论文
- 图类型:无向图,进化图(数据会不断更新,也就是说,会产生很多unseen节点)
- 类别数:6
- 节点数:302424
- 平均度数:9.15
- 训练集:2000-2004年论文
- 测试集:2005年论文(30%为验证集,用于调整超参数)
实验二:预测不同Reddit帖子所属的社区
- 数据集:作者对2014.09发布的贴子建立了图数据集,节点标签为社区
- 图类型:进化图
- 节点(帖子)个数:232965
- 类别(社区)数:50
- 平均度数:492
- 训练集:前20天的数据
- 测试集:后20天的数据(30%为验证集)
实验三:总结多种PPI(生物蛋白质-蛋白质作用)图(每个图对应不同的人体组织),根据基因本体的细胞功能来为蛋白质的功能分类
- 数据集:Molecular Signatures Database
- 特征:positional gene sets, motif gene sets and immunological signatures
- 标签:gene ontology sets
- 类别数:121
- 节点数:2373
- 平均度数:28.8
- 图数量:20
- 测试集:2个图(另选2个图作为验证集)
3.2 实验结果
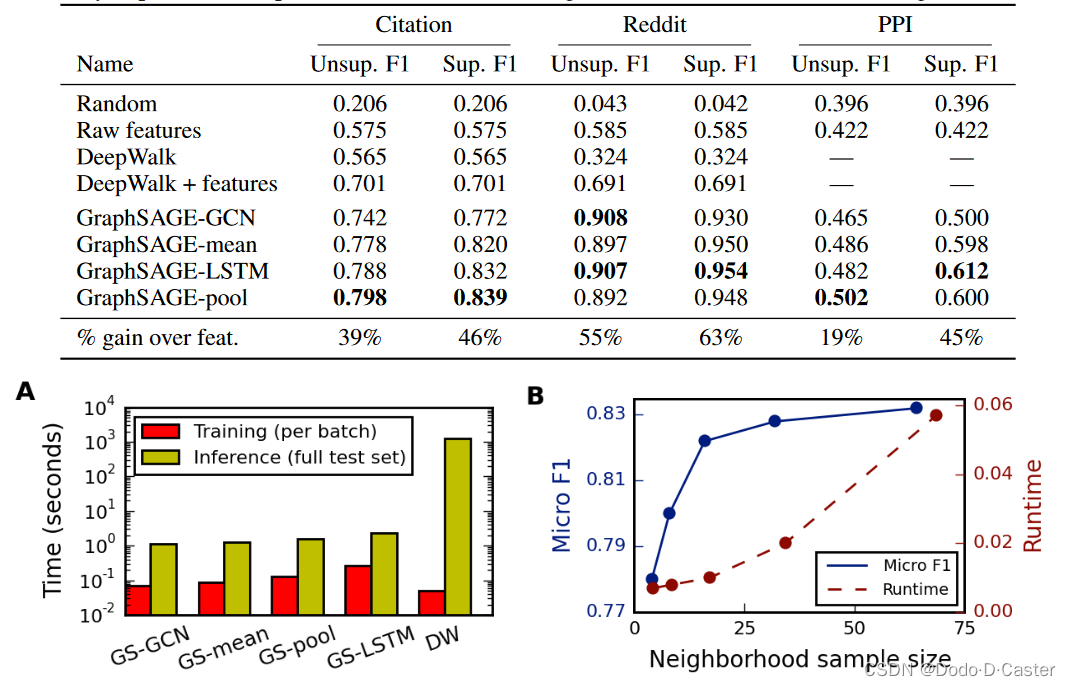
总体而言,基于LSTM和Pool的聚合器在平均表现和最佳表现次数上都是最好的。
4 问题
4.1 Mean aggregator
疑问来源:作者说Mean aggregator是对GCN的修改,将transductive变成了inductive?但是从源码上看,作者只是简单地对采样得到的邻居信息进行加权平均的操作。
解答:作者这里可能只是用到了卷积的思想,也就是AWX中的W卷积核。
4.2 采样器的设计
疑问来源:在运行GraphSAGE进行分类任务时,发现相同设置下的运行结果相差还是比较大的,在分类准确率上大约会有1%-5%的误差。这种分类不稳定性可能是由采样器的设计引起的。
解答:可以改变采样器的设计,比如按度来排序进行更有代表性的抽样,从而使结果更稳定。
4.3 聚合函数的对称性
疑问来源:作者谈到,理想的聚合函数需要在可训练、有强表达能力的同时具有对称性,这是因为聚合函数的对称性确保我们的神经网络模型可以被训练并应用于任意排序的节点邻域特征集。为什么对称性能够确保上述情况?
解答:对称性指的是对于输入的K个邻居,不同的顺序不会影响最终的结果。
4.4 图的改变
疑问来源:我们的理解为,GraphSAGE中每个batch存放了图中n个节点sample到的K个邻居信息,从而可以分为多个minibatch来进行聚合更新的计算。但是在看源码时,发现输入为整图的邻接矩阵,并通过邻接矩阵来得到每个节点的邻居。那么当图的结构改变时,或者加入不可见的结点时,是不是又要重新输入整图的邻接矩阵,还是说只需要输入新增节点及其邻居信息即可?
解答:接下来我们会看相关部分的源码来理解作者的做法。
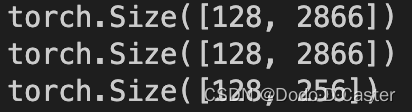
4.5 Concat维度的问题
疑问来源:由于作者在进行concat的时候直接进行连接的操作,那么每一次concat都会使原有数据的维度变为两倍,是如何进行降维的?
output = tf.concat([from_self, from_neighs], axis=1)
解答:
第一层:定义权重矩阵为128 by 1433*2。concat后的数据为n by 1433 *2,点乘后得到 128 by n的矩阵,达成降维。
enc1 = Encoder(features, 1433, 128, adj_lists, agg1, *gcn*=True, *cuda*=False)
第二层:定义权重矩阵为128 by 128,再次达到降维。
enc2 = Encoder(lambda nodes : enc1(nodes).t(), enc1.embed_dim, 128, adj_lists, agg2,base_model=enc1, gcn=True, cuda=False)
4.6 权值矩阵问题
疑问来源:看论文时,思路还是比较清晰的,总共有3个地方可以进行权重的训练:1 聚合器中的权重矩阵;2 连接后用于降维的权重矩阵;3 用于分类的权重矩阵。但是在看源码的时候,对GraphSAGE训练了哪些权重矩阵产生了疑惑
解答:对于MEAN方法,除去用于分类的权重矩阵,总共有2个权重矩阵,分别是2层神经网络的GCN公式权重矩阵,而对于其他聚合方法,聚合器的权重矩阵只有一个,两层神经网络又分别各有一个用于降维的连接权重矩阵。

4.7 GraphSAGE 和 GCN的本质区别
疑问来源:来自于GCN作者的留言(如下
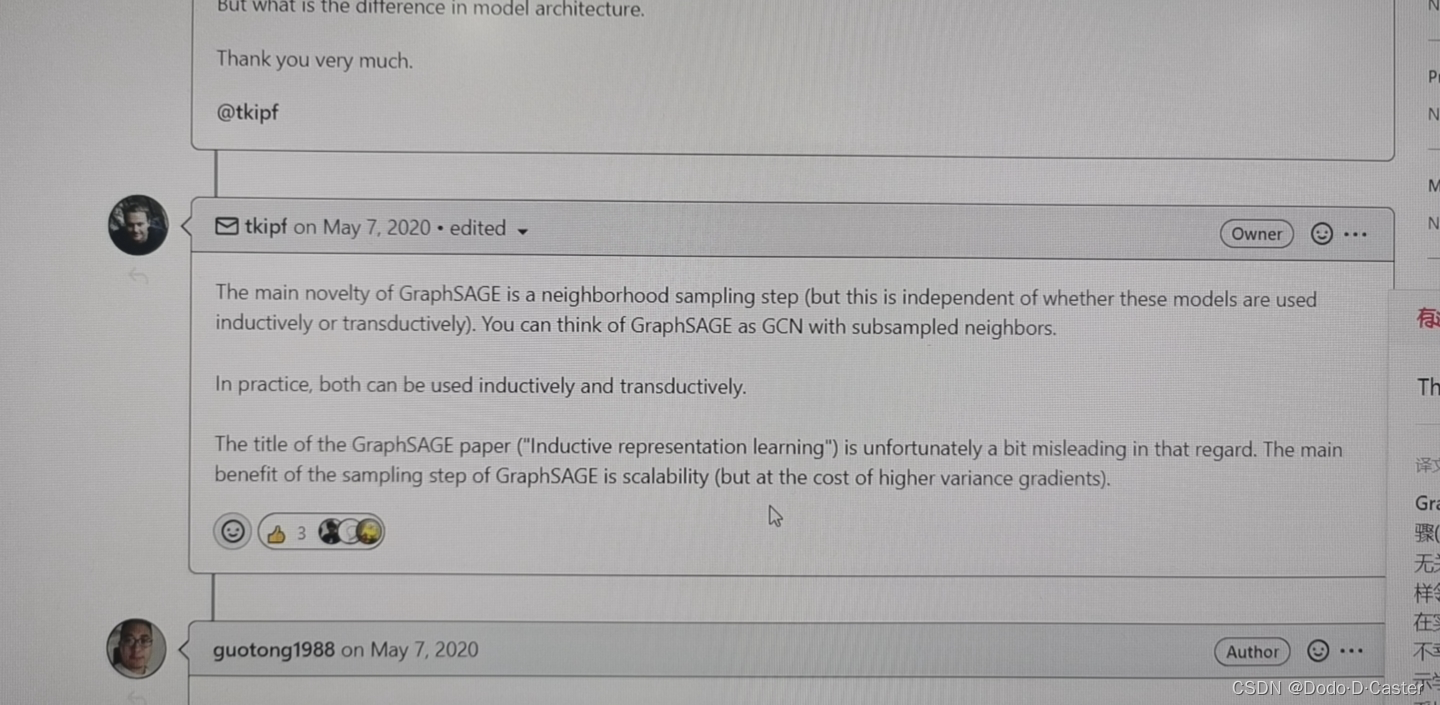
解答:说GCN和GraphSAGE最大的区别在于采样的方式其实是没有问题的。以minibatch为例,GCN可以在每个batch中存放含有固定个数节点的子图的邻接矩阵,这样同样可以保证batch size的一致,但采样得到的邻居个数在这种情况下是不固定的,在子图中有多有少。而GraphSAGE则尽量固定了采样的邻居个数,对于邻居个数大于K的节点,则采样K个邻居。按上述的思想,GraphSAGE同样可以推广到inductive,让新增的unseen节点加入所在的含有n个节点的子图进行计算,同样可以得到新增节点的特征。
但是,我认为其本质区别还是训练的对象不同,GCN是为整个图上所有节点生成嵌入,也就是训练得到的函数是对全图而言的。而GraphSAGE则是为单个节点生成嵌入,训练得到的函数是对单个节点而言,聚合邻居并连接自身信息的函数。
这篇关于Inductive Representation Learning on Large Graphs 论文/GraphSAGE学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






